Como realizar escalonamento multidimensional em r (com exemplo)
Em estatística, o escalonamento multidimensional é uma forma de visualizar a similaridade de observações em um conjunto de dados em um espaço cartesiano abstrato (geralmente espaço 2D).
A maneira mais fácil de realizar o escalonamento multidimensional em R é usar a função integrada cmdscale() , que usa a seguinte sintaxe básica:
cmdscale(d, eig = FALSO, k = 2,…)
Ouro:
- d : Uma matriz de distância geralmente calculada pela função dist() .
- eig : se deve ou não retornar autovalores.
- k : o número de dimensões nas quais os dados serão visualizados. O padrão é 2 .
O exemplo a seguir mostra como usar esta função na prática.
Exemplo: Escala Multidimensional em R
Suponha que temos o seguinte quadro de dados em R que contém informações sobre vários jogadores de basquete:
#create data frame df <- data. frame (points=c(4, 4, 6, 7, 8, 14, 16, 19, 25, 25, 28), assists=c(3, 2, 2, 5, 4, 8, 7, 6, 8, 10, 11), blocks=c(7, 3, 6, 7, 5, 8, 8, 4, 2, 2, 1), rebounds=c(4, 5, 5, 6, 5, 8, 10, 4, 3, 2, 2)) #add row names row. names (df) <- LETTERS[1:11] #view data frame df points assists blocks rebounds A 4 3 7 4 B 4 2 3 5 C 6 2 6 5 D 7 5 7 6 E 8 4 5 5 F 14 8 8 8 G 16 7 8 10 H 19 6 4 4 I 25 8 2 3 D 25 10 2 2 K 28 11 1 2
Podemos usar o código a seguir para realizar o dimensionamento multidimensional com a função cmdscale() e visualizar os resultados no espaço 2D:
#calculate distance matrix
d <- dist(df)
#perform multidimensional scaling
fit <- cmdscale(d, eig= TRUE , k= 2 )
#extract (x, y) coordinates of multidimensional scaling
x <- fit$points[,1]
y <- fit$points[,2]
#create scatterplot
plot(x, y, xlab=" Coordinate 1 ", ylab=" Coordinate 2 ",
main=" Multidimensional Scaling Results ", type=" n ")
#add row names of data frame as labels
text(x, y, labels=row. names (df))
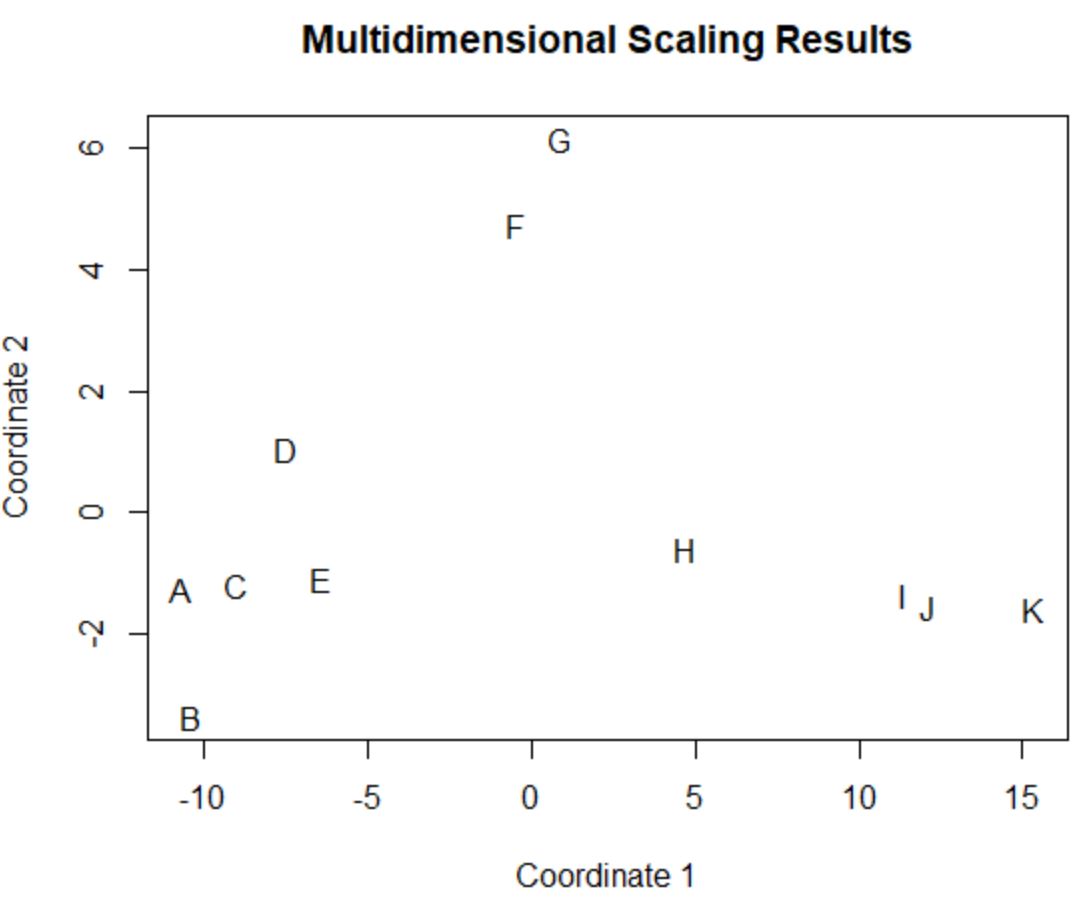
Os jogadores no quadro de dados original que possuem valores semelhantes nas quatro colunas originais (pontos, assistências, bloqueios e rebotes) estão próximos uns dos outros no gráfico.
