Como realizar escalonamento multidimensional em python
Em estatística, o escalonamento multidimensional é uma forma de visualizar a similaridade de observações em um conjunto de dados em um espaço cartesiano abstrato (geralmente espaço 2D).
A maneira mais fácil de realizar o escalonamento multidimensional em Python é usar a função MDS() do submódulo sklearn.manifold .
O exemplo a seguir mostra como usar esta função na prática.
Exemplo: escalonamento multidimensional em Python
Suponha que temos o seguinte DataFrame do pandas que contém informações sobre vários jogadores de basquete:
import pandas as pd #create DataFrane df = pd. DataFrame ({' player ': ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K '], ' points ': [4, 4, 6, 7, 8, 14, 16, 19, 25, 25, 28], ' assists ': [3, 2, 2, 5, 4, 8, 7, 6, 8, 10, 11], ' blocks ': [7, 3, 6, 7, 5, 8, 8, 4, 2, 2, 1], ' rebounds ': [4, 5, 5, 6, 5, 8, 10, 4, 3, 2, 2]}) #set player column as index column df = df. set_index (' player ') #view Dataframe print (df) points assists blocks rebounds player A 4 3 7 4 B 4 2 3 5 C 6 2 6 5 D 7 5 7 6 E 8 4 5 5 F 14 8 8 8 G 16 7 8 10 H 19 6 4 4 I 25 8 2 3 D 25 10 2 2 K 28 11 1 2
Podemos usar o código a seguir para realizar o escalonamento multidimensional com a função MDS() do módulo sklearn.manifold :
from sklearn. manifold import MDS
#perform multi-dimensional scaling
mds = MDS(random_state= 0 )
scaled_df = mds. fit_transform (df)
#view results of multi-dimensional scaling
print (scaled_df)
[[ 7.43654469 8.10247222]
[4.13193821 10.27360901]
[5.20534681 7.46919526]
[6.22323046 4.45148627]
[3.74110999 5.25591459]
[3.69073384 -2.88017811]
[3.89092087 -5.19100988]
[ -3.68593169 -3.0821144 ]
[ -9.13631889 -6.81016012]
[ -8.97898385 -8.50414387]
[-12.51859044 -9.08507097]]
Cada linha do DataFrame original foi reduzida a uma coordenada (x, y).
Podemos usar o seguinte código para visualizar essas coordenadas no espaço 2D:
