Regressão ou classificação: qual a diferença?
Os algoritmos de aprendizado de máquina podem ser divididos em dois tipos distintos: algoritmos de aprendizado supervisionado e não supervisionado .

Algoritmos de aprendizagem supervisionada podem ser classificados em dois tipos:
1. Regressão: A variável resposta é contínua.
Por exemplo, a variável de resposta poderia ser:
- Peso
- Altura
- Preço
- Tempo
- Unidades totais
Em cada caso, um modelo de regressão procura prever uma quantidade contínua.
Exemplo de regressão:
Digamos que temos um conjunto de dados contendo três variáveis para 100 casas diferentes: metragem quadrada, número de banheiros e preço de venda.
Poderíamos ajustar um modelo de regressão que utilizasse a metragem quadrada e o número de banheiros como variáveis explicativas e o preço de venda como variável de resposta.
Poderíamos então utilizar este modelo para prever o preço de venda de uma casa, com base na sua metragem quadrada e no número de casas de banho.
Este é um exemplo de modelo de regressão porque a variável resposta (preço de venda) é contínua.
A maneira mais comum de medir a precisão de um modelo de regressão é calcular a raiz do erro quadrático médio (RMSE), uma métrica que nos diz a que distância nossos valores previstos estão dos valores observados em um modelo, em média. É calculado da seguinte forma:
RMSE = √ Σ(P i – O i ) 2 / n
Ouro:
- Σ é um símbolo sofisticado que significa “soma”
- Pi é o valor previsto para a i-ésima observação
- O i é o valor observado para a i-ésima observação
- n é o tamanho da amostra
Quanto menor o RMSE, melhor o modelo de regressão é capaz de ajustar os dados.
2. Classificação: A variável resposta é categórica.
Por exemplo, a variável de resposta poderia assumir os seguintes valores:
- Macho ou fêmea
- Ter sucesso ou falhar
- Baixo, médio ou alto
Em cada caso, um modelo de classificação procura prever um rótulo de classe.
Exemplo de classificação:
Digamos que temos um conjunto de dados contendo três variáveis para 100 jogadores de basquete universitário diferentes: média de pontos por jogo, nível de divisão e se eles foram ou não convocados para a NBA.
Poderíamos adaptar um modelo de classificação que utilizasse a média de pontos por jogo e por nível de divisão como variáveis explicativas e “elaborado” como variável resposta.
Poderíamos então usar esse modelo para prever se um determinado jogador será ou não convocado para a NBA com base na média de pontos por jogo e no nível da divisão.
Este é um exemplo de modelo de classificação porque a variável resposta (“escrita”) é categórica. Ou seja, só pode assumir valores em duas categorias diferentes: “Escrito” ou “Não Elaborado”.
A forma mais comum de medir a precisão de um modelo de classificação é simplesmente calcular a porcentagem de classificações corretas feitas pelo modelo:
Precisão = classificações de correção / número total de tentativas de classificação * 100%
Por exemplo, se um modelo identifica corretamente se um jogador será ou não convocado para a NBA 88 vezes em 100 vezes possíveis, então a precisão do modelo é:
Precisão = (88/100) * 100% = 88%
Quanto maior a precisão, melhor o modelo de classificação é capaz de prever os resultados.
Semelhanças entre regressão e classificação
Os algoritmos de regressão e classificação são semelhantes das seguintes maneiras:
- Ambos são algoritmos de aprendizagem supervisionada, ou seja, ambos envolvem uma variável de resposta.
- Ambos usam uma ou mais variáveis explicativas para criar modelos para prever uma resposta.
- Ambos podem ser usados para entender como as mudanças nos valores das variáveis explicativas afetam os valores de uma variável resposta.
Diferenças entre regressão e classificação
Os algoritmos de regressão e classificação diferem das seguintes maneiras:
- Os algoritmos de regressão procuram prever uma quantidade contínua e os algoritmos de classificação procuram prever um rótulo de classe.
- A forma como medimos a precisão dos modelos de regressão e classificação difere.
Convertendo regressão em classificação
Deve-se notar que um problema de regressão pode ser convertido em um problema de classificação simplesmente discretizando a variável resposta em compartimentos.
Por exemplo, digamos que temos um conjunto de dados que contém três variáveis: metragem quadrada, número de banheiros e preço de venda.
Poderíamos construir um modelo de regressão usando a metragem quadrada e o número de banheiros para prever os preços de venda.
No entanto, poderíamos discretizar o preço de venda em três classes diferentes:
- US$ 80.000 – US$ 160.000: “Preço de venda baixo”
- US$ 161.000 – US$ 240.000: “Preço médio de venda”
- US$ 241.000 – US$ 320.000: “Alto preço de venda”
Poderíamos então usar a metragem quadrada e o número de banheiros como variáveis explicativas para prever em qual classe (baixa, média ou alta) o preço de venda de uma determinada casa se enquadrará.
Este seria um exemplo de modelo de classificação, pois estamos tentando colocar cada casa em uma classe.
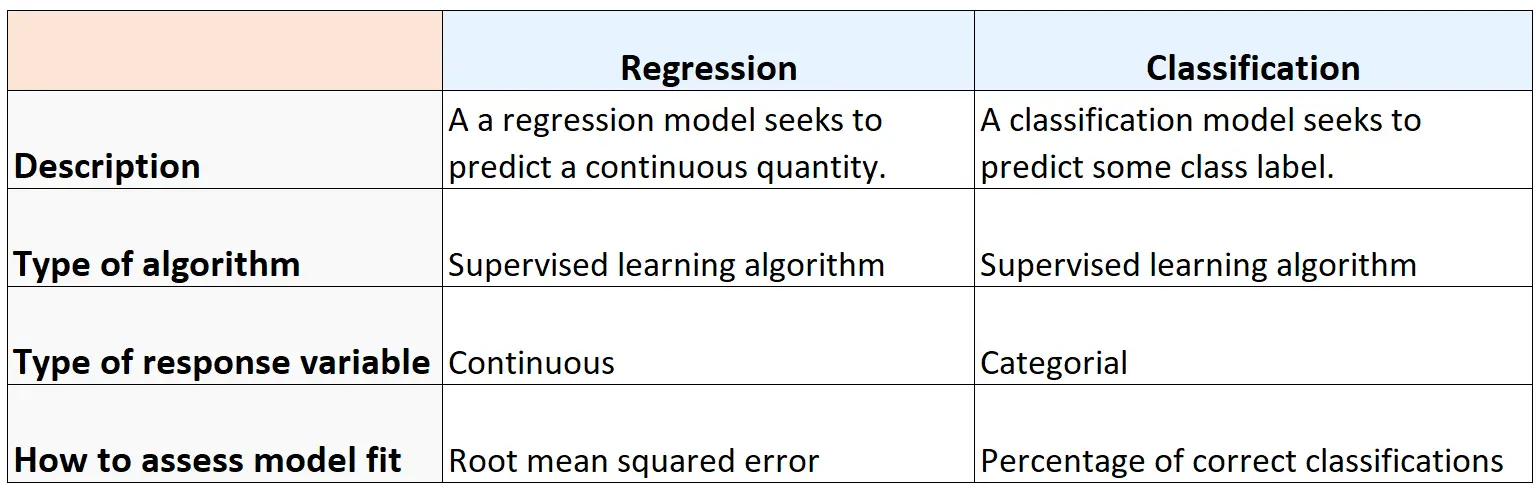
Resumo
A tabela a seguir resume as semelhanças e diferenças entre algoritmos de regressão e classificação:
About Author
Dr. benjamim anderson
Olá, sou Benjamin, um professor aposentado de estatística que se tornou professor dedicado na Statorials. Com vasta experiência e conhecimento na área de estatística, estou empenhado em compartilhar meu conhecimento para capacitar os alunos por meio de Statorials. Saber mais