Como usar proc cluster em sas (com exemplo)
Clustering é uma técnica de aprendizado de máquina que tenta encontrar grupos de observações dentro de um conjunto de dados.
O objetivo é encontrar clusters tais que as observações dentro de cada cluster sejam bastante semelhantes entre si, enquanto as observações em diferentes clusters sejam bastante diferentes umas das outras.
A maneira mais fácil de fazer clustering no SAS é usar PROC CLUSTER .
O exemplo a seguir mostra como usar PROC CLUSTER na prática.
Exemplo: como usar PROC CLUSTER em SAS
Digamos que temos o seguinte conjunto de dados contendo informações sobre pontos, assistências e rebotes de 20 jogadores de basquete diferentes:
/*create dataset*/
data my_data;
input points assists rebounds;
datalines ;
18 3 15
20 3 14
19 4 14
14 5 10
14 4 8
15 7 14
20 8 13
28 7 9
30 6 5
31 9 4
35 12 11
33 14 6
29 9 5
25 9 5
25 4 3
27 3 8
29 4 12
30 12 7
19 5 6
23 11 5
;
run ;
/*view dataset*/
proc print data =my_data;
Digamos que queremos fazer alguns agrupamentos para tentar identificar “grupos” de jogadores com estatísticas semelhantes entre si.
O código a seguir mostra como usar PROC CLUSTER no SAS para realizar clustering:
/*perform clustering using points, assists and rebounds variables*/
proc cluster data =my_data method =average;
var points assists rebounds;
run ;
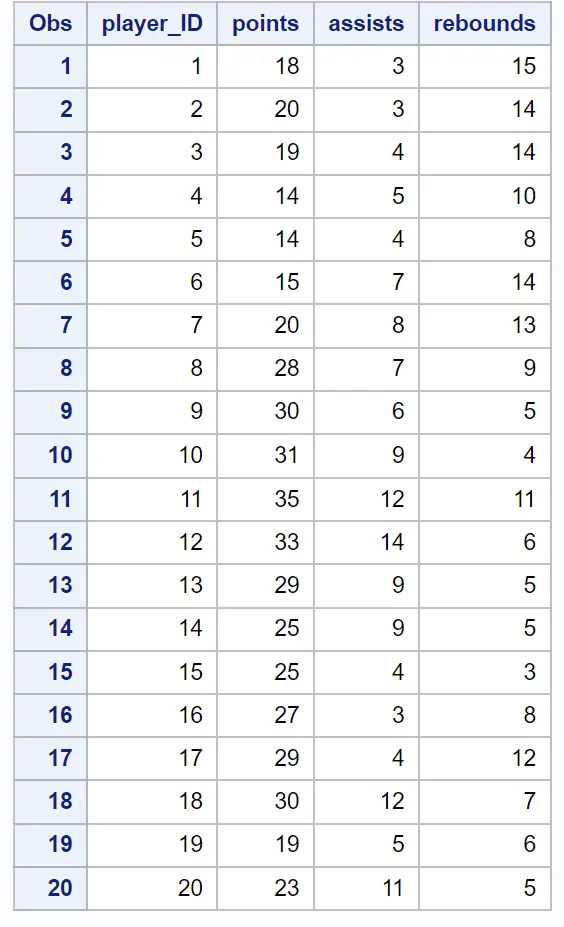
As primeiras tabelas do resultado fornecem informações sobre como foi realizado o agrupamento:
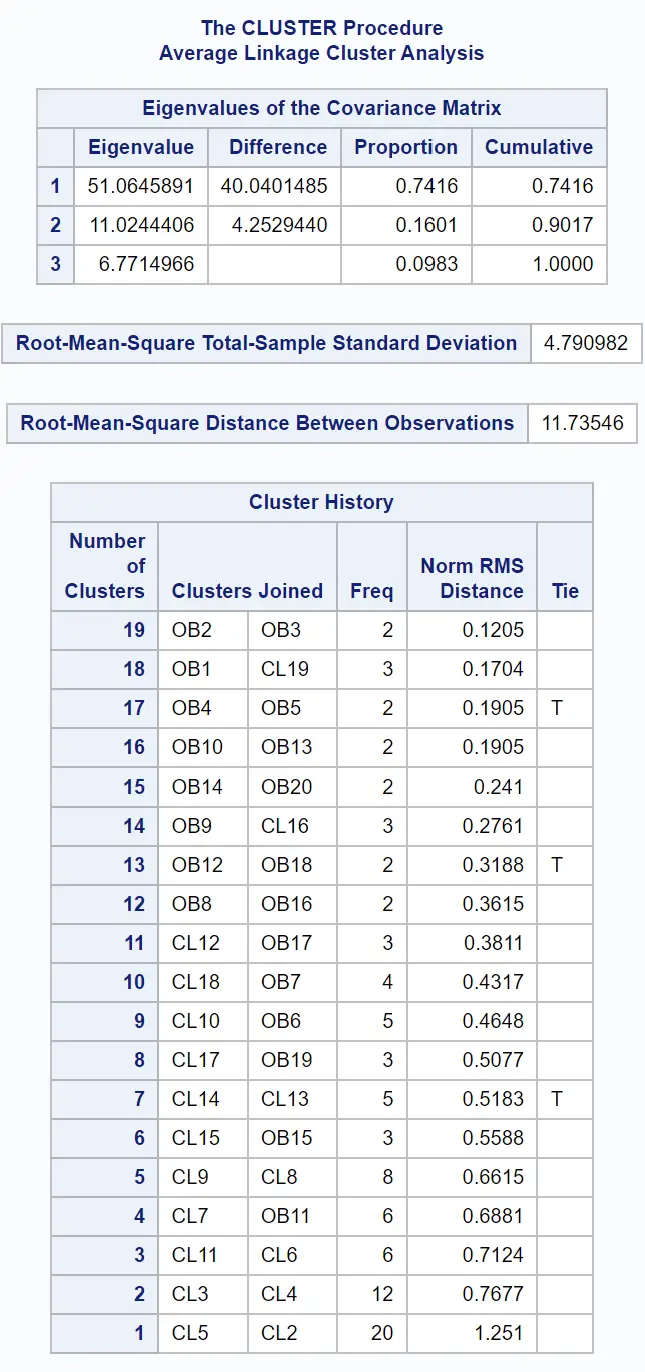
Um dendograma também é produzido para que possamos inspecionar visualmente a semelhança entre as observações no conjunto de dados:
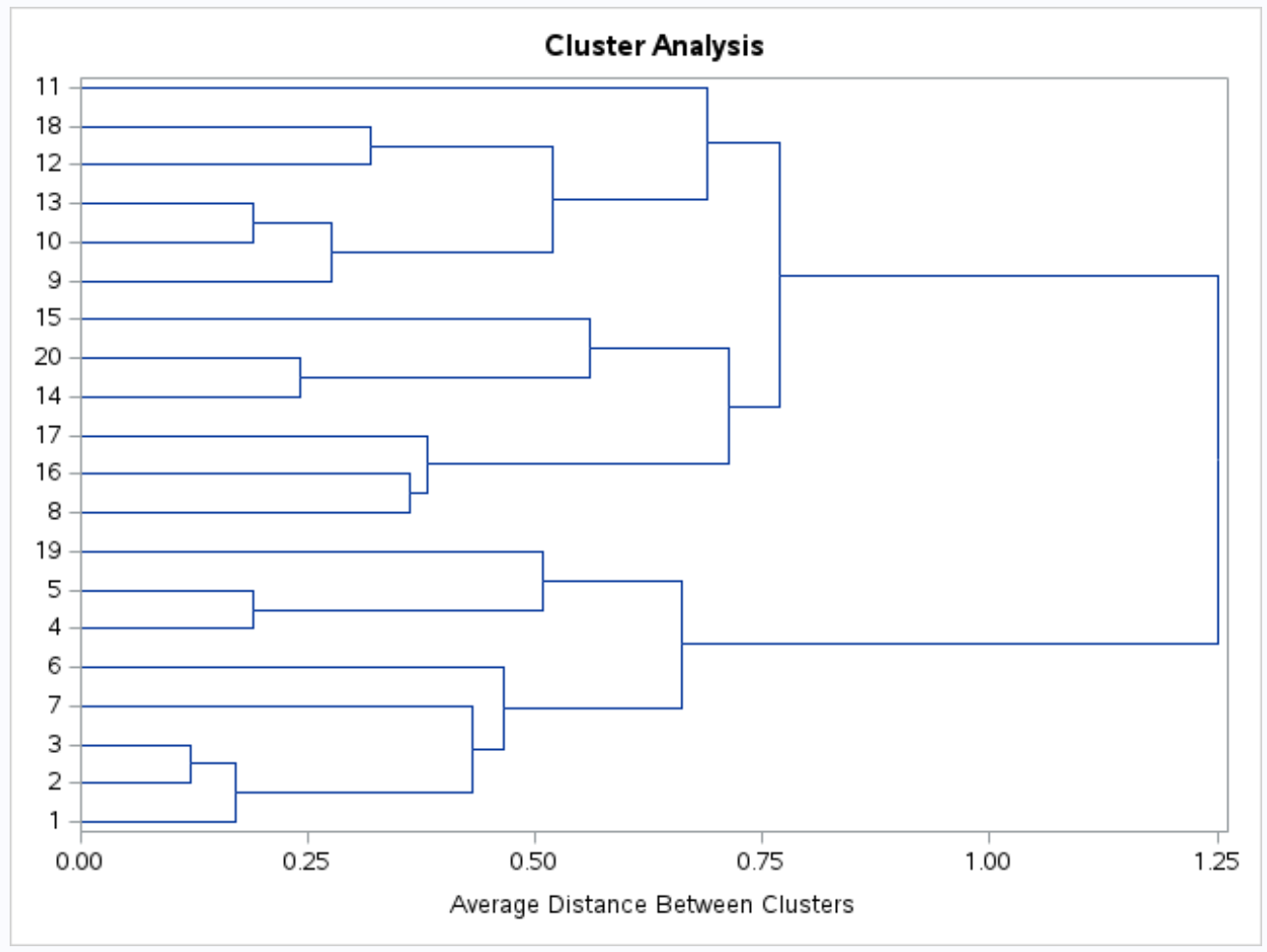
O eixo y mostra observações individuais e o eixo x mostra a distância média entre os clusters.
