Seleção aleatória ou atribuição aleatória
A seleção aleatória e a atribuição aleatória são duas técnicas estatísticas comumente usadas, mas muitas vezes confusas.
A seleção aleatória refere-se ao processo de seleção aleatória de indivíduos de uma população para serem envolvidos em um estudo.
A atribuição aleatória refere-se ao processo de atribuição aleatória de indivíduos participantes de um estudo a um grupo de tratamento ou grupo de controle.
Você pode pensar na seleção aleatória como o processo usado para “colocar” indivíduos em um estudo e pode pensar na atribuição aleatória como o que você “faz” com esses indivíduos depois que eles são selecionados para fazer parte do estudo.
A importância da seleção aleatória e da atribuição aleatória
Quando um estudo utiliza seleção aleatória , ele seleciona indivíduos de uma população por meio de um processo aleatório. Por exemplo, se uma população tiver 1.000 indivíduos, poderíamos usar um computador para selecionar aleatoriamente 100 desses indivíduos de um banco de dados. Isso significa que cada indivíduo tem a mesma probabilidade de ser selecionado para fazer parte do estudo, aumentando as chances de se obter uma amostra representativa – com características semelhantes às da população geral.
Ao utilizar uma amostra representativa em nosso estudo, podemos generalizar os resultados do nosso estudo para a população. Em termos estatísticos, isto chama-se ter validade externa – é válido externalizar os nossos resultados para a população em geral.
Quando um estudo usa atribuição aleatória , ele atribui indivíduos aleatoriamente a um grupo de tratamento ou grupo de controle. Por exemplo, se tivermos 100 indivíduos num estudo, poderíamos utilizar um gerador de números aleatórios para atribuir aleatoriamente 50 indivíduos a um grupo de controle e 50 indivíduos a um grupo de tratamento.
Ao utilizar a atribuição aleatória, aumentamos a probabilidade de os dois grupos terem características aproximadamente semelhantes, o que significa que quaisquer diferenças observadas entre os dois grupos podem ser atribuídas ao tratamento. Isto significa que o estudo tem validade interna : é válido atribuir quaisquer diferenças entre os grupos ao próprio tratamento, em oposição às diferenças entre os indivíduos dos grupos.
Exemplos de seleção aleatória e atribuição aleatória
É possível que um estudo utilize tanto a seleção aleatória quanto a atribuição aleatória, ou apenas uma dessas técnicas, ou nenhuma das técnicas. Um estudo forte é aquele que utiliza ambas as técnicas.
Os exemplos a seguir mostram como um estudo poderia usar ambas, uma ou nenhuma dessas técnicas e os efeitos resultantes.
Exemplo 1: Usando seleção aleatória e atribuição aleatória
Estudo: Os pesquisadores querem saber se uma nova dieta resulta em maior perda de peso do que uma dieta padrão em uma determinada comunidade de 10.000 pessoas. Eles recrutaram 100 pessoas para participarem do estudo usando um computador para selecionar aleatoriamente 100 nomes de um banco de dados. Depois de terem todos os 100 indivíduos, eles usam novamente um computador para atribuir aleatoriamente 50 indivíduos a um grupo de controle (por exemplo, seguindo a dieta padrão) e 50 indivíduos a um grupo de tratamento (por exemplo, seguindo a nova dieta). Eles registram a perda total de peso de cada indivíduo após um mês.
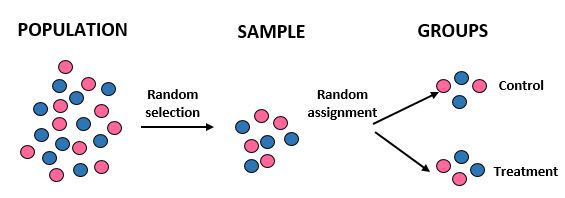
Resultados: Os pesquisadores usaram seleção aleatória para obter a amostra e atribuição aleatória ao colocar os indivíduos em um grupo de tratamento ou controle. Ao fazê-lo, são capazes de generalizar os resultados do estudo para a população em geral e atribuir as diferenças na perda média de peso entre os dois grupos à nova dieta.
