O que é confiabilidade entre avaliadores? (definição e #038; exemplo)
Nas estatísticas, a confiabilidade entre avaliadores é uma forma de medir o nível de concordância entre vários avaliadores ou juízes.
É usado para avaliar a confiabilidade das respostas produzidas por diferentes itens de um teste. Se um teste tiver menor confiabilidade entre avaliadores, isso pode indicar que os itens do teste são confusos, pouco claros ou até mesmo inúteis.
Existem duas maneiras comuns de medir a confiabilidade entre avaliadores:
1. Porcentagem de concordância
A maneira simples de medir a confiabilidade entre avaliadores é calcular a porcentagem de itens com os quais os juízes concordam.
Isso é chamado de concordância percentual , que sempre fica entre 0 e 1, com 0 indicando nenhuma concordância entre os avaliadores e 1 indicando concordância perfeita entre os avaliadores.
Por exemplo, suponha que dois juízes sejam solicitados a avaliar a dificuldade de 10 itens de um teste em uma escala de 1 a 3. Os resultados são mostrados abaixo:
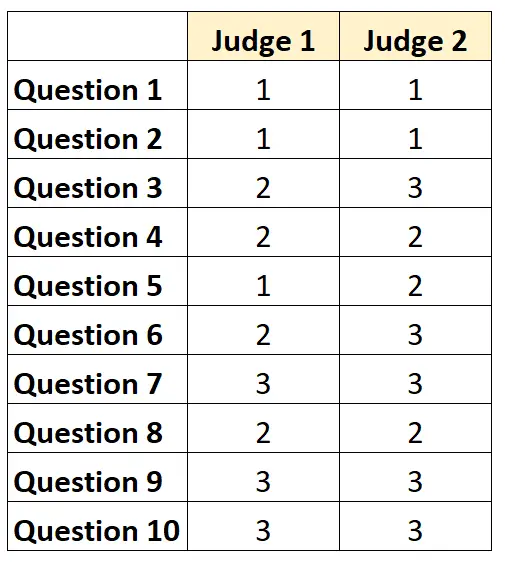
Para cada questão podemos escrever “1” se ambos os juízes concordarem e “0” se não concordarem.
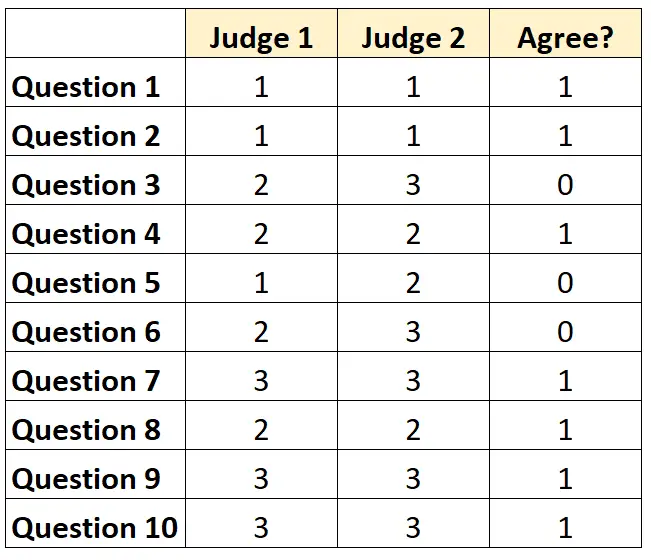
O percentual de questões em que os juízes concordaram foi 7/10 = 70% .
2. Kappa de Cohen
A maneira mais difícil (e mais rigorosa) de medir a confiabilidade entre avaliadores é usar o Kappa de Cohen , que calcula a porcentagem de itens com os quais os avaliadores concordam, levando em consideração que os avaliadores podem concordar apenas em alguns elementos. Felizmente.
A fórmula kappa de Cohen é calculada da seguinte forma:
k = (p o – p e ) / (1 – p e )
Ouro:
- p o : Concordância relativa observada entre os avaliadores
- p e : Probabilidade hipotética de concordância casual
O Kappa de Cohen varia sempre entre 0 e 1, sendo que 0 indica nenhuma concordância entre os avaliadores e 1 indica concordância perfeita entre os avaliadores.
Para obter um exemplo passo a passo de como calcular o Kappa de Cohen, consulte este tutorial .
Como interpretar a confiabilidade entre avaliadores
Quanto maior a confiabilidade entre avaliadores, mais consistentemente vários juízes avaliam itens ou questões em um teste com pontuações semelhantes.
Em geral, é necessária uma concordância entre avaliadores de pelo menos 75% na maioria das áreas para que um teste seja considerado confiável. No entanto, podem ser necessárias maiores fiabilidades entre avaliadores em domínios específicos.
Por exemplo, uma fiabilidade entre avaliadores de 75% pode ser aceitável para um teste que determine quão bem um programa de televisão será recebido.
Por outro lado, pode ser necessária uma confiabilidade de 95% entre avaliadores em ambientes médicos nos quais vários médicos estão julgando se um determinado tratamento deve ou não ser usado em um determinado paciente.
Observe que na maioria dos ambientes acadêmicos e em áreas de pesquisa rigorosas, o Kappa de Cohen é usado para calcular a confiabilidade entre avaliadores.
Recursos adicionais
Uma rápida introdução à análise de confiabilidade
O que é a confiabilidade dividida em duas?
O que é confiabilidade teste-reteste?
O que é confiabilidade de formulários paralelos?
O que é um erro padrão de medição?
Calculadora Kappa de Cohen
About Author
Dr. benjamim anderson
Olá, sou Benjamin, um professor aposentado de estatística que se tornou professor dedicado na Statorials. Com vasta experiência e conhecimento na área de estatística, estou empenhado em compartilhar meu conhecimento para capacitar os alunos por meio de Statorials. Saber mais