Olhando para este dendograma, parece que as observações se enquadram naturalmente em três grupos:
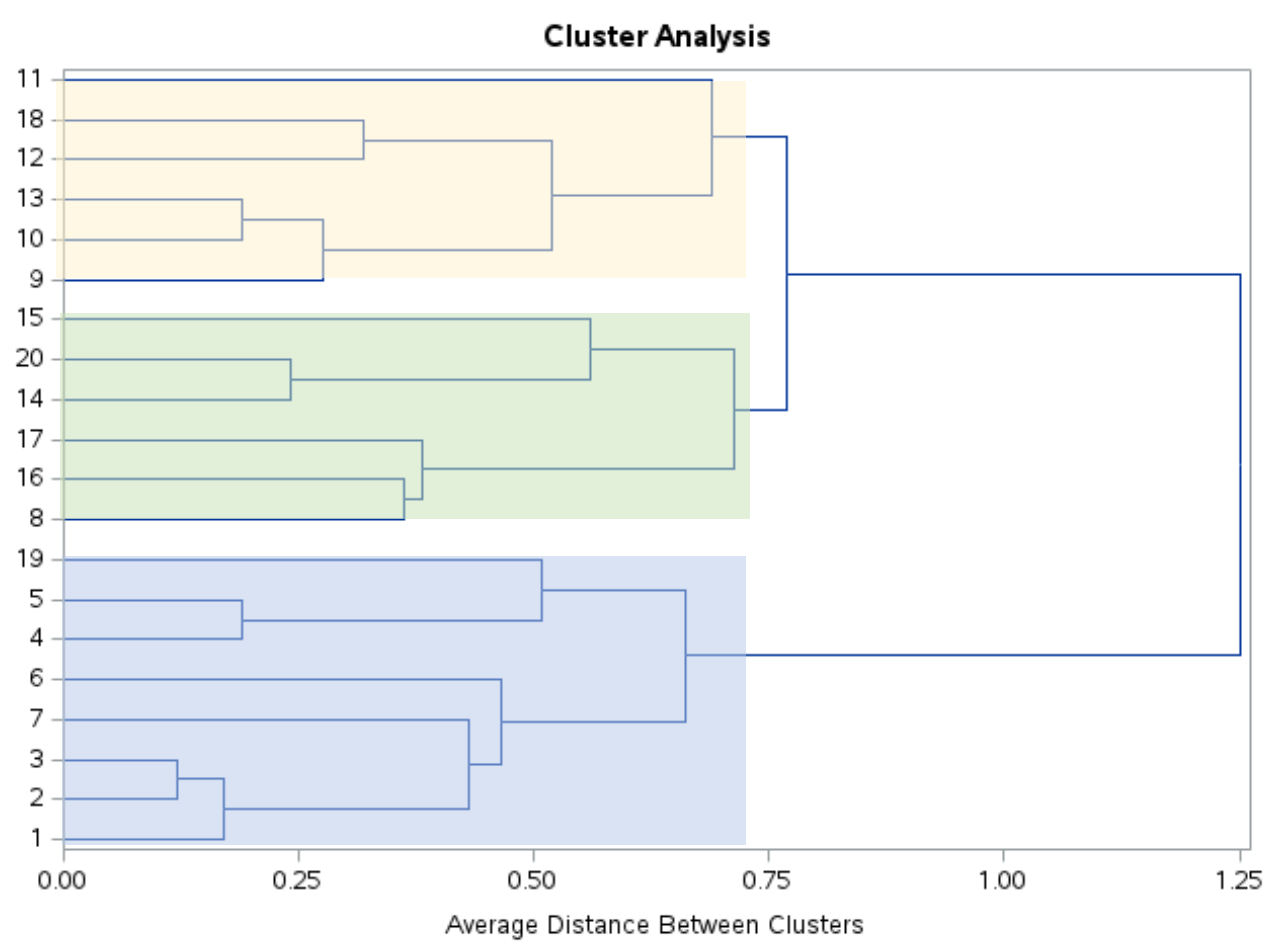
Podemos então usar a instrução PROC TREE com ncl=3 para dizer ao SAS para atribuir cada observação no conjunto de dados original a um dos três clusters:
/*assign each observation to one of three clusters*/
proc tree data =clustd noprint ncl =3 out =clusts;
copy points assists rebounds;
id player_ID;
run ;
proc sort ;
by cluster;
run ;
/*view cluster assignments*/
proc print data = clusters;
id player_ID;
run ;
O conjunto de dados resultante mostra cada uma das observações originais junto com o cluster ao qual pertencem:
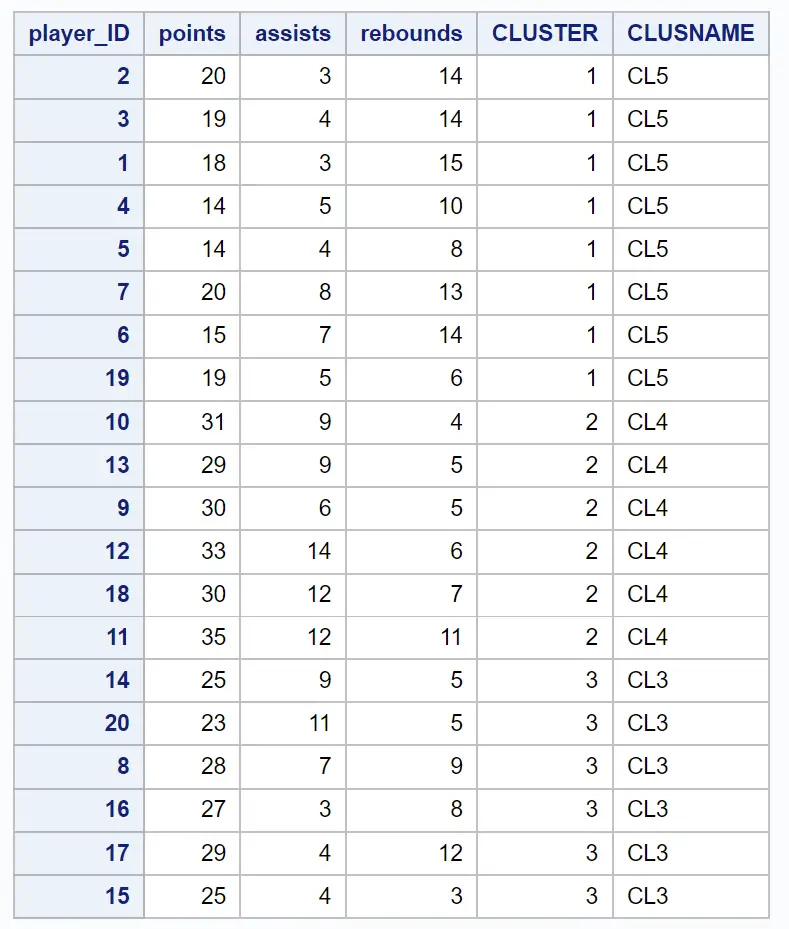
Por exemplo, podemos ver: que os jogadores com IDs 2, 3, 1, 4, 5, 7, 6 e 19 pertencem todos ao cluster 1 .
Isso nos diz que esses oito jogadores são “semelhantes” em termos de variáveis de pontos, assistências e rebotes.
Nota : Para este exemplo, optamos por usar a média como método de vinculação para clustering. Consulte a documentação do SAS para obter uma lista completa de outros métodos de ligação que você pode usar.
Recursos adicionais
Os tutoriais a seguir explicam como executar outras tarefas comuns no SAS:
Como realizar análise de componentes principais no SAS
Como realizar regressão linear múltipla no SAS
Como realizar regressão logística no SAS
About Author
Dr. benjamim anderson
Olá, sou Benjamin, um professor aposentado de estatística que se tornou professor dedicado na Statorials. Com vasta experiência e conhecimento na área de estatística, estou empenhado em compartilhar meu conhecimento para capacitar os alunos por meio de Statorials. Saber mais