Exemplo 2: Use apenas seleção aleatória
Estudo: Os pesquisadores querem saber se uma nova dieta resulta em maior perda de peso do que uma dieta padrão em uma determinada comunidade de 10.000 pessoas. Eles recrutaram 100 pessoas para participarem do estudo usando um computador para selecionar aleatoriamente 100 nomes de um banco de dados. No entanto, eles decidem dividir os indivíduos em grupos com base apenas no seu género. As mulheres são designadas para o grupo de controle e os homens para o grupo de tratamento. Eles registram a perda total de peso de cada indivíduo após um mês.
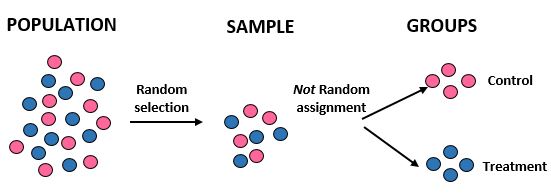
Resultados: Os pesquisadores usaram seleção aleatória para obter a amostra, mas não usaram atribuição aleatória ao colocar os indivíduos em um grupo de tratamento ou controle. Em vez disso, utilizaram um factor específico – o género – para decidir a que grupo atribuir os indivíduos. Ao fazê-lo, conseguem generalizar os resultados do estudo para a população em geral, mas não conseguem atribuir à nova dieta as diferenças na perda média de peso entre os dois grupos. A validade interna do estudo foi comprometida porque a diferença na perda de peso pode, na verdade, ser simplesmente devida ao sexo e não à nova dieta.
Exemplo 3: Use apenas atribuição aleatória
Estudo: Os pesquisadores querem saber se uma nova dieta resulta em maior perda de peso do que uma dieta padrão em uma determinada comunidade de 10.000 pessoas. Eles estão recrutando 100 atletas do sexo masculino para participar do estudo. Em seguida, eles usaram um programa de computador para designar aleatoriamente 50 atletas do sexo masculino para um grupo de controle e 50 para o grupo de tratamento. Eles registram a perda total de peso de cada indivíduo após um mês.
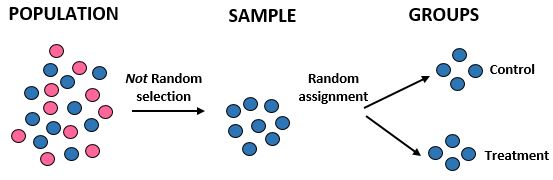
Resultados: Os pesquisadores não utilizaram seleção aleatória para obter a amostra, pois escolheram especificamente 100 atletas do sexo masculino. Por esta razão, a sua amostra não é representativa da população em geral e a sua validade externa fica, portanto, comprometida – não serão capazes de generalizar os resultados do estudo para a população em geral. No entanto, eles usaram alocação aleatória, o que significa que podem atribuir qualquer diferença na perda de peso à nova dieta.
Exemplo 4: não use nenhuma técnica
Estudo: Os pesquisadores querem saber se uma nova dieta resulta em maior perda de peso do que uma dieta padrão em uma determinada comunidade de 10.000 pessoas. Eles estão recrutando 50 atletas do sexo masculino e 50 atletas do sexo feminino para participarem do estudo. Em seguida, eles designaram todas as atletas femininas para o grupo de controle e todos os atletas masculinos para o grupo de tratamento. Eles registram a perda total de peso de cada indivíduo após um mês.
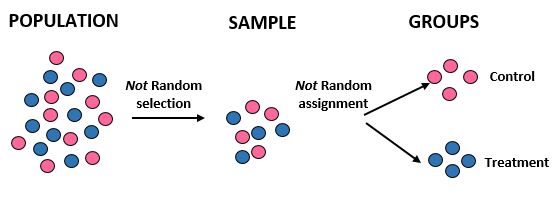
Resultados: Os pesquisadores não utilizaram seleção aleatória para obter a amostra, pois escolheram especificamente 100 atletas. Por esta razão, a sua amostra não é representativa da população em geral e a sua validade externa fica, portanto, comprometida – não serão capazes de generalizar os resultados do estudo para a população em geral. Além disso, dividem os indivíduos em grupos com base no sexo, em vez de se basearem em atribuições aleatórias, o que significa que a sua validade interna também fica comprometida – as diferenças na perda de peso podem dever-se ao sexo e não à dieta.
About Author
Dr. benjamim anderson
Olá, sou Benjamin, um professor aposentado de estatística que se tornou professor dedicado na Statorials. Com vasta experiência e conhecimento na área de estatística, estou empenhado em compartilhar meu conhecimento para capacitar os alunos por meio de Statorials. Saber mais