O que são dados de alta dimensão? (definição e exemplos)
Dados de alta dimensão referem-se a um conjunto de dados em que o número de recursos p é maior que o número de observações N , geralmente escrito como p >> N.
Por exemplo, um conjunto de dados com p = 6 características e apenas N = 3 observações seria considerado dados de alta dimensão porque o número de características é maior que o número de observações.
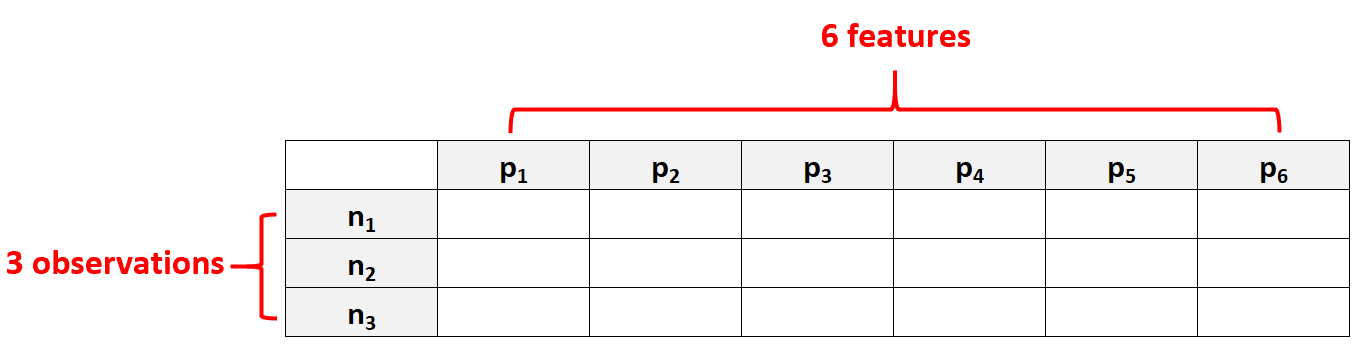
Um erro comum que as pessoas cometem é presumir que “dados de alta dimensão” significam simplesmente um conjunto de dados com muitos recursos. No entanto, isso está incorreto. Um conjunto de dados pode conter 10.000 características, mas se contiver 100.000 observações, não será altamente dimensional.
Nota: Consulte o Capítulo 18 de Elementos de Aprendizagem Estatística para uma discussão aprofundada da matemática por trás dos dados de alta dimensão.
Por que os dados de alta dimensão são um problema?
Quando o número de características num conjunto de dados excede o número de observações, nunca teremos uma resposta determinística.
Em outras palavras, torna-se impossível encontrar um modelo que possa descrever a relação entre as variáveis preditoras e a variável resposta , porque não temos observações suficientes para treinar o modelo.
Exemplos de dados de alta dimensão
Os exemplos a seguir ilustram conjuntos de dados de alta dimensão em diferentes domínios.
Exemplo 1: dados de saúde
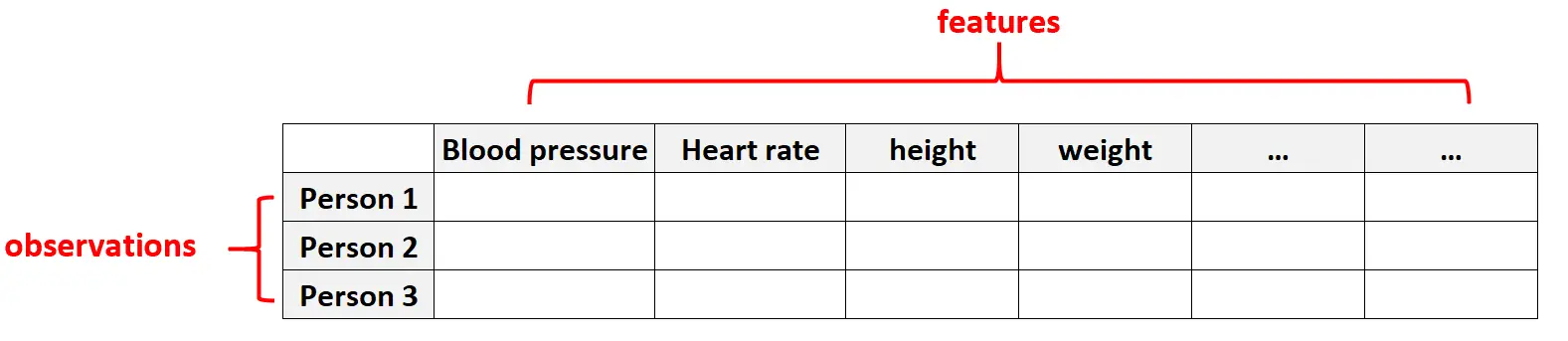
Dados de alta dimensão são comuns em conjuntos de dados de saúde, onde o número de características de um determinado indivíduo pode ser enorme (ou seja, pressão arterial, frequência cardíaca em repouso, estado do sistema imunológico, histórico cirúrgico, altura, peso, condições existentes, etc.).
