Набор для проверки и набор для тестирования: в чем разница?
Всякий раз, когда мы адаптируем алгоритм машинного обучения к набору данных, мы обычно делим набор данных на три части:
1. Тренировочный набор : используется для обучения модели.
2. Набор проверки : используется для оптимизации параметров модели.
3. Тестовый набор : используется для получения несмещенной оценки окончательной производительности модели.
На следующей диаграмме представлено визуальное объяснение этих трех различных типов наборов данных:
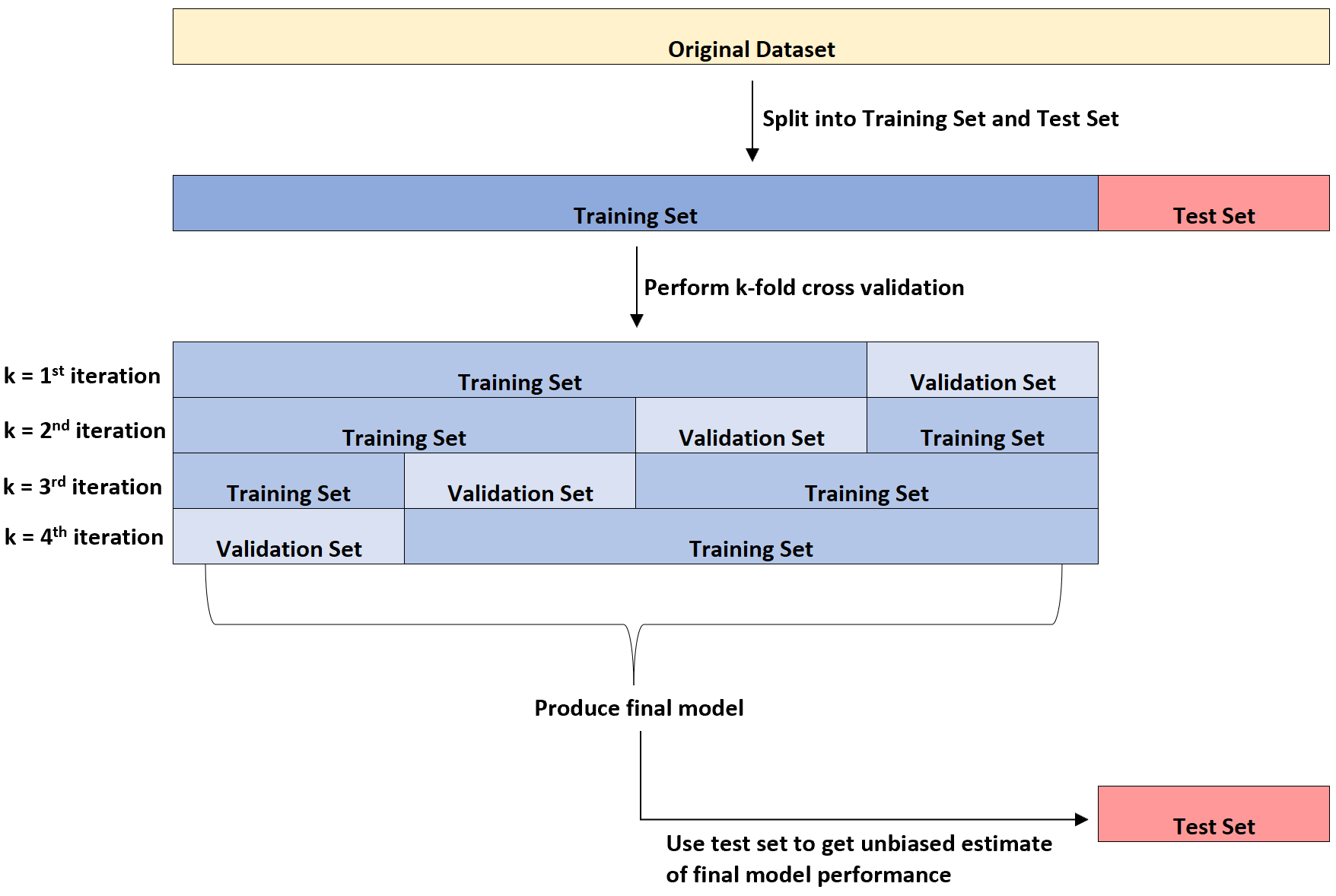
Одним из вопросов, вызывающих путаницу у студентов, является разница между набором проверки и набором тестов.
