Регрессия или классификация: в чем разница?
Алгоритмы машинного обучения можно разделить на два различных типа: алгоритмы обучения с учителем и без учителя .

Алгоритмы обучения с учителем можно разделить на два типа:
1. Регрессия: переменная отклика является непрерывной.
Например, переменная ответа может быть:
- Масса
- Высота
- Цена
- Время
- Всего единиц
В каждом случае регрессионная модель стремится предсказать непрерывную величину.
Пример регрессии:
Допустим, у нас есть набор данных, содержащий три переменные для 100 разных домов: площадь, количество ванных комнат и цена продажи.
Мы могли бы использовать регрессионную модель, которая использует квадратные метры и количество ванных комнат в качестве объясняющих переменных, а цену продажи — в качестве переменной ответа.
Затем мы могли бы использовать эту модель для прогнозирования продажной цены дома на основе его площади и количества ванных комнат.
Это пример регрессионной модели, поскольку переменная ответа (цена продажи) является непрерывной.
Самый распространенный способ измерения точности регрессионной модели — это расчет среднеквадратической ошибки (RMSE), показателя, который говорит нам, насколько в среднем далеки наши прогнозируемые значения от наблюдаемых значений в модели. Он рассчитывается следующим образом:
RMSE = √ Σ(P i – O i ) 2 / n
Золото:
- Σ — причудливый символ, означающий «сумма».
- Pi — прогнозируемое значение для i-го наблюдения.
- O i — наблюдаемое значение для i-го наблюдения
- n — размер выборки
Чем меньше RMSE, тем лучше регрессионная модель может соответствовать данным.
2. Классификация: переменная ответа является категориальной.
Например, переменная ответа может принимать следующие значения:
- Мужчина или женщина
- Успех или провал
- Низкий, средний или высокий
В каждом случае модель классификации пытается предсказать метку класса.
Пример классификации:
Допустим, у нас есть набор данных, содержащий три переменные для 100 разных баскетболистов колледжей: среднее количество очков за игру, уровень дивизиона и вопрос о том, были ли они выбраны в НБА или нет.
Мы могли бы адаптировать модель классификации, которая использует среднее количество очков за игру и за уровень дивизиона в качестве объясняющих переменных и «проектируется» в качестве переменной ответа.
Затем мы могли бы использовать эту модель, чтобы предсказать, будет ли выбран тот или иной игрок в НБА, основываясь на его среднем количестве очков за игру и уровне дивизиона.
Это пример модели классификации, поскольку переменная ответа («записанная») является категориальной. Другими словами, он может принимать значения только в двух разных категориях: «Написано» или «Не составлено».
Самый распространенный способ измерения точности модели классификации — это просто вычислить процент правильных классификаций, выполненных моделью:
Точность = корректирующие классификации / общее количество попыток классификации * 100 %.
Например, если модель правильно определяет, будет ли игрок выбран в НБА 88 раз из 100 возможных, то точность модели составит:
Точность = (88/100) * 100% = 88%
Чем выше точность, тем лучше модель классификации способна предсказывать результаты.
Сходства между регрессией и классификацией
Алгоритмы регрессии и классификации схожи в следующих отношениях:
- Оба являются алгоритмами обучения с учителем, то есть оба включают переменную отклика.
- Оба используют одну или несколько независимых переменных для создания моделей прогнозирования реакции.
- И то, и другое можно использовать, чтобы понять, как изменения значений независимых переменных влияют на значения переменной отклика.
Различия между регрессией и классификацией
Алгоритмы регрессии и классификации различаются следующим образом:
- Алгоритмы регрессии стремятся предсказать непрерывную величину, а алгоритмы классификации стремятся предсказать метку класса.
- То, как мы измеряем точность моделей регрессии и классификации, различается.
Преобразование регрессии в классификацию
Следует отметить, что задачу регрессии можно преобразовать в задачу классификации, просто разделив переменную ответа на отсеки.
Например, предположим, что у нас есть набор данных, который содержит три переменные: площадь в квадратных метрах, количество ванных комнат и цена продажи.
Мы могли бы построить регрессионную модель, используя квадратные метры и количество ванных комнат, чтобы спрогнозировать цены продажи.
Однако мы могли бы разделить цену продажи на три разных класса:
- 80 000–160 000 долларов США: «Низкая цена продажи».
- 161 000–240 000 долларов США: «Средняя цена продажи».
- 241 000–320 000 долларов США: «Высокая цена продажи».
Затем мы могли бы использовать квадратные метры и количество ванных комнат в качестве объясняющих переменных, чтобы предсказать, к какому классу (низкому, среднему или высокому) попадет продажная цена данного дома.
Это будет пример модели классификации, поскольку мы пытаемся отнести каждый дом к классу.
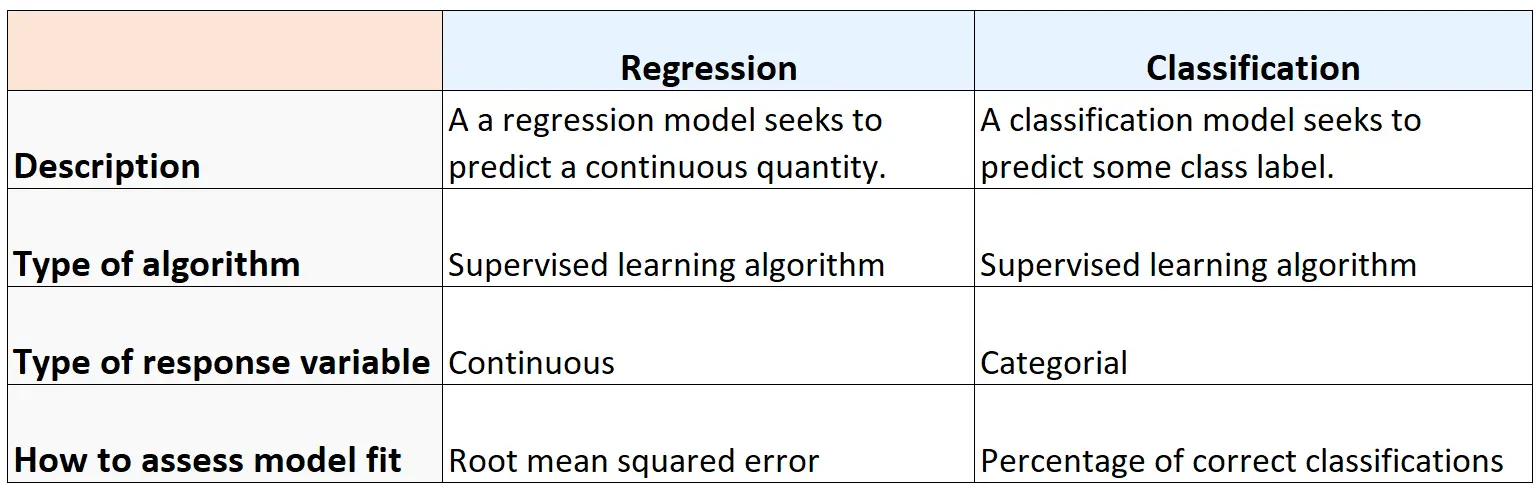
Краткое содержание
В следующей таблице приведены сходства и различия между алгоритмами регрессии и классификации:
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше