Um guia completo para o conjunto de dados iris em r
O conjunto de dados da íris é um conjunto de dados integrado em R que contém medidas em 4 atributos diferentes (em centímetros) para 50 flores de 3 espécies diferentes.
Este tutorial explica como explorar e resumir um conjunto de dados em R, usando o conjunto de dados iris como exemplo.
Relacionado: Um guia completo para o conjunto de dados mtcars em R
Carregar conjunto de dados Iris
Como o conjunto de dados iris é um conjunto de dados integrado em R, podemos carregá-lo usando o seguinte comando:
data(iris)
Podemos dar uma olhada nas primeiras seis linhas do conjunto de dados usando a função head() :
#view first six rows of iris dataset
head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
Resuma o conjunto de dados Iris
Podemos usar a função summary() para resumir rapidamente cada variável no conjunto de dados:
#summarize iris dataset
summary(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width
Min. :4,300 Min. :2,000 Min. :1,000 Min. :0.100
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
Median: 5,800 Median: 3,000 Median: 4,350 Median: 1,300
Mean:5.843 Mean:3.057 Mean:3.758 Mean:1.199
3rd Qu.:6,400 3rd Qu.:3,300 3rd Qu.:5,100 3rd Qu.:1,800
Max. :7,900 Max. :4,400 Max. :6,900 Max. :2,500
Species
setosa:50
versicolor:50
virginica :50
Para cada uma das variáveis numéricas podemos ver as seguintes informações:
- Min : O valor mínimo.
- 1º Qu : O valor do primeiro quartil (percentil 25).
- Mediana : O valor mediano.
- Média : O valor médio.
- 3º Qu : O valor do terceiro quartil (percentil 75).
- Máx .: O valor máximo.
Para a única variável categórica no conjunto de dados (Espécies), vemos uma contagem de frequência de cada valor:
- setosa : Esta espécie está presente 50 vezes.
- versicolor : Esta espécie ocorre 50 vezes.
- virginica : Esta espécie está presente 50 vezes.
Podemos usar a função dim() para obter as dimensões do conjunto de dados em termos de número de linhas e colunas:
#display rows and columns
dim(iris)
[1] 150 5
Podemos ver que o conjunto de dados possui 150 linhas e 5 colunas.
Também podemos usar a funçãonames () para exibir os nomes das colunas do quadro de dados:
#display column names
names(iris)
[1] "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width" "Species"
Visualize o conjunto de dados Iris
Também podemos criar gráficos para visualizar os valores do conjunto de dados.
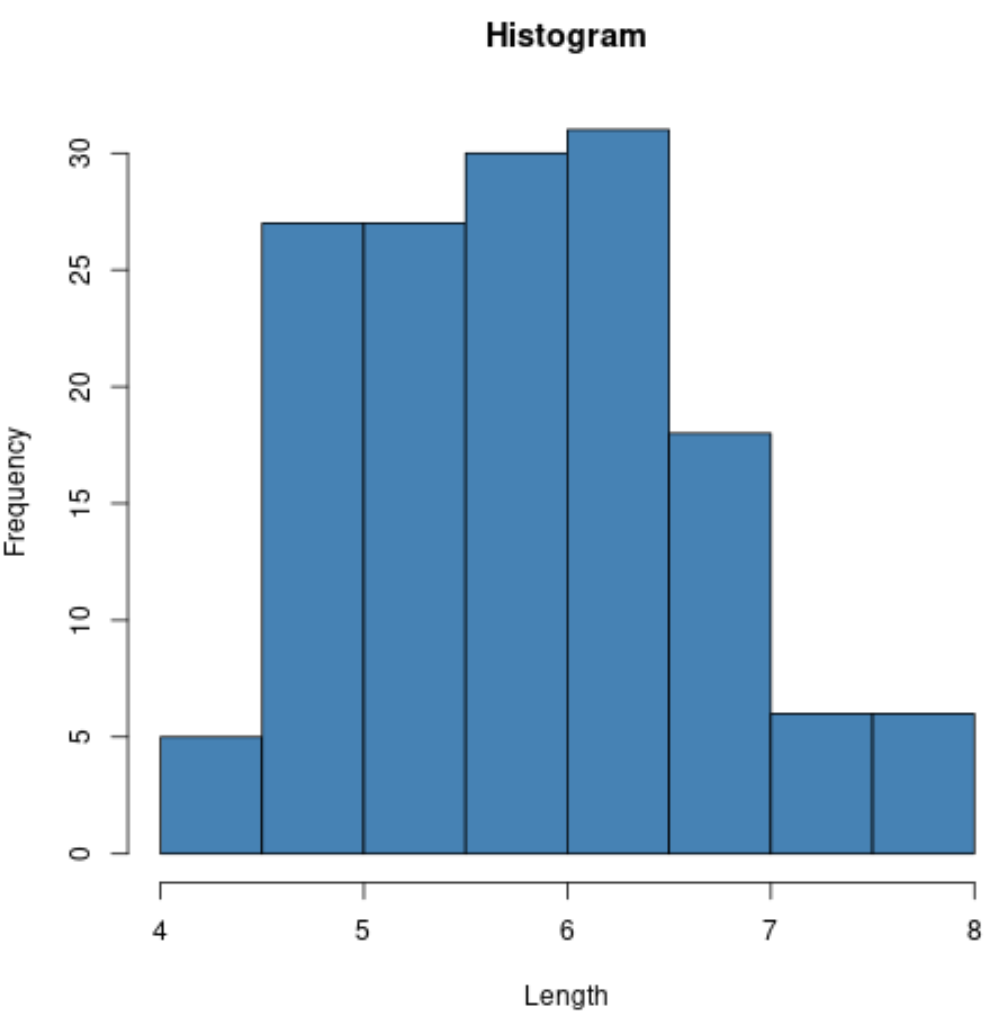
Por exemplo, podemos usar a função hist() para criar um histograma dos valores de uma determinada variável:
#create histogram of values for sepal length
hist(iris$Sepal.Length,
col=' steelblue ',
main=' Histogram ',
xlab=' Length ',
ylab=' Frequency ')
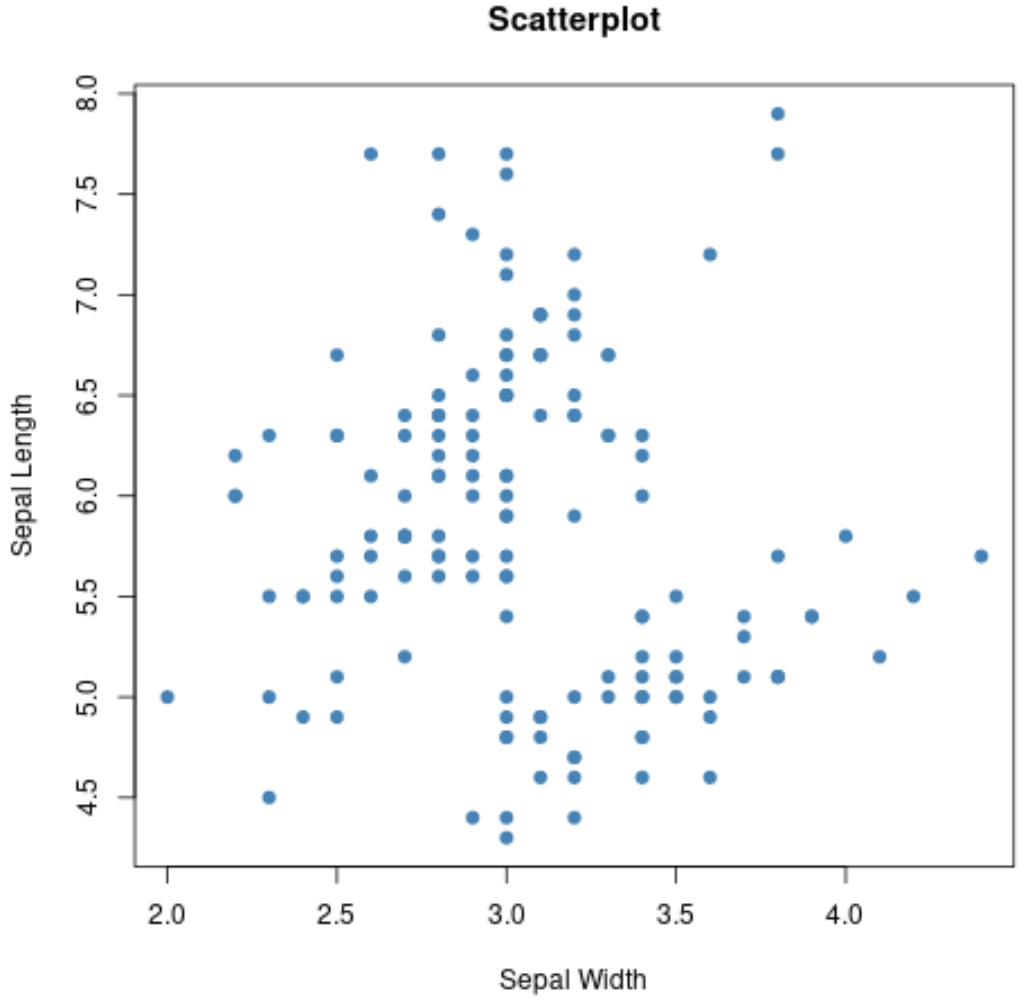
Também podemos usar a função plot() para criar um gráfico de dispersão de qualquer combinação de variáveis em pares:
#create scatterplot of sepal width vs. sepal length
plot(iris$Sepal.Width, iris$Sepal.Length,
col=' steelblue ',
main=' Scatterplot ',
xlab=' Sepal Width ',
ylab=' Sepal Length ',
pch= 19 )
Também podemos usar a função boxplot() para criar um boxplot por grupo:
#create scatterplot of sepal width vs. sepal length
boxplot(Sepal.Length~Species,
data=iris,
main=' Sepal Length by Species ',
xlab=' Species ',
ylab=' Sepal Length ',
col=' steelblue ',
border=' black ')
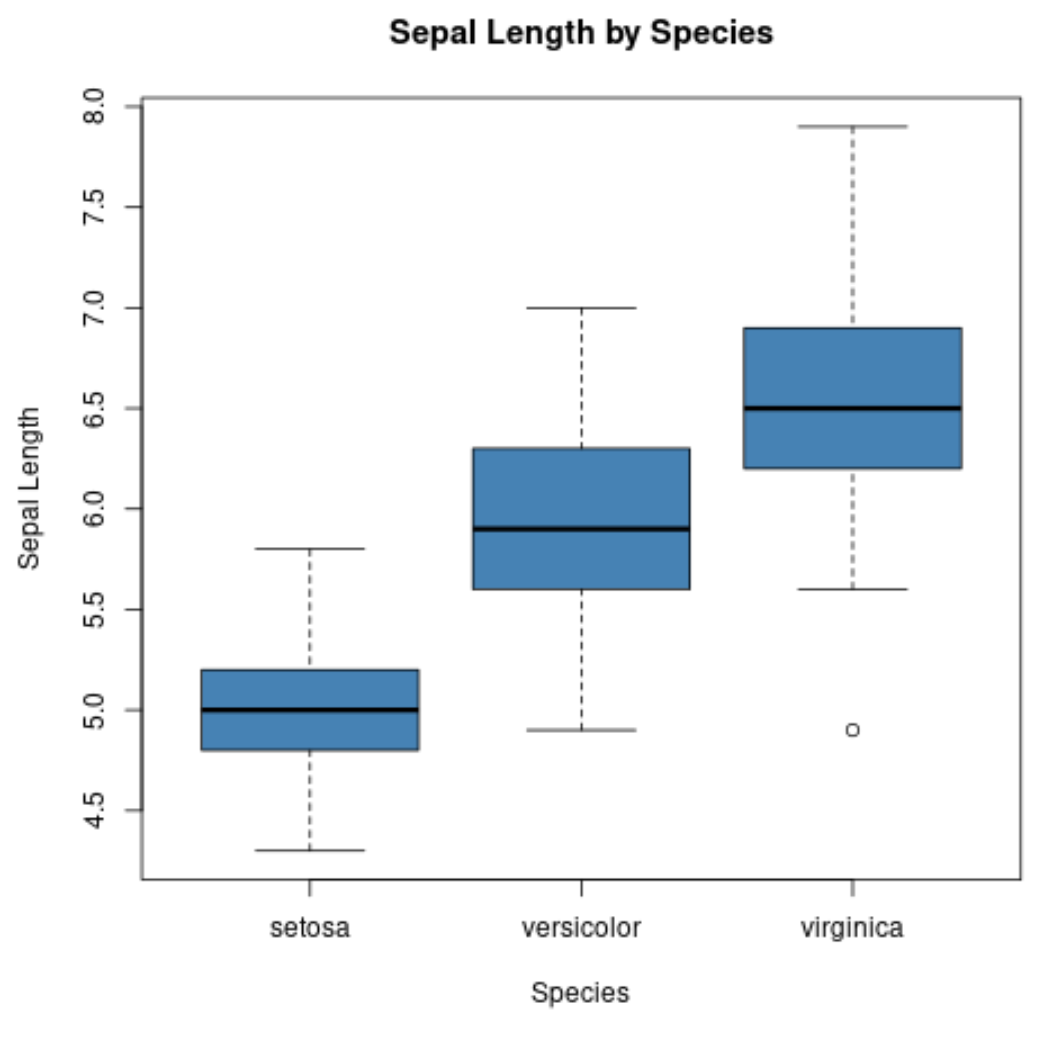
O eixo x exibe as três espécies e o eixo y exibe a distribuição dos valores de comprimento das sépalas para cada espécie.
Este tipo de plotagem permite perceber rapidamente que o comprimento das sépalas tende a ser maior para a espécie virginica e menor para a espécie setosa.
Recursos adicionais
Os tutoriais a seguir explicam com mais detalhes como resumir conjuntos de dados em R:
A maneira mais fácil de criar tabelas de resumo em R
Como calcular o resumo de cinco números em R
About Author
Dr. benjamim anderson
Olá, sou Benjamin, um professor aposentado de estatística que se tornou professor dedicado na Statorials. Com vasta experiência e conhecimento na área de estatística, estou empenhado em compartilhar meu conhecimento para capacitar os alunos por meio de Statorials. Saber mais