Como usar a instrução proc glmselect no sas
Você pode usar a instrução PROC GLMSELECT no SAS para selecionar o melhor modelo de regressão com base em uma lista de possíveis variáveis preditoras.
O exemplo a seguir mostra como usar essa afirmação na prática.
Exemplo: como usar PROC GLMSELECT em SAS para seleção de modelo
Suponha que queiramos ajustar um modelo de regressão linear múltipla que usa (1) o número de horas gastas estudando, (2) o número de exames preparatórios realizados e (3) o gênero para prever a nota final dos alunos no exame.
Primeiro, usaremos o seguinte código para criar um conjunto de dados contendo essas informações para 20 alunos:
/*create dataset*/ data exam_data; input hours prep_exams gender $score; datalines ; 1 1 0 76 2 3 1 78 2 3 0 85 4 5 0 88 2 2 0 72 1 2 1 69 5 1 1 94 4 1 0 94 2 0 1 88 4 3 0 92 4 4 1 90 3 3 1 75 6 2 1 96 5 4 0 90 3 4 0 82 4 4 1 85 6 5 1 99 2 1 0 83 1 0 1 62 2 1 0 76 ; run ; /*view dataset*/ proc print data =exam_data;
A seguir, usaremos a instrução PROC GLMSELECT para identificar o subconjunto de variáveis preditoras que produz o melhor modelo de regressão:
/*perform model selection*/
proc glmselect data =exam_data;
classgender ;
model score = hours prep_exams gender;
run ;
Nota : incluímos gênero na declaração de classe porque é uma variável categórica.
O primeiro grupo de tabelas na saída mostra uma visão geral do procedimento GLMSELECT:
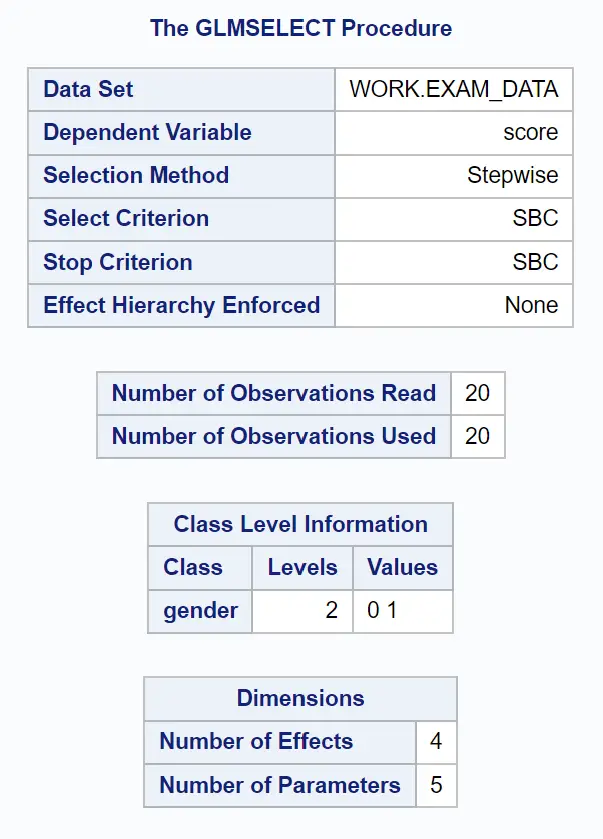
Podemos observar que o critério utilizado para parar de adicionar ou retirar variáveis do modelo foi o SBC , que é o critério de informação de Schwarz , às vezes chamado de critério de informação bayesiano .
Essencialmente, a instrução PROC GLMSELECT continua adicionando ou removendo variáveis do modelo até encontrar o modelo com o valor SBC mais baixo, que é considerado o “melhor” modelo.
O seguinte grupo de tabelas mostra como terminou a seleção passo a passo:
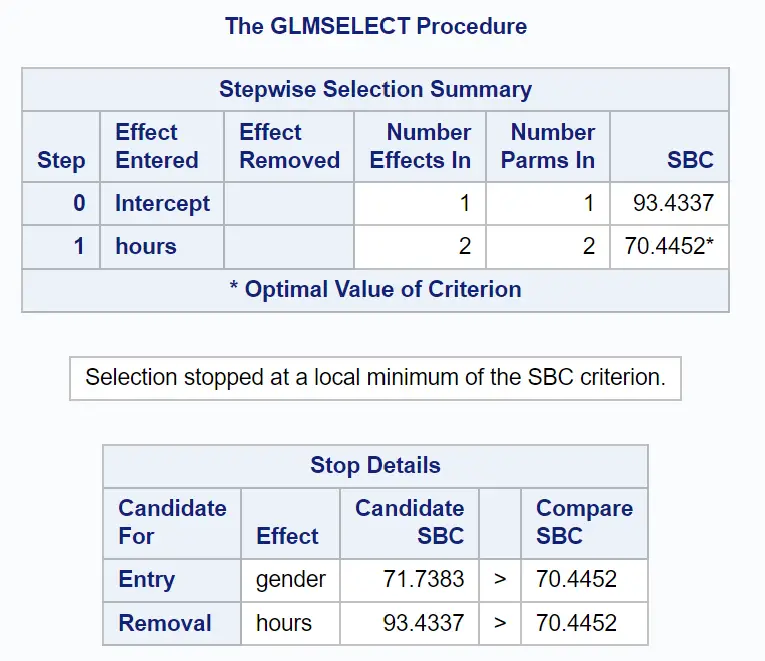
Podemos ver que um modelo apenas com o termo original teve um valor SBC de 93,4337 .
