Ответ: как использовать пакет микротестов для измерения времени выполнения.
Вы можете использовать пакет microbenchmark в R для сравнения времени выполнения различных выражений.
Для этого вы можете использовать следующий синтаксис:
library (microbenchmark) #compare execution time of two different expressions microbenchmark( expression1, expression2) )
В следующем примере показано, как использовать этот синтаксис на практике.
Пример: использование microbenchmark() в R
Предположим, у нас есть следующий кадр данных в R, который содержит информацию об очках, набранных игроками различных баскетбольных команд:
#make this example reproducible
set. seed ( 1 )
#create data frame
df <- data. frame (team=rep(c(' A ', ' B '), each= 500 ),
points=rnorm( 1000 , mean= 20 ))
#view data frame
head(df)
team points
1 A 19.37355
2 A 20.18364
3 A 19.16437
4 A 21.59528
5 A 20.32951
6 A 19.17953
Теперь предположим, что мы хотим вычислить среднее количество очков, набранных игроками каждой команды, используя два разных метода:
- Метод 1 : используйте Aggregate() из Base R
- Способ 2 : используйте group_by() и summarise_at() из dplyr.
Мы можем использовать функцию microbenchmark() для измерения времени, необходимого для выполнения каждого из этих выражений:
library (microbenchmark) library (dplyr) #time how long it takes to calculate mean value of points by team microbenchmark( aggregate(df$points, list(df$team), FUN=mean), df %>% group_by(team) %>% summarise_at(vars(points), list(name = mean)) ) Unit: milliseconds express aggregate(df$points, list(df$team), FUN = mean) df %>% group_by(team) %>% summarise_at(vars(points), list(name = mean)) min lq mean median uq max neval cld 1.307908 1.524078 1.852167 1.743568 2.093813 4.67408 100 a 6.788584 7.810932 9.946286 8.914692 10.239904 56.20928 100 b
Функция microbenchmark() запускает каждое выражение 100 раз и измеряет следующие показатели:
- min : Минимальное время, необходимое для выполнения.
- lq : нижний квартиль (25-й процентиль) времени, необходимого для завершения.
- Среднее : среднее время, необходимое для выполнения.
- median : Среднее время выполнения
- uq : верхний квартиль (75-й процентиль) времени, необходимого для выполнения
- max : Максимальное время, необходимое для выполнения
- neval : сколько раз оценивалось каждое выражение.
Обычно мы смотрим только на среднее или медианное время, необходимое для выполнения каждого выражения.
По результату мы видим:
- Для расчета среднего командного балла с использованием метода R потребовалось в среднем 1852 миллисекунды .
- Для расчета среднего количества очков на команду с использованием метода dplyr потребовалось в среднем 9,946 миллисекунд .
На основании этих результатов мы делаем вывод, что базовый метод R работает значительно быстрее.
Мы также можем использовать функцию boxplot() для визуализации распределения времени, необходимого для выполнения каждого выражения:
library (microbenchmark) library (dplyr) #time how long it takes to calculate mean value of points by team results <- microbenchmark( aggregate(df$points, list(df$team), FUN=mean), df %>% group_by(team) %>% summarise_at(vars(points), list(name = mean)) ) #create boxplot to visualize results boxplot(results, names=c(' Base R ', ' dplyr '))
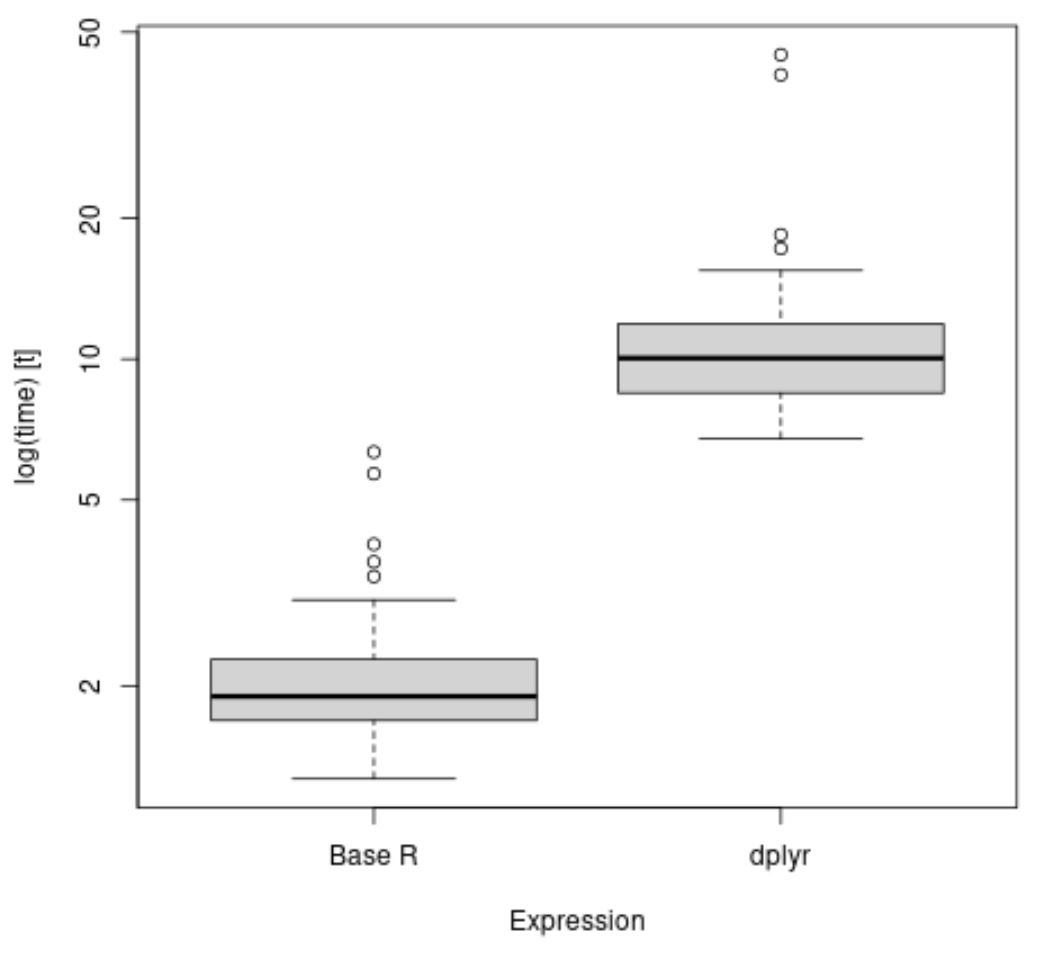
Из диаграмм мы видим, что метод dplyr в среднем занимает больше времени для расчета среднего значения очков на команду.
Примечание . В этом примере мы использовали функцию microbenchmark() для сравнения времени выполнения двух разных выражений, но на практике вы можете сравнивать столько выражений, сколько захотите.
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные задачи в R:
Как очистить среду в R
Как очистить все графики в RStudio
Как загрузить несколько пакетов в R
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше