Полное руководство по набору данных diamond в r
Набор данных Diamond — это набор данных, встроенный в пакет ggplot2 в R.
Он содержит измерения по 10 различным переменным (таким как цена, цвет, чистота и т. д.) для 53 940 различных бриллиантов.
В этом руководстве объясняется, как исследовать, обобщать и визуализировать набор данных алмазов в R.
Загрузить набор данных алмазов
Поскольку набор данных Diamond является встроенным набором данных в ggplot2, нам сначала нужно установить (если еще не установили) и загрузить пакет ggplot2:
#install ggplot2 if not already installed
install. packages (' ggplot2 ')
#load ggplot2
library (ggplot2)
После загрузки ggplot2 мы можем использовать функцию data() для загрузки набора данных Diamond :
data(diamonds)
Мы можем просмотреть первые шесть строк набора данных с помощью функции head() :
#view first six rows of diamonds dataset
head(diamonds)
carat cut color clarity depth table price xyz
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
4 0.290 Premium I VS2 62.4 58 334 4.2 4.23 2.63
5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
Обобщить набор данных по алмазам
Мы можем использовать функцию summary() для быстрого суммирования каждой переменной в наборе данных:
#summarize diamonds dataset
summary(diamonds)
carat cut color clarity depth
Min. :0.2000 Fair: 1610 D: 6775 SI1:13065 Min. :43.00
1st Qu.:0.4000 Good: 4906 E: 9797 VS2:12258 1st Qu.:61.00
Median: 0.7000 Very Good: 12082 F: 9542 SI2: 9194 Median: 61.80
Mean: 0.7979 Premium: 13791 G: 11292 VS1: 8171 Mean: 61.75
3rd Qu.:1.0400 Ideal:21551 H:8304 VVS2:5066 3rd Qu.:62.50
Max. :5.0100 I: 5422 VVS1: 3655 Max. :79.00
D: 2808 (Other): 2531
table price xyz Min. :43.00 Min. : 326 Min. : 0.000 Min. : 0.000 Min. : 0.000
1st Qu.: 56.00 1st Qu.: 950 1st Qu.: 4.710 1st Qu.: 4.720 1st Qu.: 2.910
Median: 57.00 Median: 2401 Median: 5.700 Median: 5.710 Median: 3.530
Mean: 57.46 Mean: 3933 Mean: 5.731 Mean: 5.735 Mean: 3.539
3rd Qu.: 59.00 3rd Qu.: 5324 3rd Qu.: 6.540 3rd Qu.: 6.540 3rd Qu.: 4.040
Max. :95.00 Max. :18823 Max. :10,740 Max. :58,900 Max. :31,800
Для каждой из числовых переменных мы можем увидеть следующую информацию:
- Мин : минимальное значение.
- 1-й Цюй : значение первого квартиля (25-го процентиля).
- Медиана : медианное значение.
- Среднее : Среднее значение.
- 3-й Цюй : значение третьего квартиля (75-го процентиля).
- Макс : максимальное значение.
Для категориальных переменных в наборе данных (огранка, цвет и чистота) мы видим частоту каждого значения.
Например, для переменной Cut :
- Fair : это значение появляется 1610 раз.
- Хорошо : это значение появляется 4906 раз.
- Очень хорошо : это значение появляется 12 082 раза.
- Премиум : это значение появляется 13 791 раз.
- Идеально : это значение появляется 21 551 раз.
Мы можем использовать функцию dim() , чтобы получить размеры набора данных в виде количества строк и столбцов:
#display rows and columns
dim(diamonds)
[1] 53940 10
Мы видим, что набор данных содержит 53 940 строк и 10 столбцов.
Мы также можем использовать функцию Names() для отображения имен столбцов фрейма данных:
#display column names
names(diamonds)
[1] "carat" "cut" "color" "clarity" "depth" "table" "price" "x"
[9] “y” “z”
Визуализируйте набор данных Diamonds
Мы также можем создавать графики для визуализации значений набора данных.
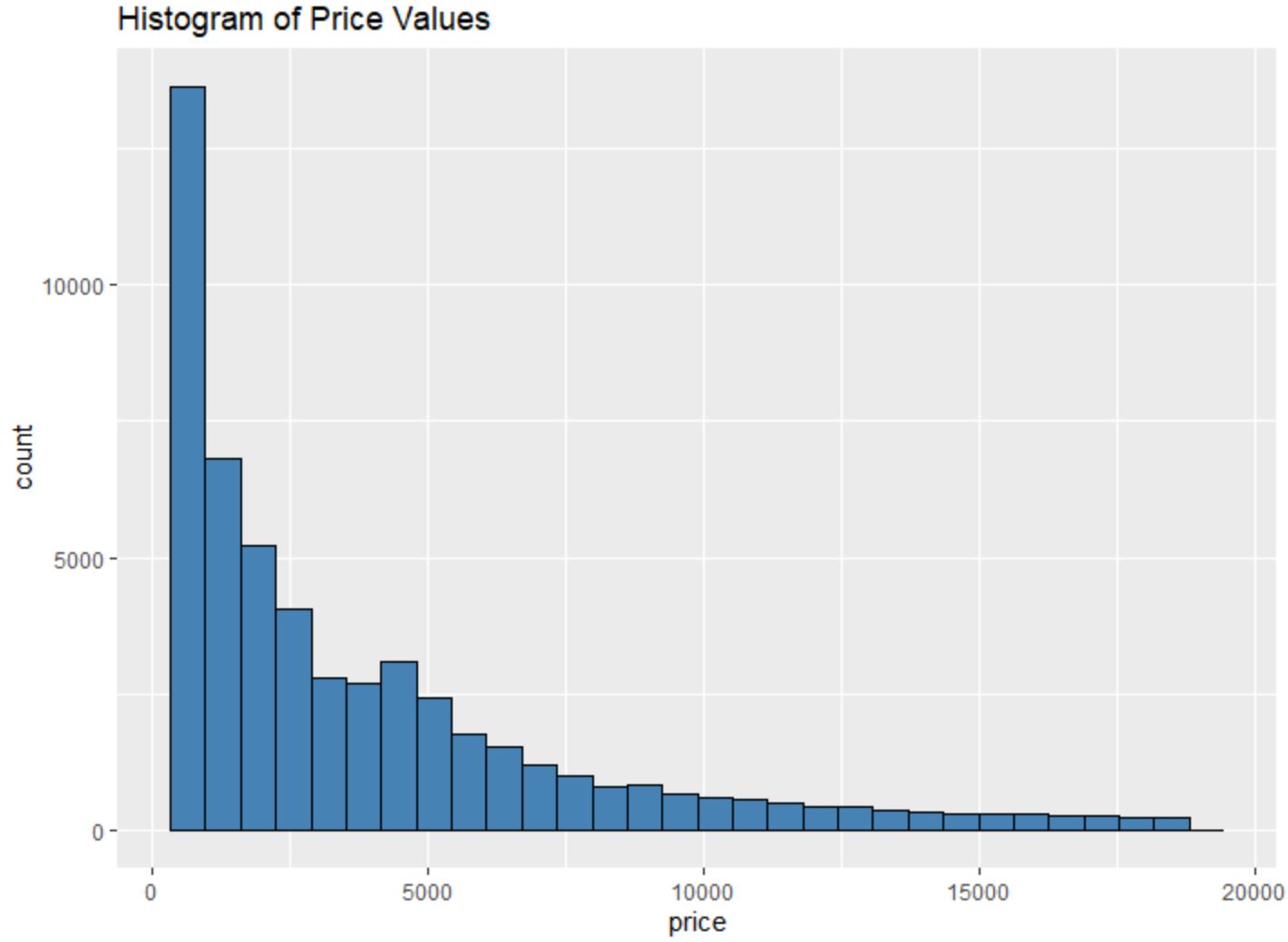
Например, мы можем использовать функцию geom_histogram() для создания гистограммы значений определенной переменной:
#create histogram of values for price
ggplot(data=diamonds, aes (x=price)) +
geom_histogram(fill=" steelblue ", color=" black ") +
ggtitle(" Histogram of Price Values ")
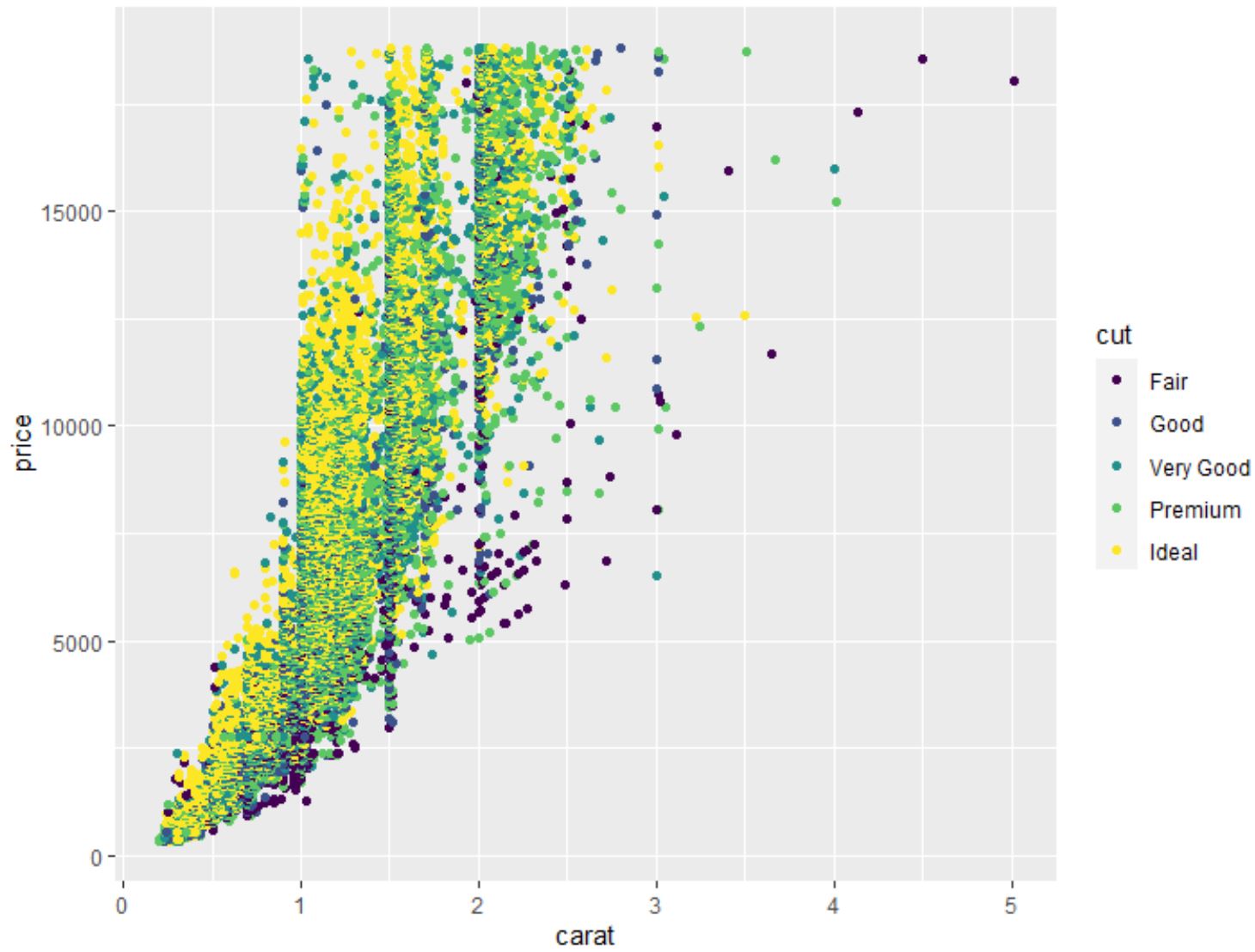