Nestes conjuntos de dados, é comum que o número de feições seja maior que o número de observações.
Exemplo 2: dados financeiros
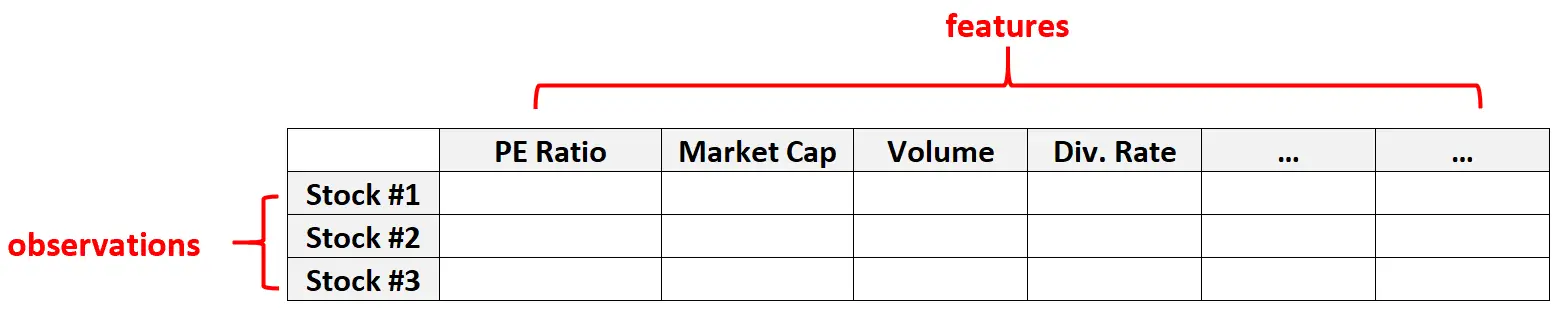
Dados de alta dimensão também são comuns em conjuntos de dados financeiros onde o número de características de uma determinada ação pode ser bastante grande (ou seja, índice PE, capitalização de mercado, volume de negociação, taxa de dividendos, etc.)
Nestes tipos de conjuntos de dados, é comum que o número de entidades seja muito maior que o número de ações individuais.
Exemplo 3: Genômica
Dados de alta dimensão também são comuns no campo da genômica, onde o número de características genéticas de um determinado indivíduo pode ser enorme.

Como lidar com grandes dados
Existem duas maneiras comuns de processar dados de alta dimensão:
1. Opte por incluir menos recursos.
A maneira mais óbvia de evitar lidar com dados de alta dimensão é simplesmente incluir menos recursos no conjunto de dados.
Existem várias maneiras de decidir quais recursos remover de um conjunto de dados, incluindo:
- Remover recursos com muitos valores ausentes: se uma determinada coluna em um conjunto de dados tiver muitos valores ausentes, você poderá removê-la completamente sem perder muitas informações.
- Remover recursos de baixa variação: se uma determinada coluna em um conjunto de dados tiver valores que mudam muito pouco, você poderá removê-la porque é improvável que ela ofereça tantas informações úteis sobre uma variável de resposta quanto outros recursos.
- Remova recursos com baixa correlação com a variável de resposta: se um determinado recurso não estiver altamente correlacionado com a variável de resposta de seu interesse, você provavelmente poderá removê-lo do conjunto de dados, pois é improvável que seja um recurso útil em um modelo.
2. Use um método de regularização.
Outra maneira de lidar com dados de alta dimensão sem remover recursos do conjunto de dados é usar uma técnica de regularização como:
- Análise do componente principal
- Regressão de componentes principais
- Regressão de pico
- Regressão laço
Cada uma dessas técnicas pode ser usada para processar dados de alta dimensão com eficiência.
Você pode encontrar uma lista completa de todos os tutoriais de aprendizado de máquina estatística nesta página .
About Author
Dr. benjamim anderson
Olá, sou Benjamin, um professor aposentado de estatística que se tornou professor dedicado na Statorials. Com vasta experiência e conhecimento na área de estatística, estou empenhado em compartilhar meu conhecimento para capacitar os alunos por meio de Statorials. Saber mais