import matplotlib.pyplot as plt #create scatterplot plt. scatter (scaled_df[:,0], scaled_df[:,1]) #add axis labels plt. xlabel (' Coordinate 1 ') plt. ylabel (' Coordinate 2 ') #add lables to each point for i, txt in enumerate( df.index ): plt. annotate (txt, (scaled_df[:,0][i]+.3, scaled_df[:,1][i])) #display scatterplot plt. show ()
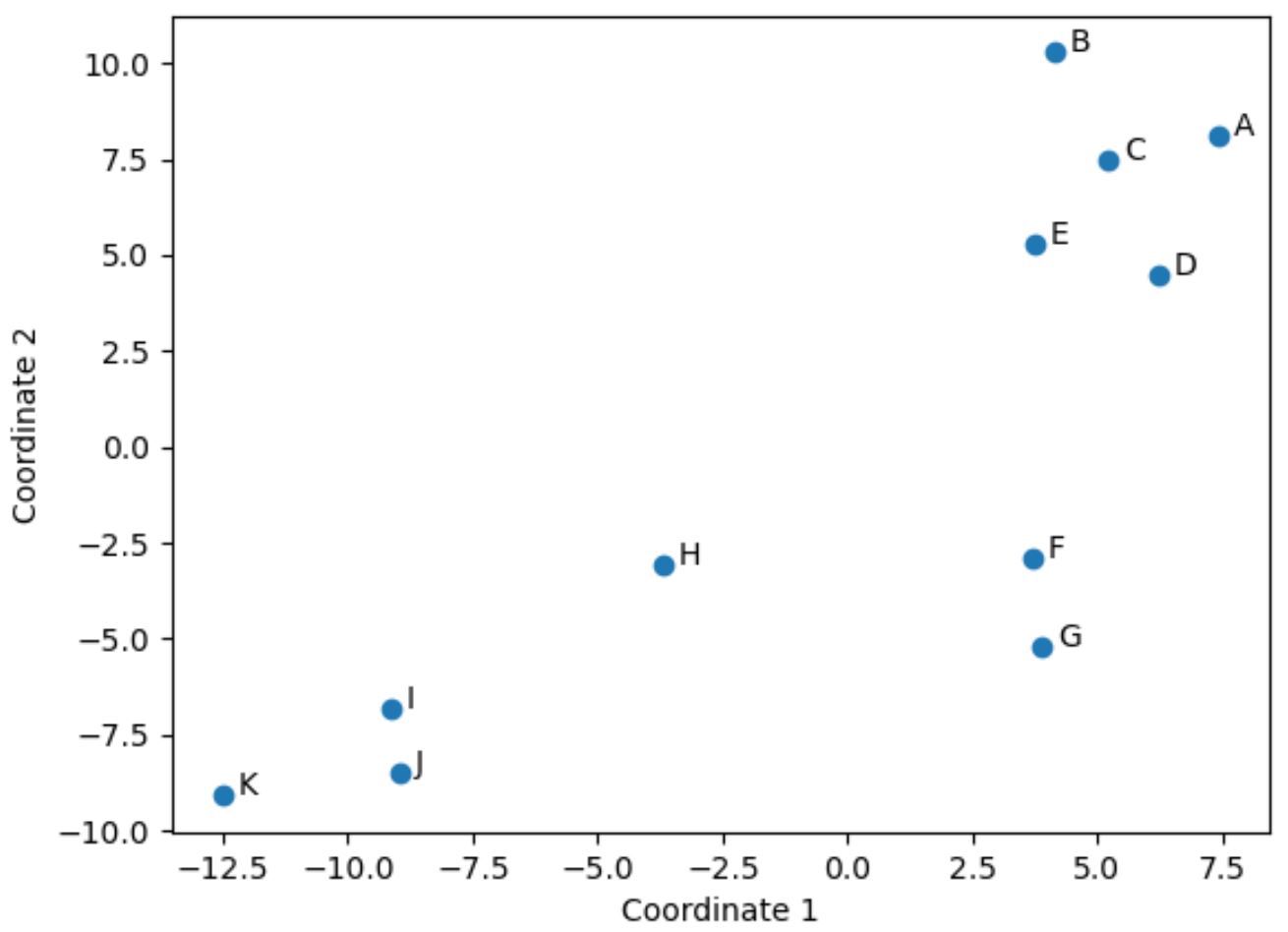
Os jogadores no DataFrame original que possuem valores semelhantes nas quatro colunas originais (pontos, assistências, bloqueios e rebotes) estão próximos uns dos outros no gráfico.
Por exemplo, os jogadores F e G estão fechados entre si. Aqui estão os valores do DataFrame original:
#select rows with index labels 'F' and 'G'
df. loc [[' F ',' G ']]
points assists blocks rebounds
player
F 14 8 8 8
G 16 7 8 10
Seus valores de pontos, assistências, bloqueios e rebotes são todos bastante semelhantes, o que explica por que estão tão próximos uns dos outros no gráfico 2D.
Em contraste, considere os jogadores B e K que estão distantes um do outro na trama.
Se nos referirmos aos seus valores no DataFrame original, podemos ver que eles são bem diferentes:
#select rows with index labels 'B' and 'K'
df. loc [[' B ',' K ']]
points assists blocks rebounds
player
B 4 2 3 5
K 28 11 1 2
Portanto, o gráfico 2D é uma boa maneira de visualizar o quão semelhante cada jogador é em todas as variáveis do DataFframe.
Jogadores com estatísticas semelhantes são agrupados próximos, enquanto jogadores com estatísticas muito diferentes estão mais distantes uns dos outros na trama.
Recursos adicionais
Os tutoriais a seguir explicam como realizar outras tarefas comuns em Python:
Como normalizar dados em Python
Como remover valores discrepantes em Python
Como testar a normalidade em Python
About Author
Dr. benjamim anderson
Olá, sou Benjamin, um professor aposentado de estatística que se tornou professor dedicado na Statorials. Com vasta experiência e conhecimento na área de estatística, estou empenhado em compartilhar meu conhecimento para capacitar os alunos por meio de Statorials. Saber mais