Ao adicionar horas como variável preditora no modelo, o valor SBC caiu para 70,4452 .
A melhor maneira de melhorar o modelo foi adicionar o gênero como variável preditora, mas isso na verdade aumentou o valor do SBC para 71,7383.
Assim, o modelo final inclui apenas o termo de interceptação e os tempos estudados.
A última parte do resultado mostra o resumo deste modelo de regressão ajustado:
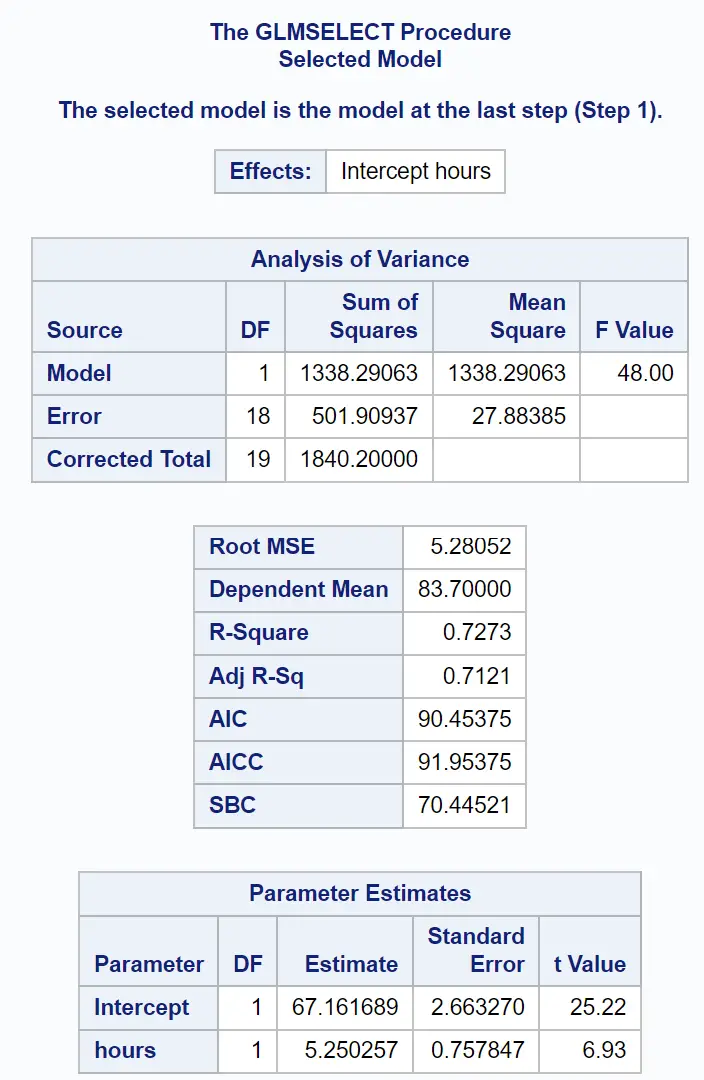
Podemos usar os valores da tabela Estimativas de Parâmetros para escrever o modelo de regressão ajustado:
Nota do exame = 67,161689 + 5,250257 (horas estudadas)
Também podemos ver várias métricas que nos dizem quão bem este modelo se ajusta aos dados:
O valor R-Square nos indica a porcentagem de variação nas notas dos exames que pode ser explicada pelo número de horas estudadas e pelo número de exames preparatórios realizados.
Nesse caso, 72,73% da variação nas notas dos exames pode ser explicada pela quantidade de horas estudadas e pela quantidade de exames preparatórios realizados.
O valor Root MSE também é útil saber. Isto representa a distância média entre os valores observados e a linha de regressão.
Neste modelo de regressão, os valores observados desviam-se em média 5,28052 unidades da reta de regressão.
Nota : Consulte a documentação do SAS para obter uma lista completa de possíveis argumentos que você pode usar com PROC GLMSELECT .
Recursos adicionais
Os tutoriais a seguir explicam como executar outras tarefas comuns no SAS:
Como realizar regressão linear simples no SAS
Como realizar regressão linear múltipla no SAS
Como realizar regressão polinomial no SAS
Como realizar regressão logística no SAS
About Author
Dr. benjamim anderson
Olá, sou Benjamin, um professor aposentado de estatística que se tornou professor dedicado na Statorials. Com vasta experiência e conhecimento na área de estatística, estou empenhado em compartilhar meu conhecimento para capacitar os alunos por meio de Statorials. Saber mais