Pandas: игнорировать определенные столбцы при импорте файла excel
Вы можете использовать следующий базовый синтаксис, чтобы игнорировать определенные столбцы при импорте файла Excel в DataFrame pandas:
#define columns to skip skip_cols = [1, 2] #define columns to keep keep_cols = [i for i in range (4) if i not in skip_cols] #import Excel file and skip specific columns df = pd. read_excel (' my_data.xlsx ', usecols=keep_cols)
В этом конкретном примере столбцы в позициях индекса 1 и 2 будут игнорироваться при импорте файла Excel с именем my_data.xlsx в pandas.
В следующем примере показано, как использовать этот синтаксис на практике.
Пример. Игнорируйте определенные столбцы при импорте файла Excel в Pandas.
Допустим, у нас есть следующий файл Excel с именем player_data.xlsx :
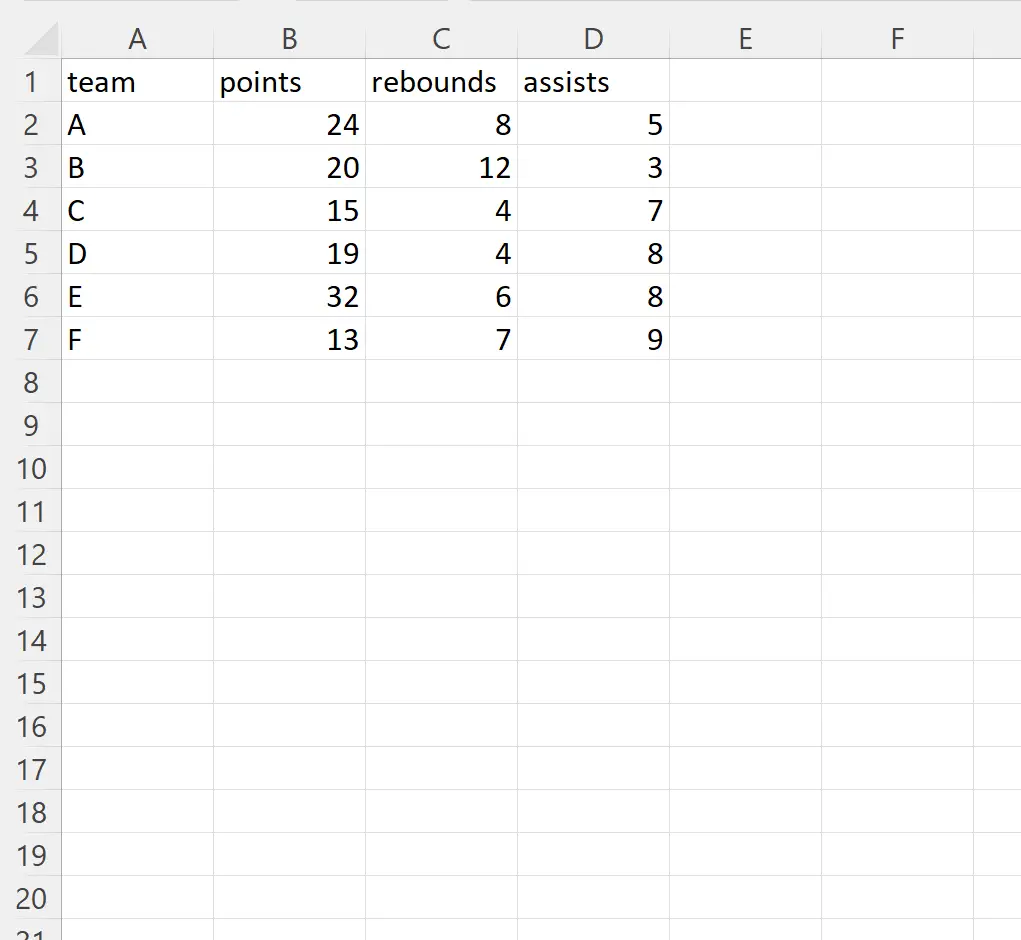
Мы можем использовать следующий синтаксис, чтобы импортировать этот файл в DataFrame pandas и игнорировать столбцы в индексных позициях 1 и 2 (столбцы с точками и отскоками) во время импорта:
#define columns to skip skip_cols = [1, 2] #define columns to keep keep_cols = [i for i in range (4) if i not in skip_cols] #import Excel file and skip specific columns df = pd. read_excel (' player_data.xlsx ', usecols=keep_cols) #view DataFrame print (df) team assists 0 to 5 1 B 3 2 C 7 3 D 8 4 E 8 5 F 9
Обратите внимание, что все столбцы в файле Excel, за исключением столбцов в позициях индекса 1 и 2 (столбцы точек и отскоков), были импортированы в DataFrame pandas.
Обратите внимание: этот метод предполагает, что вы заранее знаете, сколько столбцов находится в файле Excel.
Поскольку мы знали, что всего в файле 4 столбца, мы использовали диапазон (4) , чтобы определить столбцы, которые мы хотели сохранить.
Примечание . Полную документацию по функции pandas read_excel() можно найти здесь .
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные задачи в pandas:
Pandas: как пропускать строки при чтении файла Excel
Pandas: как указать типы при импорте файла Excel
Pandas: как объединить несколько листов Excel
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше