Como calcular a distância de cook em python
A distância de Cook é usada para identificar observações influentes em um modelo de regressão.
A fórmula para a distância de Cook é:
d i = (r i 2 / p*MSE) * (h ii / (1-h ii ) 2 )
Ouro:
- ri é o i- ésimo resíduo
- p é o número de coeficientes no modelo de regressão
- MSE é o erro quadrático médio
- h ii é o i- ésimo valor de alavancagem
Essencialmente, a distância de Cook mede o quanto todos os valores ajustados do modelo mudam quando a i- ésima observação é removida.
Quanto maior o valor da distância de Cook, mais influente é uma determinada observação.
Como regra geral, qualquer observação com distância de Cook superior a 4/n (onde n = total de observações) é considerada como tendo uma grande influência.
Este tutorial fornece um exemplo passo a passo de como calcular a distância de Cook para um determinado modelo de regressão em Python.
Passo 1: Insira os dados
Primeiro, criaremos um pequeno conjunto de dados para trabalhar em Python:
import pandas as pd #create dataset df = pd. DataFrame ({' x ': [8, 12, 12, 13, 14, 16, 17, 22, 24, 26, 29, 30], ' y ': [41, 42, 39, 37, 35, 39, 45, 46, 39, 49, 55, 57]})
Passo 2: Ajustar o modelo de regressão
A seguir, ajustaremos um modelo de regressão linear simples :
import statsmodels. api as sm
#define response variable
y = df[' y ']
#define explanatory variable
x = df[' x ']
#add constant to predictor variables
x = sm. add_constant (x)
#fit linear regression model
model = sm. OLS (y,x). fit ()
Etapa 3: calcular a distância de cozimento
A seguir, calcularemos a distância de Cook para cada observação do modelo:
#suppress scientific notation
import numpy as np
n.p. set_printoptions (suppress= True )
#create instance of influence
influence = model. get_influence ()
#obtain Cook's distance for each observation
cooks = influence. cooks_distance
#display Cook's distances
print (cooks)
(array([0.368, 0.061, 0.001, 0.028, 0.105, 0.022, 0.017, 0. , 0.343,
0. , 0.15 , 0.349]),
array([0.701, 0.941, 0.999, 0.973, 0.901, 0.979, 0.983, 1. , 0.718,
1. , 0.863, 0.713]))
Por padrão, a função cooks_distance() exibe uma matriz de valores para a distância de Cook para cada observação seguida por uma matriz de valores p correspondentes.
Por exemplo:
- Distância de Cook para observação nº 1: 0,368 (valor p: 0,701)
- Distância de Cook para observação nº 2: 0,061 (valor p: 0,941)
- Distância de Cook para observação nº 3: 0,001 (valor p: 0,999)
E assim por diante.
Passo 4: Visualize as distâncias do cozinheiro
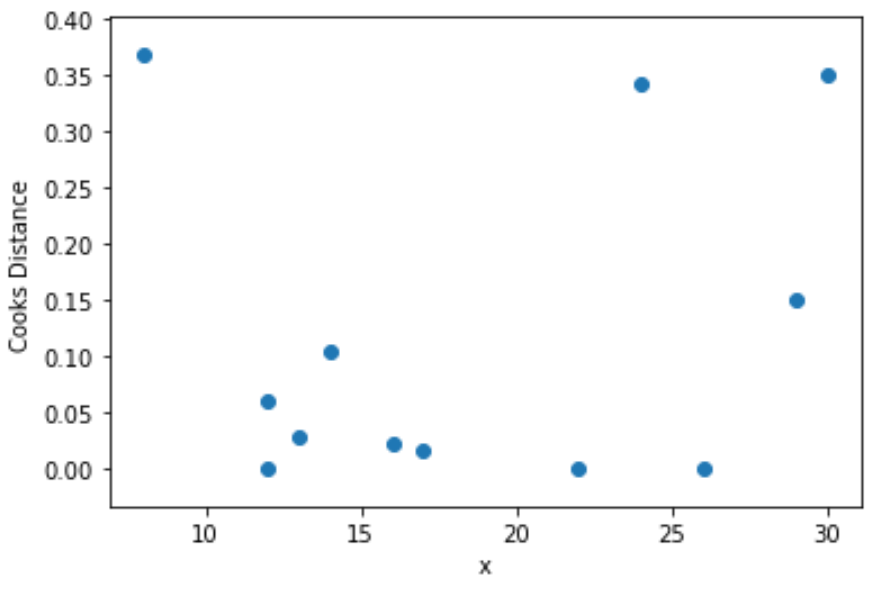
Por fim, podemos criar um gráfico de dispersão para visualizar os valores da variável preditora em função da distância de Cook para cada observação:
import matplotlib. pyplot as plt
plt. scatter (df.x, cooks[0])
plt. xlabel (' x ')
plt. ylabel (' Cooks Distance ')
plt. show ()
Pensamentos finais
É importante notar que a distância de Cook deve ser usada para identificar observações potencialmente influentes. Só porque uma observação é influente não significa que deva ser removida do conjunto de dados.
Primeiro, você precisa verificar se a observação não é resultado de um erro de entrada de dados ou de outro evento estranho. Se for um valor legítimo, você poderá decidir se é apropriado removê-lo, deixá-lo como está ou simplesmente substituí-lo por um valor alternativo como a mediana.
About Author
Dr. benjamim anderson
Olá, sou Benjamin, um professor aposentado de estatística que se tornou professor dedicado na Statorials. Com vasta experiência e conhecimento na área de estatística, estou empenhado em compartilhar meu conhecimento para capacitar os alunos por meio de Statorials. Saber mais