Por exemplo, os jogadores A e C estão fechados um para o outro. Aqui estão os valores do quadro de dados original:
#view data frame values for players A and C df[rownames(df) %in% c(' A ', ' C '), ] points assists blocks rebounds A 4 3 7 4 C 6 2 6 5
Seus valores de pontos, assistências, bloqueios e rebotes são todos bastante semelhantes, o que explica por que estão tão próximos uns dos outros no gráfico 2D.
Em contraste, considere os jogadores B e K que estão distantes um do outro na trama.
Se nos referirmos aos seus valores nos dados originais, podemos ver que são bastante diferentes:
#view data frame values for players B and K df[rownames(df) %in% c(' B ', ' K '), ] points assists blocks rebounds B 4 2 3 5 K 28 11 1 2
Portanto, o gráfico 2D é uma boa maneira de visualizar a semelhança de cada jogador em todas as variáveis do quadro de dados.
Jogadores com estatísticas semelhantes são agrupados próximos, enquanto jogadores com estatísticas muito diferentes estão mais distantes uns dos outros na trama.
Observe que você também pode extrair as coordenadas exatas (x, y) de cada jogador do gráfico digitando fit , que é o nome da variável na qual armazenamos os resultados da função cmdscale() :
#view (x, y) coordinates of points in the plot
fit
[,1] [,2]
A -10.6617577 -1.2511291
B -10.3858237 -3.3450473
C -9.0330408 -1.1968116
D -7.4905743 1.0578445
E -6.4021114 -1.0743669
F -0.4618426 4.7392534
G 0.8850934 6.1460850
H 4.7352436 -0.6004609
I 11.3793381 -1.3563398
J 12.0844168 -1.5494108
K 15.3510585 -1.5696166
Recursos adicionais
Os tutoriais a seguir explicam como realizar outras tarefas comuns em R:
Como normalizar dados em R
Como fazer data center em R
Como remover outliers em R
About Author
Dr. benjamim anderson
Olá, sou Benjamin, um professor aposentado de estatística que se tornou professor dedicado na Statorials. Com vasta experiência e conhecimento na área de estatística, estou empenhado em compartilhar meu conhecimento para capacitar os alunos por meio de Statorials. Saber mais