Проще говоря, набор проверки используется для оптимизации параметров модели, а набор тестов используется для обеспечения несмещенной оценки окончательной модели.
Можно показать, что частота ошибок, измеренная с помощью k-кратной перекрестной проверки, имеет тенденцию недооценивать истинную частоту ошибок, когда модель применяется к невидимому набору данных.
Таким образом, мы подгоняем окончательную модель к тестовому набору , чтобы получить объективную оценку того, какой будет истинная частота ошибок в реальном мире.
Следующий пример иллюстрирует разницу между набором проверки и набором тестов на практике.
Пример. Понимание разницы между набором проверки и набором тестов.
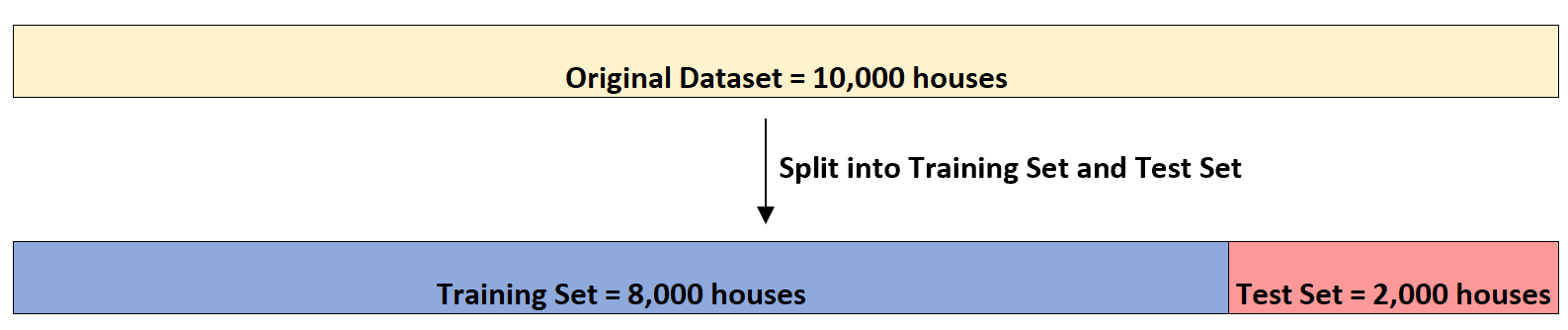
Допустим, инвестор в недвижимость хочет использовать (1) количество спален, (2) общее количество квадратных футов и (3) количество ванных комнат, чтобы спрогнозировать цену продажи данного дома.
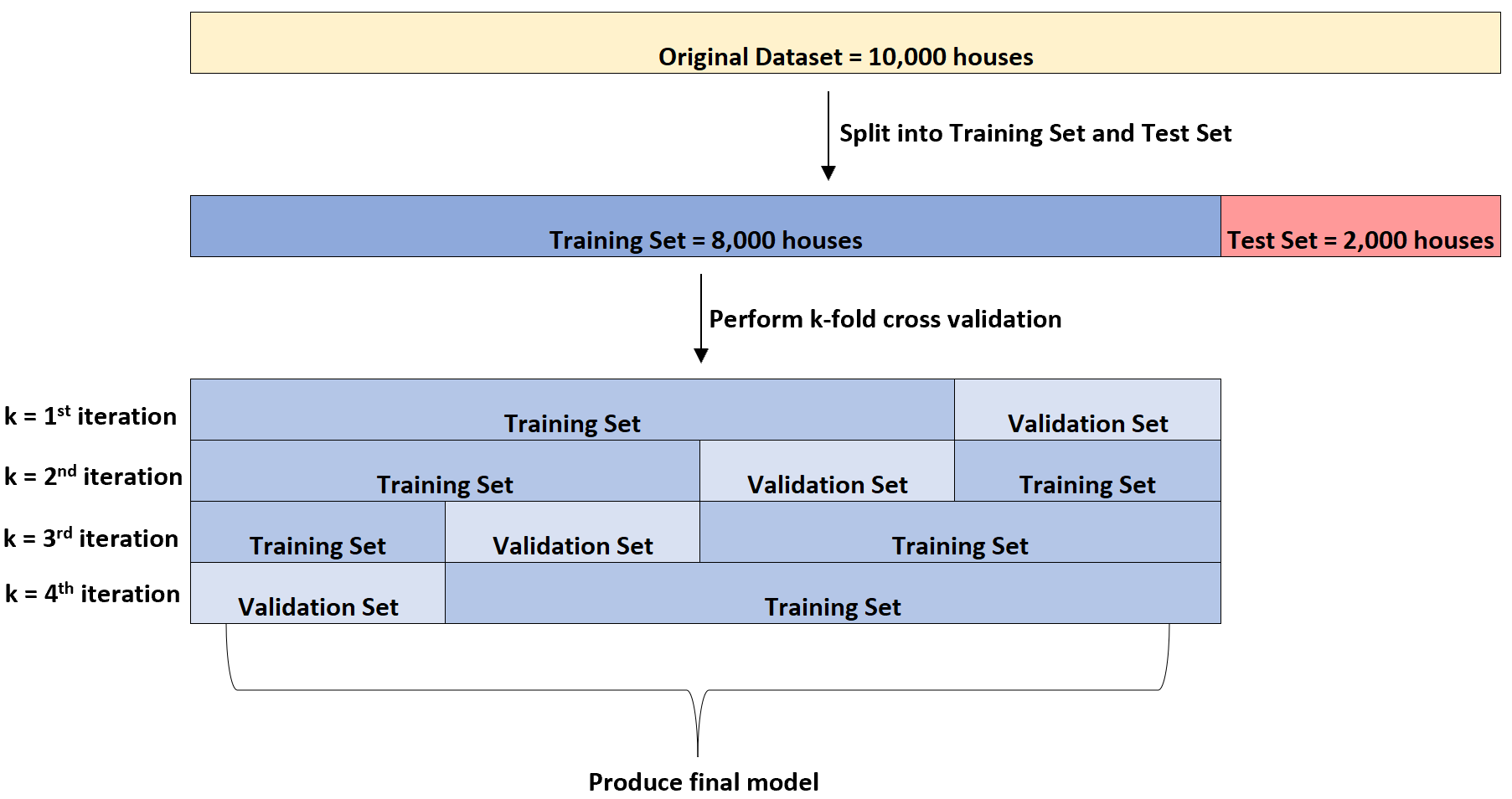
Допустим, у него есть набор данных с информацией о 10 000 домов. Во-первых, он разделит набор данных на обучающий набор из 8000 домов и тестовый набор из 2000 домов:
Затем он четыре раза подгонит модель множественной линейной регрессии к набору данных. Каждый раз он будет использовать 6000 домов для обучающего набора и 2000 домов для проверочного набора.
Это называется k-кратной перекрестной проверкой.
Обучающий набор используется для обучения модели, а проверочный набор используется для оценки производительности модели. Каждый раз для набора проверки будет использоваться другая группа из 2000 домов.
Он может выполнить эту k-кратную перекрестную проверку для нескольких различных типов регрессионных моделей, чтобы определить модель с наименьшей ошибкой (т. е. определить модель, которая лучше всего соответствует набору данных).
Только после того, как будет определена лучшая модель, она будет использовать тестовый набор из 2000 домов, представленный вначале, чтобы получить объективную оценку окончательных характеристик модели.
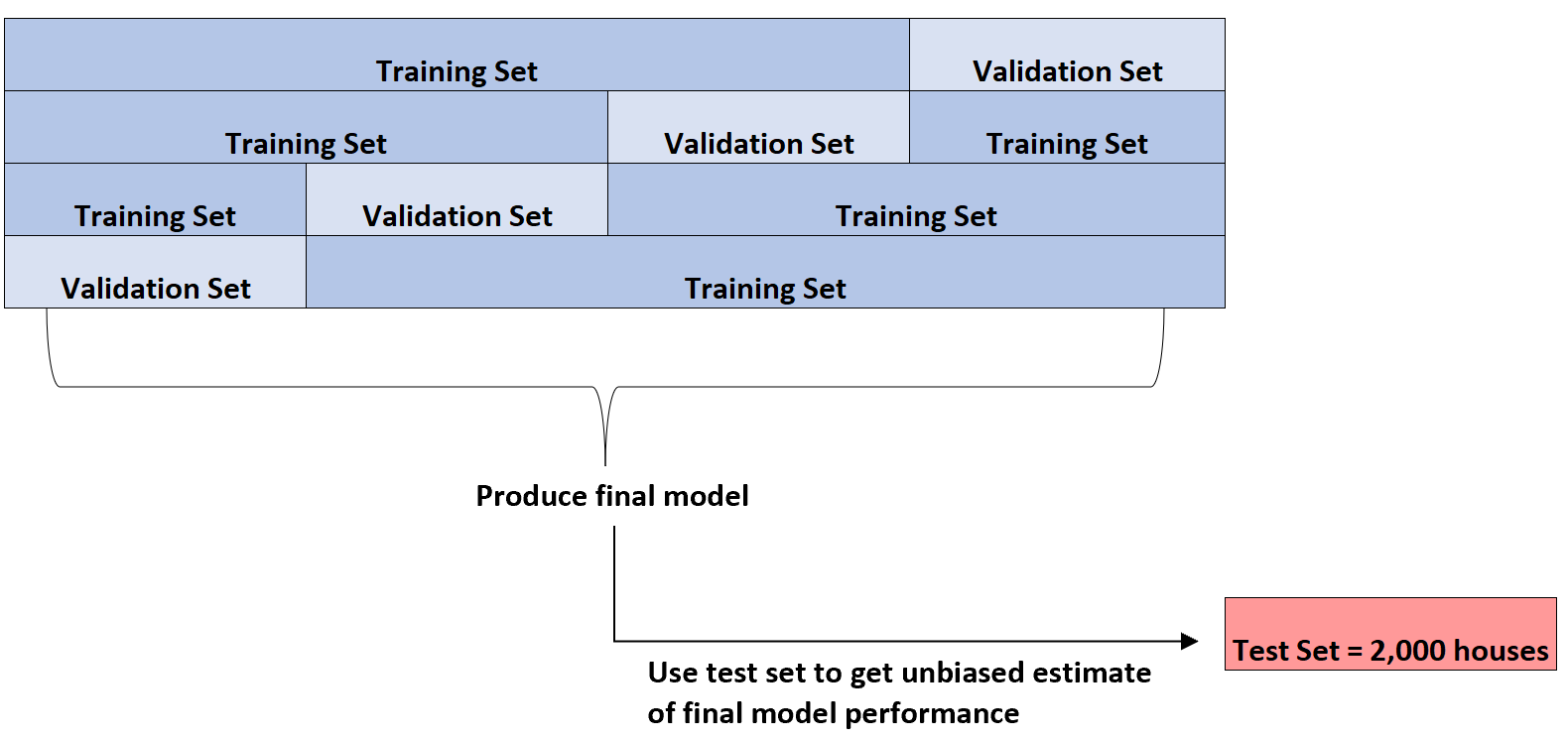
Например, он может идентифицировать конкретный тип регрессионной модели, средняя абсолютная ошибка которой составляет 8,345 . То есть средняя абсолютная разница между прогнозируемой ценой на жилье и фактической ценой на жилье составляет 8 345 долларов.
Затем он может подогнать эту точную модель регрессии к тестовому набору из 2000 домов, который еще не использовался, и обнаружить, что средняя абсолютная ошибка модели составляет 8,847 .
Таким образом, несмещенная оценка истинной средней абсолютной ошибки модели составляет 8847 долларов.
Дополнительные ресурсы
Простое руководство по перекрестной проверке K-Fold
Как выполнить перекрестную проверку K-Fold в Python
Как выполнить перекрестную проверку K-Fold в R
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше