Дерево решений и случайные леса: в чем разница?
Дерево решений — это тип модели машинного обучения, используемый, когда связь между набором переменных-предикторов и переменной ответа является нелинейной.
Основная идея дерева решений заключается в построении «дерева» с использованием набора переменных-предикторов, которое прогнозирует значение переменной ответа с использованием правил принятия решений.
Например, мы могли бы использовать переменные-предсказатели «сыгранные годы» и «средний хоум-ран», чтобы спрогнозировать годовую зарплату профессиональных бейсболистов.
Используя этот набор данных, модель дерева решений может выглядеть следующим образом:
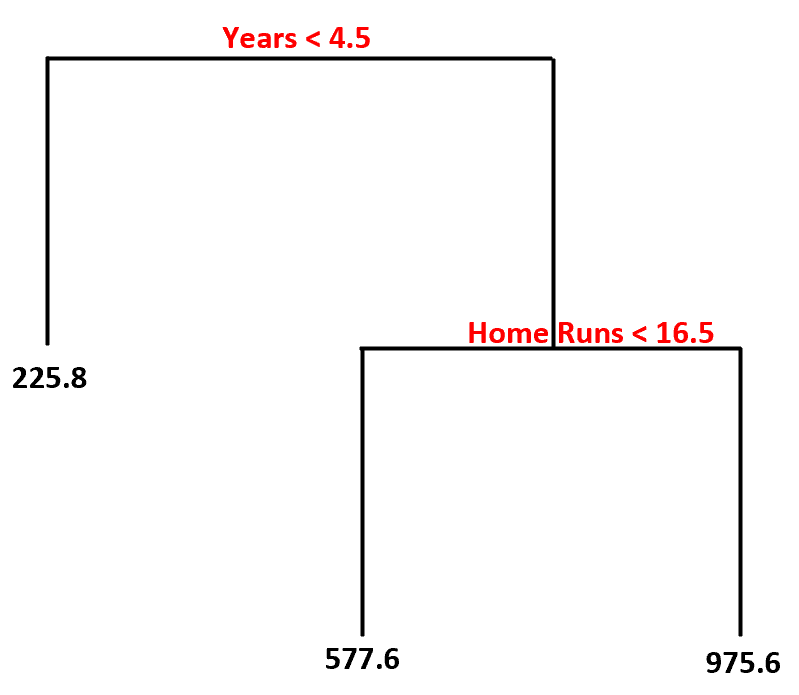
Вот как мы интерпретируем это дерево решений:
- Прогнозируемая зарплата игроков, играющих менее 4,5 лет, составит 225,8 тысяч долларов .
- Игроки, которые играли более 4,5 лет и более и совершали менее 16,5 хоум-ранов, в среднем имеют прогнозируемую зарплату в размере 577,6 тысяч долларов .
- Игроки с опытом 4,5 и более лет и в среднем 16,5 или более хоум-ранов имеют ожидаемую зарплату в размере 975,6 тысяч долларов .
Основное преимущество дерева решений заключается в том, что его можно быстро адаптировать к набору данных, а окончательную модель можно четко визуализировать и интерпретировать с помощью «деревовидной» диаграммы, подобной приведенной выше.
Основным недостатком является то, что дерево решений имеет тенденцию переопределять набор обучающих данных, а это означает, что оно, скорее всего, будет плохо работать с невидимыми данными. На это также могут сильно влиять выбросы в наборе данных.
Расширением дерева решений является модель, известная как случайный лес , которая по сути представляет собой набор деревьев решений.
Вот шаги, которые мы используем для создания модели случайного леса:
1. Возьмите самозагружаемые выборки из исходного набора данных.
2. Для каждой выборки начальной загрузки создайте дерево решений, используя случайное подмножество переменных-предикторов.
3. Усредните прогнозы каждого дерева, чтобы получить окончательную модель.
Преимущество случайных лесов заключается в том, что они, как правило, работают намного лучше, чем деревья решений, на невидимых данных и менее подвержены выбросам.
Недостатком случайных лесов является то, что нет возможности визуализировать окончательную модель, и их построение может занять много времени, если у вас недостаточно вычислительных мощностей или набор данных, с которым вы работаете, чрезвычайно громоздкий.
Преимущества и недостатки: деревья решений по сравнению с Случайные леса
В следующей таблице суммированы преимущества и недостатки деревьев решений по сравнению со случайными лесами:
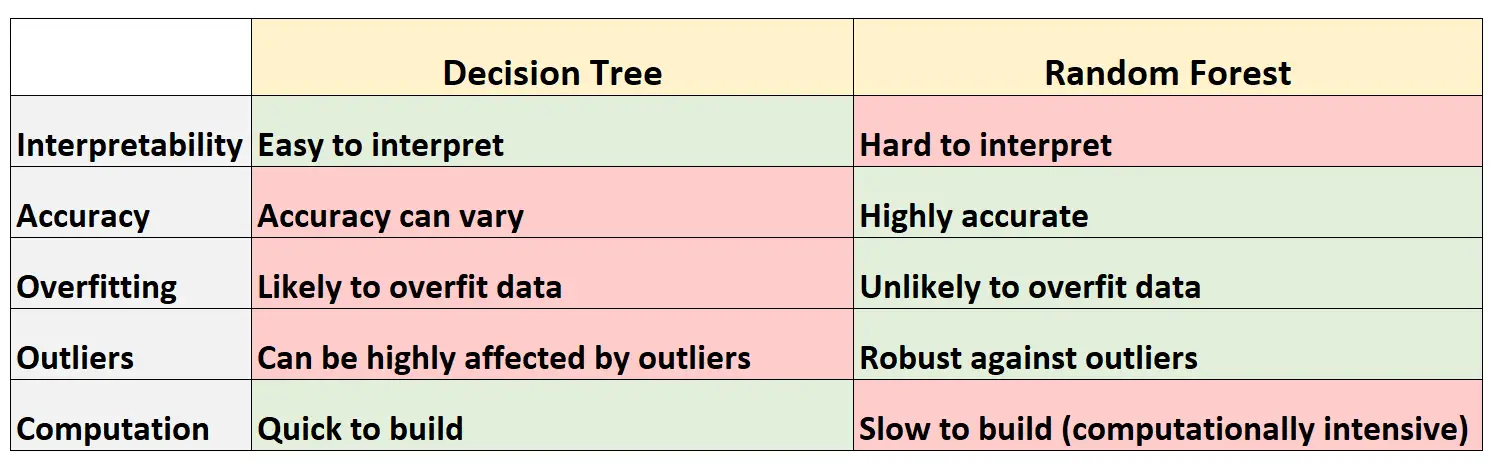
Вот краткое объяснение каждой строки таблицы:
1. Интерпретируемость
Деревья решений легко интерпретировать, поскольку мы можем создать древовидную диаграмму для визуализации и понимания окончательной модели.
И наоборот, мы не можем визуализировать случайный лес, и часто бывает трудно понять, как окончательная модель случайного леса принимает решения.
2. Точность
Поскольку деревья решений, скорее всего, не будут соответствовать набору обучающих данных, они, как правило, хуже работают с невидимыми наборами данных.
И наоборот, случайные леса, как правило, очень точны на невидимых наборах данных, поскольку они избегают переобучения наборов обучающих данных.
3. Переобучение
Как упоминалось ранее, деревья решений часто соответствуют обучающим данным: это означает, что они, скорее всего, адаптируются к «шуму» набора данных, в отличие от истинной базовой модели.
И наоборот, поскольку случайные леса используют только определенные переменные-предикторы для построения каждого отдельного дерева решений, окончательные деревья имеют тенденцию быть украшенными, а это означает, что модели случайного леса вряд ли будут соответствовать наборам данных.
4. Выбросы
Деревья решений очень чувствительны к выбросам.
И наоборот, поскольку модель случайного леса строит множество отдельных деревьев решений, а затем берет среднее значение прогнозов на основе этих деревьев, на нее гораздо меньше влияют выбросы.
5. Расчет
Деревья решений можно быстро адаптировать к наборам данных.
И наоборот, случайные леса требуют гораздо больше вычислительных ресурсов, и их создание может занять много времени в зависимости от размера набора данных.
Когда использовать деревья решений или случайные леса
В целом:
Вам следует использовать дерево решений , если вы хотите быстро создать нелинейную модель и иметь возможность легко интерпретировать, как модель принимает решения.
Однако вам следует использовать случайный лес, если у вас большие вычислительные мощности и вы хотите создать модель, которая, скорее всего, будет очень точной, не беспокоясь о том, как ее интерпретировать.
В реальном мире инженеры по машинному обучению и специалисты по обработке данных часто используют случайные леса, поскольку они очень точны, а современные компьютеры и системы часто могут обрабатывать большие наборы данных, с которыми раньше было невозможно справиться.
Дополнительные ресурсы
Следующие учебные пособия знакомят с деревьями решений и моделями случайного леса:
В следующих руководствах объясняется, как согласовать деревья решений и случайные леса в R:
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше