Binning de frequência igual em python
Em estatística, agrupamento é o processo de colocar valores numéricos em grupos .
A forma mais comum de clustering é conhecida como clustering de largura igual , em que dividimos um conjunto de dados em k grupos de largura igual.
Uma forma de agrupamento menos comumente usada é conhecida como agrupamento de frequência igual , na qual dividimos um conjunto de dados em k grupos, todos com igual número de frequências.
Este tutorial explica como realizar clustering de frequência igual em python.
Binning de frequência igual em Python
Suponha que temos um conjunto de dados contendo 100 valores:
import numpy as np import matplotlib.pyplot as plt #create data np.random.seed(1) data = np.random.randn(100) #view first 5 values data[:5] array([ 1.62434536, -0.61175641, -0.52817175, -1.07296862, 0.86540763])
Agrupamento de largura igual:
Se criarmos um histograma para exibir esses valores, o Python usará como padrão o agrupamento de largura igual:
#create histogram with equal-width bins n, bins, patches = plt.hist(data, edgecolor='black') plt.show() #display bin boundaries and frequency per bin bins, n (array([-2.3015387 , -1.85282729, -1.40411588, -0.95540447, -0.50669306, -0.05798165, 0.39072977, 0.83944118, 1.28815259, 1.736864, 2.18557541]), array([ 3., 1., 6., 17., 19., 20., 14., 12., 5., 3.]))
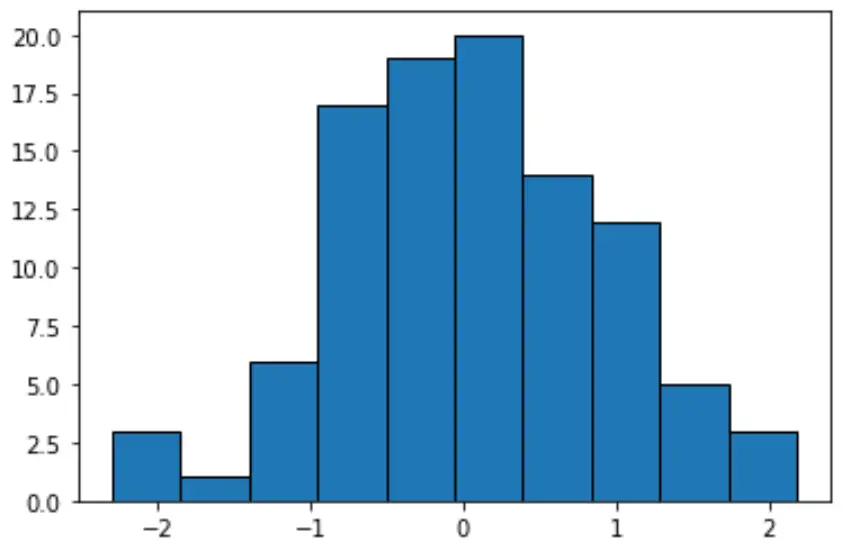
Cada grupo tem uma largura igual de aproximadamente 0,4487, mas cada grupo não contém uma quantidade igual de observações. Por exemplo:
- O primeiro compartimento se estende de -2,3015387 a -1,8528279 e contém 3 observações.
- O segundo compartimento se estende de -1,8528279 a -1,40411588 e contém 1 observação.
- O terceiro compartimento se estende de -1,40411588 a -0,95540447 e contém 6 observações.
E assim por diante.
Agrupamento de frequência igual:
Para criar intervalos contendo um número igual de observações, podemos usar a seguinte função:
#define function to calculate equal-frequency bins def equalObs(x, nbin): nlen = len(x) return np.interp(np.linspace(0, nlen, nbin + 1), np.arange(nlen), np.sort(x)) #create histogram with equal-frequency bins n, bins, patches = plt.hist(data, equalObs(data, 10), edgecolor='black') plt.show() #display bin boundaries and frequency per bin bins, n (array([-2.3015387 , -0.93576943, -0.67124613, -0.37528495, -0.20889423, 0.07734007, 0.2344157, 0.51292982, 0.86540763, 1.19891788, 2.18557541]), array([10., 10., 10., 10., 10., 10., 10., 10., 10., 10.]))
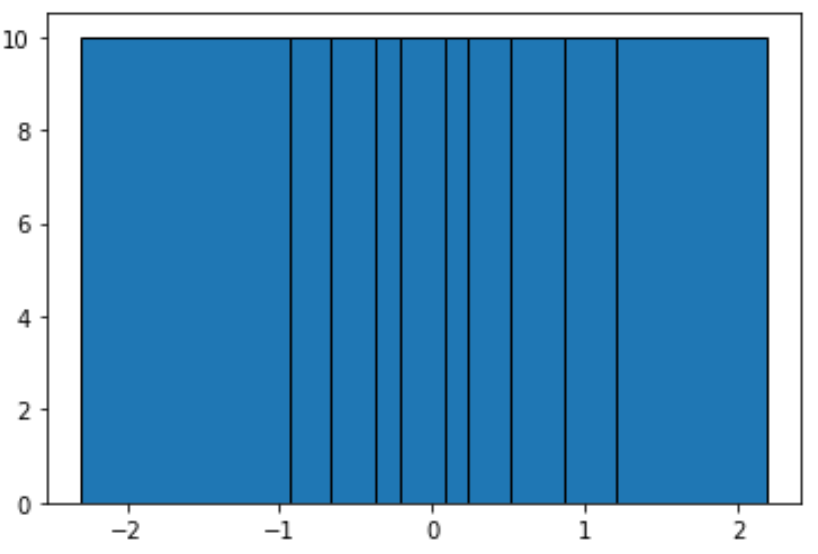
Cada grupo não tem largura igual, mas cada grupo contém uma quantidade igual de observações. Por exemplo:
- O primeiro compartimento se estende de -2,3015387 a -0,93576943 e contém 10 observações.
- O segundo compartimento se estende de -0,93576943 a -0,67124613 e contém 10 observações.
- O terceiro compartimento se estende de -0,67124613 a -0,37528495 e contém 10 observações.
E assim por diante.
Podemos ver no histograma que cada caixa claramente não tem a mesma largura, mas cada caixa contém o mesmo número de observações, o que é confirmado pelo fato de que a altura de cada caixa é igual.
About Author
Dr. benjamim anderson
Olá, sou Benjamin, um professor aposentado de estatística que se tornou professor dedicado na Statorials. Com vasta experiência e conhecimento na área de estatística, estou empenhado em compartilhar meu conhecimento para capacitar os alunos por meio de Statorials. Saber mais