Uma introdução às árvores de classificação e regressão
Quando a relação entre um conjunto de variáveis preditoras e uma variável de resposta é linear, métodos como a regressão linear múltipla podem produzir modelos preditivos precisos.
No entanto, quando a relação entre um conjunto de preditores e uma resposta é altamente não linear e complexa, então os métodos não lineares podem ter melhor desempenho.
Um exemplo de método não linear são as árvores de classificação e regressão , geralmente abreviadas como CART .
Como o nome sugere, os modelos CART usam um conjunto de variáveis preditoras para criar árvores de decisão que preveem o valor de uma variável de resposta.
Por exemplo, suponha que temos um conjunto de dados contendo as variáveis preditoras Anos Jogados e Média de Home Runs e a variável de resposta Salário Anual para centenas de jogadores profissionais de beisebol.
Esta é a aparência de uma árvore de regressão para este conjunto de dados:
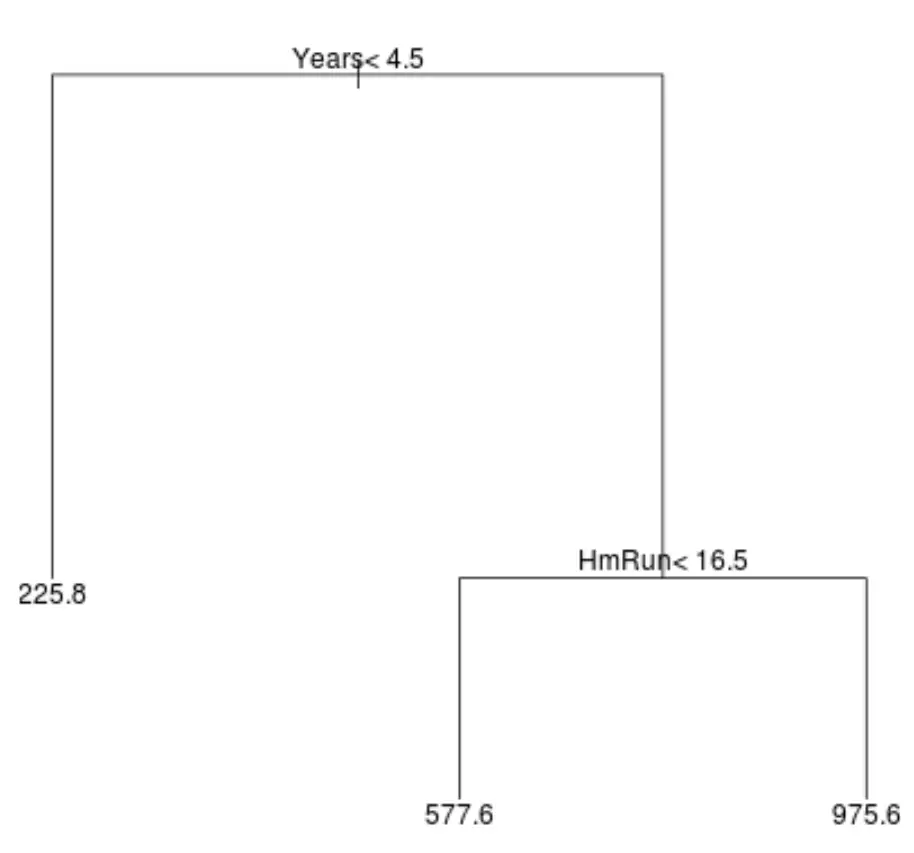
A maneira de interpretar a árvore é a seguinte:
- Jogadores que jogaram menos de 4,5 anos têm um salário projetado de US$ 225,8 mil.
- Jogadores que jogaram mais de 4,5 anos ou mais e menos de 16,5 home runs em média têm um salário projetado de US$ 577,6 mil.
- Jogadores com 4,5 anos ou mais de experiência de jogo e uma média de 16,5 home runs ou mais têm um salário esperado de $ 975,6 mil.
Os resultados deste modelo deveriam fazer sentido intuitivamente: jogadores com mais anos de experiência e mais home runs médios tendem a ganhar salários mais elevados.
Podemos então usar este modelo para prever o salário de um novo jogador.
Por exemplo, digamos que um determinado jogador jogou 8 anos e tem uma média de 10 home runs por ano. De acordo com nosso modelo, preveríamos que esse jogador teria um salário anual de US$ 577,6 mil.
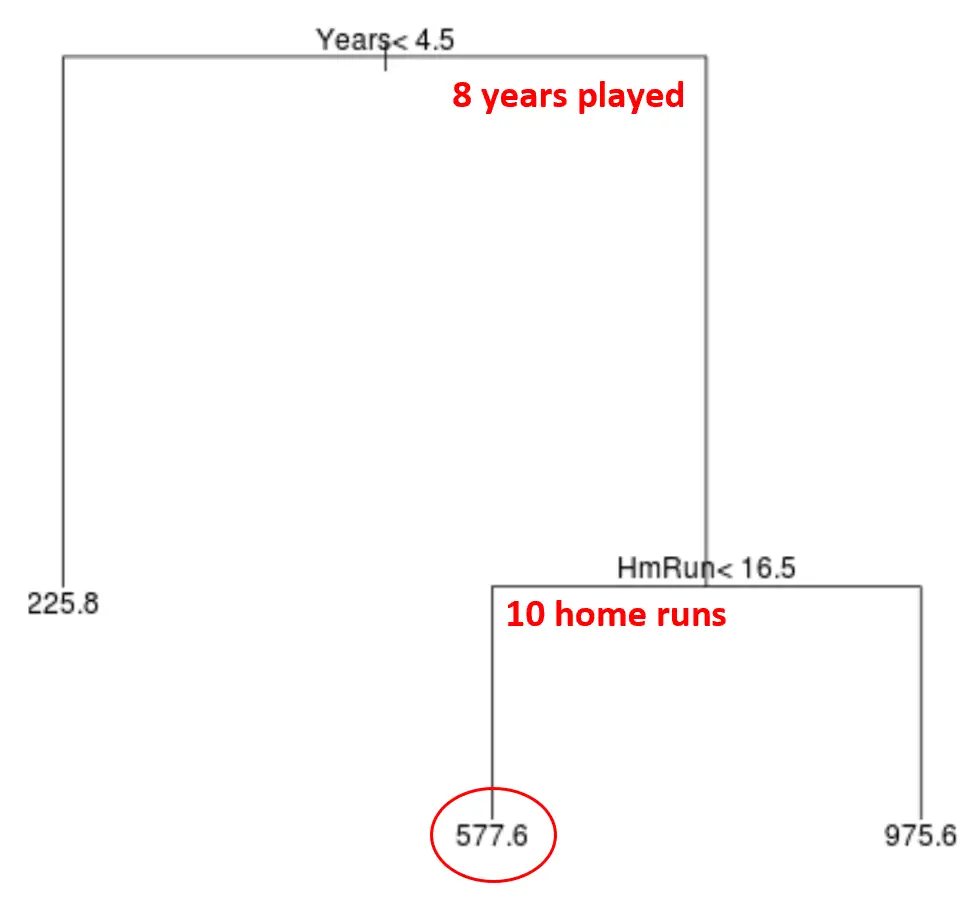
Algumas observações sobre a árvore:
- A primeira variável preditiva localizada no topo da árvore é a mais importante, ou seja, aquela que mais influencia na previsão do valor da variável resposta. Neste caso, os anos jogados preveem melhor o salário do que a média dos circuitos .
- As regiões na parte inferior da árvore são chamadas de nós folha . Esta árvore específica possui três nós terminais.
Etapas para criar modelos CART
Podemos usar as seguintes etapas para criar um modelo CART para um determinado conjunto de dados:
Etapa 1: use a divisão binária recursiva para desenvolver uma grande árvore nos dados de treinamento.
Primeiro, usamos um algoritmo ganancioso chamado divisão binária recursiva para desenvolver uma árvore de regressão usando o seguinte método:
- Considere todas as variáveis preditoras X 1 , X 2 , … , erro padrão residual) as mais baixas. .
- Para árvores de classificação, escolhemos o preditor e o ponto de corte de forma que a árvore resultante tenha a menor taxa de erro de classificação.
- Repita esse processo, parando apenas quando cada nó terminal tiver menos que um determinado número mínimo de observações.
Este algoritmo é ganancioso porque em cada etapa do processo de construção da árvore ele determina a melhor divisão a ser feita com base apenas naquela etapa, em vez de olhar para o futuro e escolher uma divisão que levará a uma árvore global melhor em um estágio futuro.
Passo 2: Aplicar poda de complexidade de custo à árvore grande para obter uma sequência das melhores árvores, com base em α.
Depois de termos crescido a árvore grande, precisamos podá- la usando um método conhecido como poda complexa, que funciona da seguinte forma:
- Para cada árvore possível com T nós terminais, encontre a árvore que minimiza RSS + α|T|.
- Observe que quando aumentamos o valor de α, as árvores com mais nós terminais são penalizadas. Isso garante que a árvore não se torne muito complexa.
Este processo resulta em uma sequência das melhores árvores para cada valor de α.
Etapa 3: Use a validação cruzada k-fold para escolher α.
Uma vez encontrada a melhor árvore para cada valor de α, podemos aplicar a validação cruzada k-fold para escolher o valor de α que minimize o erro de teste.
Passo 4: Escolha o modelo final.
Por fim, escolhemos o modelo final como aquele que corresponde ao valor escolhido de α.
Vantagens e desvantagens dos modelos CART
Os modelos CART oferecem as seguintes vantagens :
- Eles são fáceis de interpretar.
- Eles são fáceis de explicar.
- Eles são fáceis de visualizar.
- Eles podem ser aplicados tanto a problemas de regressão quanto a problemas de classificação .
No entanto, os modelos CART apresentam as seguintes desvantagens:
- Eles tendem a não ter tanta precisão preditiva quanto outros algoritmos de aprendizado de máquina não linear. No entanto, ao agrupar muitas árvores de decisão com métodos como ensacamento, reforço e florestas aleatórias, sua precisão preditiva pode ser melhorada.
Relacionado: Como ajustar árvores de classificação e regressão em R
About Author
Dr. benjamim anderson
Olá, sou Benjamin, um professor aposentado de estatística que se tornou professor dedicado na Statorials. Com vasta experiência e conhecimento na área de estatística, estou empenhado em compartilhar meu conhecimento para capacitar os alunos por meio de Statorials. Saber mais