Ajuste de curva em r (com exemplos)
Muitas vezes você pode querer encontrar a equação que melhor se ajusta a uma curva de R.
O exemplo passo a passo a seguir explica como ajustar curvas aos dados em R usando a função poly() e como determinar qual curva melhor se ajusta aos dados.
Etapa 1: criar e visualizar dados
Vamos começar criando um conjunto de dados falso e, em seguida, criar um gráfico de dispersão para visualizar os dados:
#create data frame df <- data. frame (x=1:15, y=c(3, 14, 23, 25, 23, 15, 9, 5, 9, 13, 17, 24, 32, 36, 46)) #create a scatterplot of x vs. y plot(df$x, df$y, pch= 19 , xlab=' x ', ylab=' y ')
Etapa 2: ajustar múltiplas curvas
Vamos então ajustar vários modelos de regressão polinomial aos dados e visualizar a curva de cada modelo no mesmo gráfico:
#fit polynomial regression models up to degree 5 fit1 <- lm(y~x, data=df) fit2 <- lm(y~poly(x,2,raw= TRUE ), data=df) fit3 <- lm(y~poly(x,3,raw= TRUE ), data=df) fit4 <- lm(y~poly(x,4,raw= TRUE ), data=df) fit5 <- lm(y~poly(x,5,raw= TRUE ), data=df) #create a scatterplot of x vs. y plot(df$x, df$y, pch=19, xlab=' x ', ylab=' y ') #define x-axis values x_axis <- seq(1, 15, length= 15 ) #add curve of each model to plot lines(x_axis, predict(fit1, data. frame (x=x_axis)), col=' green ') lines(x_axis, predict(fit2, data. frame (x=x_axis)), col=' red ') lines(x_axis, predict(fit3, data. frame (x=x_axis)), col=' purple ') lines(x_axis, predict(fit4, data. frame (x=x_axis)), col=' blue ') lines(x_axis, predict(fit5, data. frame (x=x_axis)), col=' orange ')
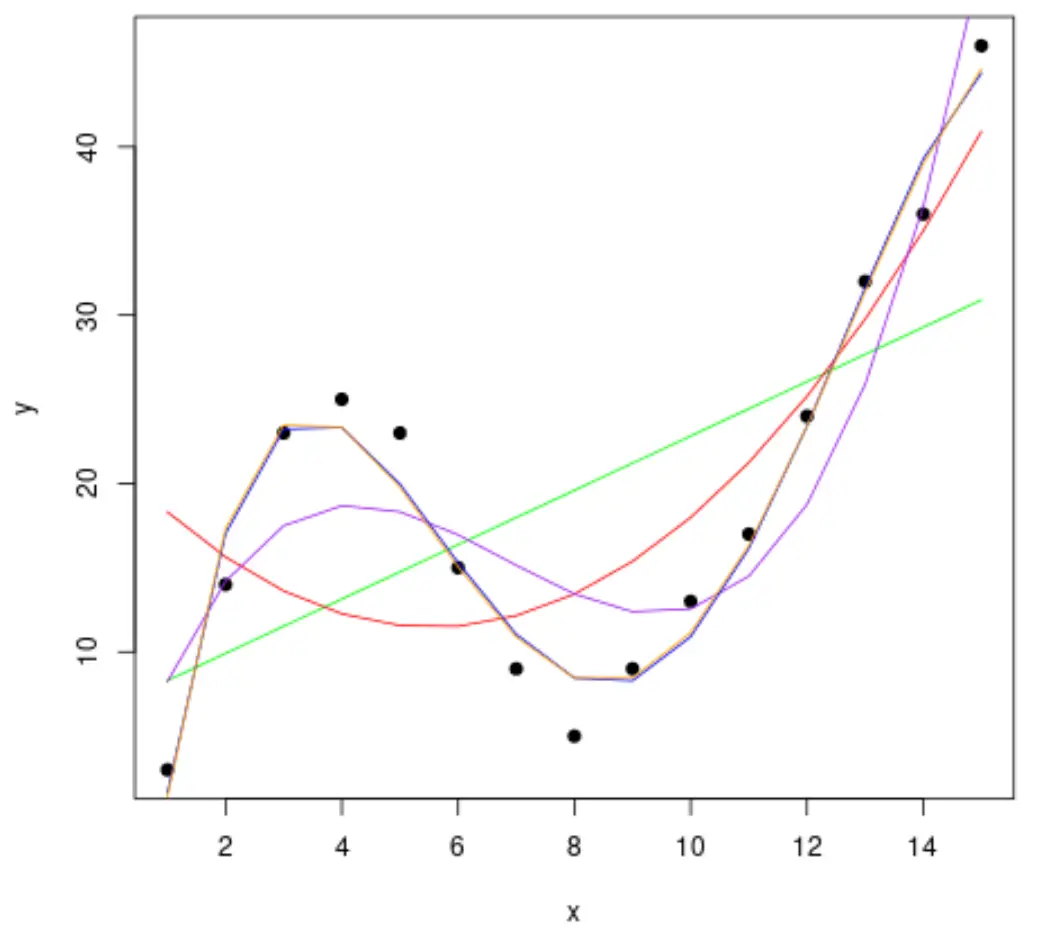
Para determinar qual curva melhor se ajusta aos dados, podemos observar o R quadrado ajustado de cada modelo.