Мы также можем использовать функцию geom_point() для создания облака точек любой попарной комбинации переменных:
#create scatterplot of carat vs. price, using cut as color variable
ggplot(data=diamonds, aes (x=carat, y=price, color=cut)) +
geom_point()
Мы также можем использовать функцию geom_boxplot() для создания коробчатой диаграммы переменной, сгруппированной по другой переменной:
#create scatterplot of price, grouped by cut
ggplot(data=diamonds, aes (x=cut, y=price)) +
geom_boxplot(fill=" steelblue ")
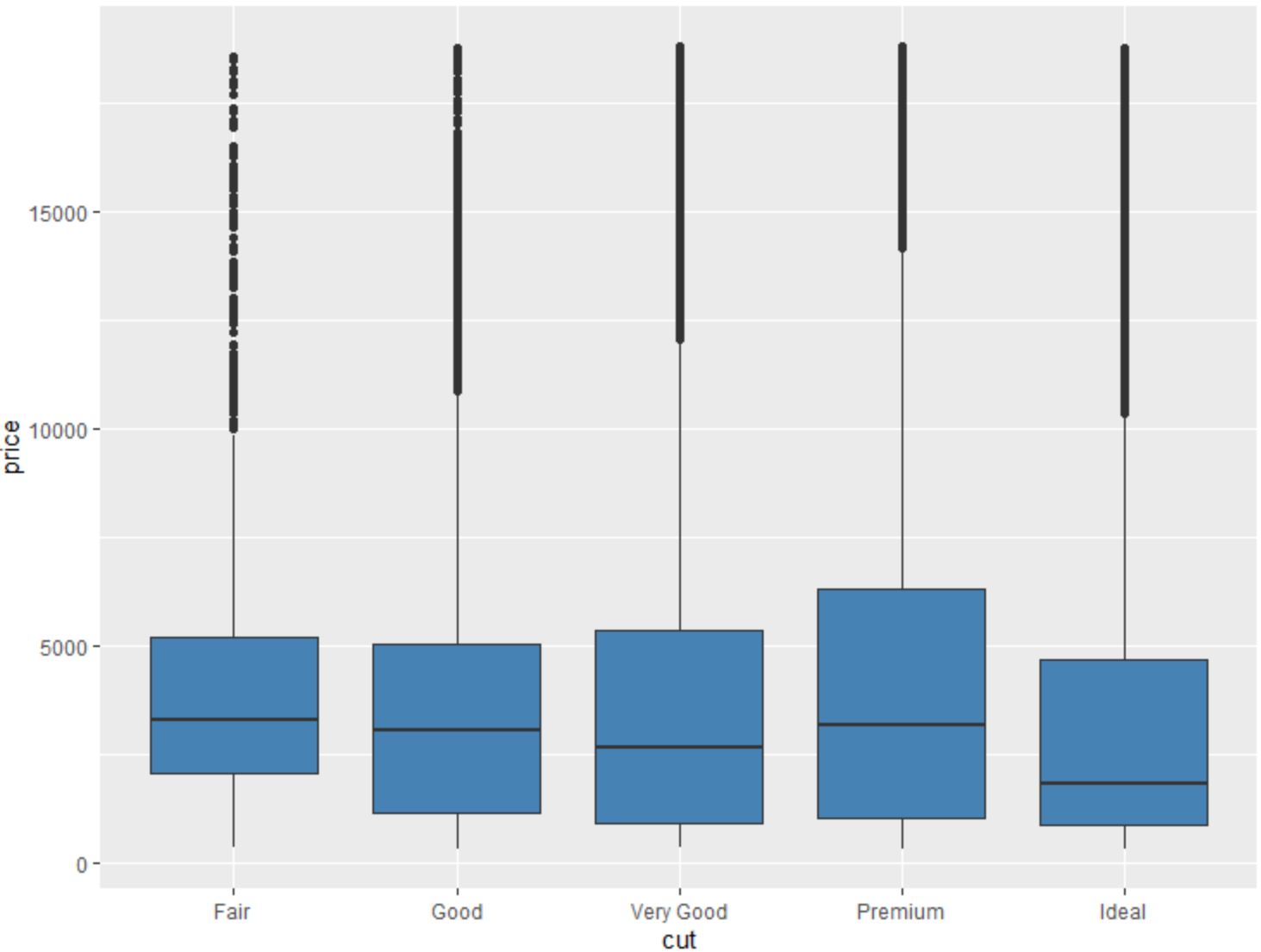
Используя эти функции ggplot2, мы можем многое узнать о переменных в наборе данных алмазов .
Дополнительные ресурсы
В следующих руководствах объясняется, как исследовать другие наборы данных в R:
Полное руководство по набору данных Iris в R
Полное руководство по набору данных mtcars в R
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше