Como calcular resíduos estudantis em python
Um resíduo de estudante é simplesmente um resíduo dividido pelo seu desvio padrão estimado.
Na prática, geralmente dizemos que qualquer observação num conjunto de dados cujo resíduo de estudante seja maior que um valor absoluto de 3 é um outlier.
Podemos obter rapidamente os resíduos estudantis de um modelo de regressão em Python usando a função OLSResults.outlier_test() de statsmodels, que usa a seguinte sintaxe:
OLSResults.outlier_test()
onde OLSResults é o nome de um modelo linear ajustado usando a função statsmodels ols() .
Exemplo: cálculo de resíduos estudantis em Python
Suponha que construímos o seguinte modelo de regressão linear simples em Python:
#import necessary packages and functions import numpy as np import pandas as pd import statsmodels. api as sm from statsmodels. formula . api import ols #create dataset df = pd. DataFrame ({'rating': [90, 85, 82, 88, 94, 90, 76, 75, 87, 86], 'points': [25, 20, 14, 16, 27, 20, 12, 15, 14, 19]}) #fit simple linear regression model model = ols('rating ~ points', data=df). fit ()
Podemos usar a função outlier_test() para produzir um DataFrame que contém os resíduos estudantis para cada observação no conjunto de dados:
#calculate studentized residuals stud_res = model. outlier_test () #display studentized residuals print(stud_res) student_resid unadj_p bonf(p) 0 -0.486471 0.641494 1.000000 1 -0.491937 0.637814 1.000000 2 0.172006 0.868300 1.000000 3 1.287711 0.238781 1.000000 4 0.106923 0.917850 1.000000 5 0.748842 0.478355 1.000000 6 -0.968124 0.365234 1.000000 7 -2.409911 0.046780 0.467801 8 1.688046 0.135258 1.000000 9 -0.014163 0.989095 1.000000
Este DataFrame exibe os seguintes valores para cada observação no conjunto de dados:
- O resíduo estudantilizado
- O valor p não ajustado do resíduo estudantil
- O valor p corrigido por Bonferroni do resíduo estudantil
Podemos ver que o resíduo estudantil para a primeira observação no conjunto de dados é -0.486471 , o resíduo estudantil para a segunda observação é -0.491937 e assim por diante.
Também podemos criar um gráfico rápido dos valores das variáveis preditoras em relação aos resíduos estudantis correspondentes:
import matplotlib. pyplot as plt #define predictor variable values and studentized residuals x = df[' points '] y = stud_res[' student_resid '] #create scatterplot of predictor variable vs. studentized residuals plt. scatter (x,y) plt. axhline (y=0, color=' black ', linestyle=' -- ') plt. xlabel (' Points ') plt. ylabel (' Studentized Residuals ')
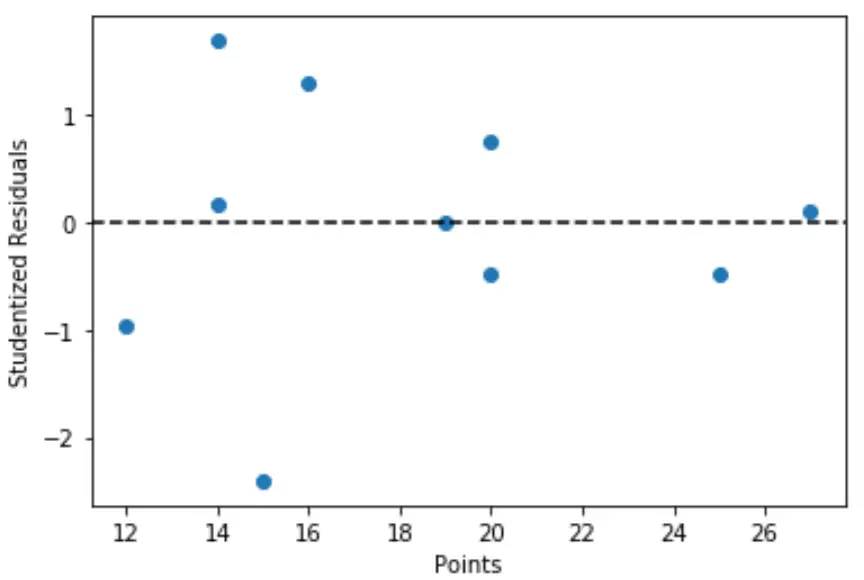
No gráfico podemos ver que nenhuma das observações possui um resíduo de aluno com valor absoluto superior a 3, portanto, não há valores discrepantes claros no conjunto de dados.
Recursos adicionais
Como realizar regressão linear simples em Python
Como realizar regressão linear múltipla em Python
Como criar um gráfico residual em Python
About Author
Dr. benjamim anderson
Olá, sou Benjamin, um professor aposentado de estatística que se tornou professor dedicado na Statorials. Com vasta experiência e conhecimento na área de estatística, estou empenhado em compartilhar meu conhecimento para capacitar os alunos por meio de Statorials. Saber mais