Como realizar um teste chow em r
Um teste de Chow é usado para testar se os coeficientes de dois modelos de regressão diferentes em conjuntos de dados diferentes são iguais.
Este teste é normalmente usado no campo da econometria com dados de séries temporais para determinar se há uma quebra estrutural nos dados em um determinado momento.
Este tutorial fornece um exemplo passo a passo de como realizar um teste Chow em R.
Etapa 1: crie os dados
Primeiro, criaremos dados falsos:
#create data data <- data.frame(x = c(1, 1, 2, 3, 4, 4, 5, 5, 6, 7, 7, 8, 8, 9, 10, 10, 11, 12, 12, 13, 14, 15, 15, 16, 17, 18, 18, 19, 20, 20), y = c(3, 5, 6, 10, 13, 15, 17, 14, 20, 23, 25, 27, 30, 30, 31, 33, 32, 32, 30, 32, 34, 34, 37, 35, 34, 36, 34, 37, 38, 36)) #view first six rows of data head(data) xy 1 1 3 2 1 5 3 2 6 4 3 10 5 4 13 6 4 15
Etapa 2: visualize os dados
A seguir, criaremos um gráfico de dispersão simples para visualizar os dados:
#load ggplot2 visualization package library (ggplot2) #create scatterplot ggplot(data, aes (x = x, y = y)) + geom_point(col=' steelblue ', size= 3 )
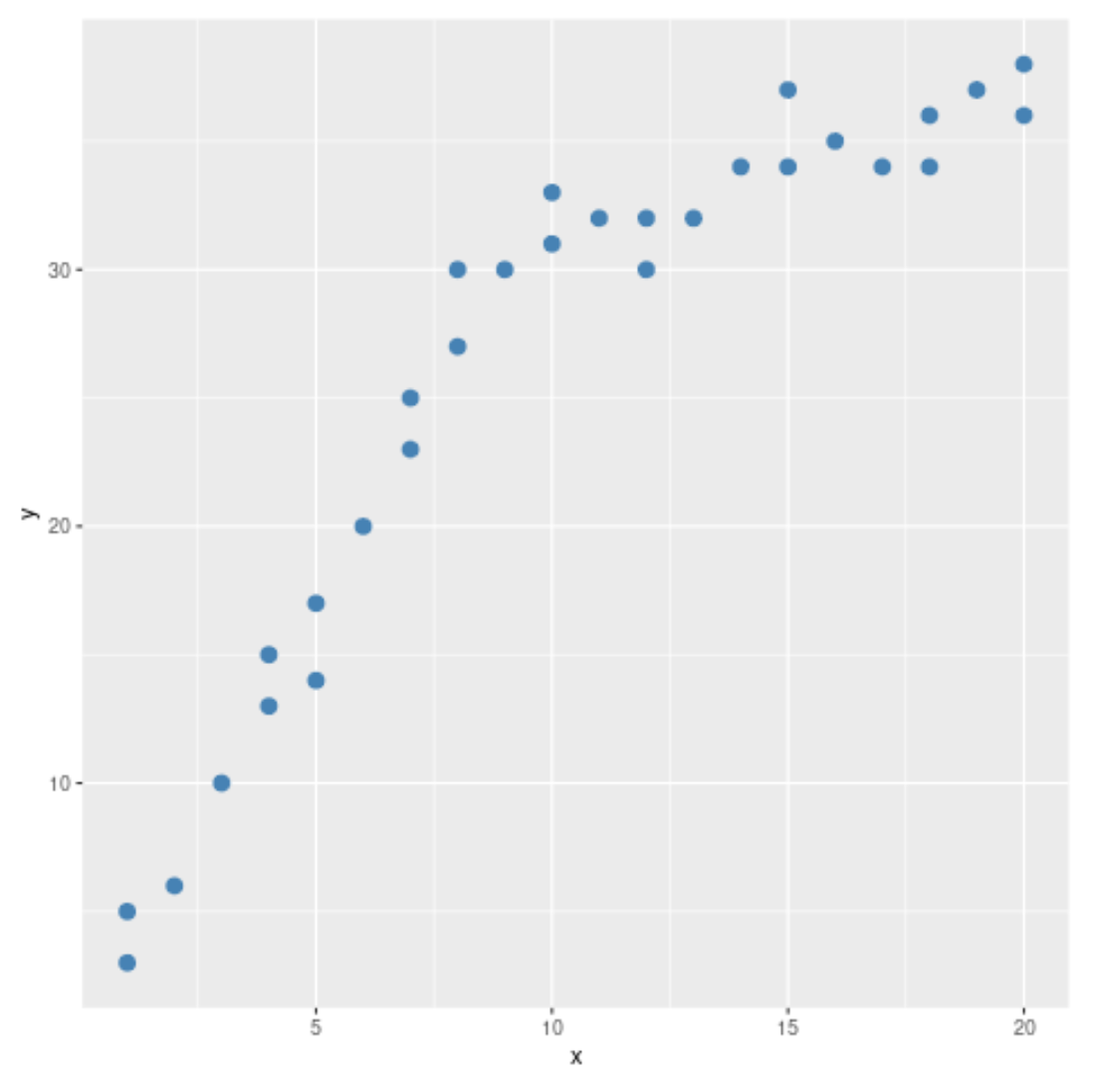
No gráfico de dispersão, podemos ver que o padrão nos dados parece mudar em x = 10. Assim, podemos realizar o teste de Chow para determinar se há um ponto de quebra estrutural nos dados em x = 10.
Etapa 3: execute o teste de comida
Podemos usar a função sctest do pacote strucchange para realizar um teste Chow:
#load strucchange package library (strucchange) #perform Chow test sctest(data$y ~ data$x, type = " Chow ", point = 10 ) Chow test data: data$y ~ data$x F = 110.14, p-value = 2.023e-13
Pelo resultado do teste podemos ver:
- Estatística do teste F : 110,14
- valor p: <0,0000
Como o valor p é inferior a 0,05, podemos rejeitar a hipótese nula do teste. Isto significa que temos evidências suficientes para afirmar que um ponto de ruptura estrutural está presente nos dados.
Em outras palavras, duas linhas de regressão podem ajustar o modelo aos dados de forma mais eficaz do que uma única linha de regressão.
About Author
Dr. benjamim anderson
Olá, sou Benjamin, um professor aposentado de estatística que se tornou professor dedicado na Statorials. Com vasta experiência e conhecimento na área de estatística, estou empenhado em compartilhar meu conhecimento para capacitar os alunos por meio de Statorials. Saber mais