Este valor nos diz a porcentagem de variação na variável resposta que pode ser explicada pela(s) variável(ões) preditora(s) no modelo, ajustada pelo número de variáveis preditoras.
#calculated adjusted R-squared of each model summary(fit1)$adj. r . squared summary(fit2)$adj. r . squared summary(fit3)$adj. r . squared summary(fit4)$adj. r . squared summary(fit5)$adj. r . squared [1] 0.3144819 [1] 0.5186706 [1] 0.7842864 [1] 0.9590276 [1] 0.9549709
Pelo resultado, podemos perceber que o modelo com maior R-quadrado ajustado é o polinômio de quarto grau, que possui um R-quadrado ajustado de 0,959 .
Passo 3: Visualize a curva final
Finalmente, podemos criar um gráfico de dispersão com a curva do modelo polinomial de quarto grau:
#create a scatterplot of x vs. y plot(df$x, df$y, pch=19, xlab=' x ', ylab=' y ') #define x-axis values x_axis <- seq(1, 15, length= 15 ) #add curve of fourth-degree polynomial model lines(x_axis, predict(fit4, data. frame (x=x_axis)), col=' blue ')
Também podemos obter a equação desta linha usando a função summary() :
summary(fit4)
Call:
lm(formula = y ~ poly(x, 4, raw = TRUE), data = df)
Residuals:
Min 1Q Median 3Q Max
-3.4490 -1.1732 0.6023 1.4899 3.0351
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -26.51615 4.94555 -5.362 0.000318 ***
poly(x, 4, raw = TRUE)1 35.82311 3.98204 8.996 4.15e-06 ***
poly(x, 4, raw = TRUE)2 -8.36486 0.96791 -8.642 5.95e-06 ***
poly(x, 4, raw = TRUE)3 0.70812 0.08954 7.908 1.30e-05 ***
poly(x, 4, raw = TRUE)4 -0.01924 0.00278 -6.922 4.08e-05 ***
---
Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.424 on 10 degrees of freedom
Multiple R-squared: 0.9707, Adjusted R-squared: 0.959
F-statistic: 82.92 on 4 and 10 DF, p-value: 1.257e-07
A equação da curva é a seguinte:
y = -0,0192x 4 + 0,7081x 3 – 8,3649x 2 + 35,823x – 26,516
Podemos usar esta equação para prever o valor da variável de resposta com base nas variáveis preditoras do modelo. Por exemplo, se x = 4, então preveríamos que y = 23,34 :
y = -0,0192(4) 4 + 0,7081(4) 3 – 8,3649(4) 2 + 35,823(4) – 26,516 = 23,34
Recursos adicionais
Uma introdução à regressão polinomial
Regressão Polinomial em R (Passo a Passo)
Como usar a função seq em R
About Author
Dr. benjamim anderson
Olá, sou Benjamin, um professor aposentado de estatística que se tornou professor dedicado na Statorials. Com vasta experiência e conhecimento na área de estatística, estou empenhado em compartilhar meu conhecimento para capacitar os alunos por meio de Statorials. Saber mais