Uma introdução simples para impulsionar o aprendizado de máquina
A maioria dos algoritmos de aprendizado de máquina supervisionado são baseados no uso de um único modelo preditivo, como regressão linear , regressão logística , regressão de crista , etc.
No entanto, métodos como ensacamento e florestas aleatórias constroem muitos modelos diferentes com base em amostras repetidas de bootstrap do conjunto de dados original. As previsões sobre novos dados são feitas calculando a média das previsões feitas pelos modelos individuais.
Esses métodos tendem a oferecer uma melhoria na precisão da previsão em relação aos métodos que usam apenas um único modelo preditivo porque usam o seguinte processo:
- Primeiro, construa modelos individuais com alta variância e baixo viés (por exemplo, árvores de decisão profundamente desenvolvidas).
- Em seguida, calcule a média das previsões feitas pelos modelos individuais para reduzir a variância.
Outro método que tende a oferecer uma melhoria ainda maior na precisão preditiva é conhecido como boosting .
O que é impulsionar?
Boosting é um método que pode ser usado com qualquer tipo de modelo, mas é mais frequentemente usado com árvores de decisão.
A ideia por trás do boosting é simples:
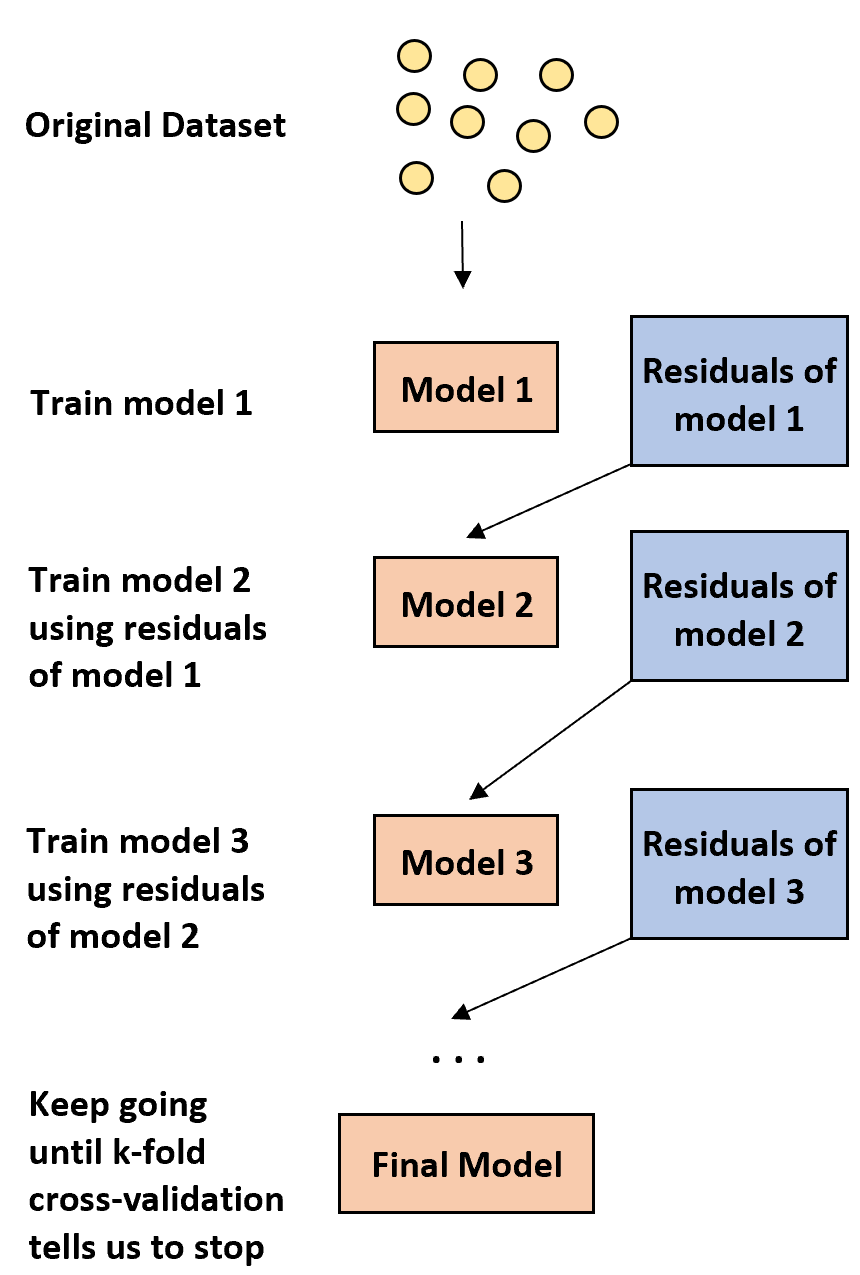
1. Primeiro, construa um modelo fraco.
- Um modelo “fraco” é aquele cuja taxa de erro é apenas ligeiramente melhor do que uma estimativa aleatória.
- Na prática, esta é geralmente uma árvore de decisão com apenas uma ou duas divisões.
2. Em seguida, construa outro modelo fraco com base nos resíduos do modelo anterior.
- Na prática, utilizamos os resíduos do modelo anterior (ou seja, os erros nas nossas previsões) para ajustar um novo modelo que melhora ligeiramente a taxa de erro global.
3. Continue este processo até que a validação cruzada k-fold nos diga para parar.
- Na prática, usamos validação cruzada k-fold para identificar quando devemos parar de desenvolver o modelo otimizado.
Usando este método, podemos começar com um modelo fraco e continuar a “melhorar” seu desempenho construindo sequencialmente novas árvores que melhorem o desempenho da árvore anterior até obtermos um modelo final com alta precisão preditiva.
Por que impulsionar funciona?
Acontece que o boosting é capaz de produzir alguns dos modelos mais poderosos de todo o aprendizado de máquina.
Em muitas indústrias, os modelos otimizados são usados como modelos de referência na produção porque tendem a superar todos os outros modelos.
A razão pela qual os modelos otimizados funcionam tão bem se resume à compreensão de uma ideia simples:
1. Primeiro, os modelos melhorados constroem uma árvore de decisão fraca com baixa precisão preditiva. Diz-se que esta árvore de decisão tem baixa variância e alto viés.
2. À medida que os modelos melhorados seguem o processo de melhoria sequencial das árvores de decisão anteriores, o modelo global é capaz de reduzir lentamente o viés em cada etapa sem aumentar significativamente a variância.
3. O modelo final ajustado tende a ter viés e variância suficientemente baixos, levando a um modelo capaz de produzir baixas taxas de erro de teste em novos dados.
Vantagens e desvantagens de impulsionar
A vantagem óbvia do boosting é que ele é capaz de produzir modelos com alta precisão preditiva em comparação com quase todos os outros tipos de modelos.
Uma desvantagem potencial é que um modelo melhorado ajustado é muito difícil de interpretar. Embora possa oferecer uma tremenda capacidade de prever valores de resposta de novos dados, é difícil explicar o processo exato que utiliza para conseguir isso.
Na prática, a maioria dos cientistas de dados e profissionais de aprendizado de máquina criam modelos aprimorados porque desejam prever com precisão os valores de resposta de novos dados. Assim, o facto de os modelos melhorados serem difíceis de interpretar geralmente não é um problema.
Reforço na prática
Na prática, existem muitos tipos de algoritmos usados para impulsionar, incluindo:
Dependendo do tamanho do seu conjunto de dados e do poder de processamento da sua máquina, um desses métodos pode ser preferível ao outro.
About Author
Dr. benjamim anderson
Olá, sou Benjamin, um professor aposentado de estatística que se tornou professor dedicado na Statorials. Com vasta experiência e conhecimento na área de estatística, estou empenhado em compartilhar meu conhecimento para capacitar os alunos por meio de Statorials. Saber mais