Как рассчитать доверительные интервалы в sas
Доверительный интервал — это диапазон значений, который может содержать параметр совокупности с определенным уровнем достоверности.
В этом руководстве объясняется, как рассчитать следующие доверительные интервалы в R:
1. Доверительный интервал для генерального среднего значения
2. Доверительный интервал для разницы в генеральных средних
Пойдем!
Пример 1: Доверительный интервал для среднего генерального значения в SAS
Предположим, у нас есть следующий набор данных, содержащий высоту (в дюймах) случайной выборки из 12 растений, принадлежащих к одному и тому же виду:
/*create dataset*/ data my_data; inputHeight ; datalines ; 14 14 16 13 12 17 15 14 15 13 15 14 ; run ; /*view dataset*/ proc print data =my_data;
Предположим, мы хотим рассчитать уровень достоверности 95% для истинной средней численности популяции этого вида.
Для этого мы можем использовать следующий код в SAS:
/*generate 95% confidence interval for population mean*/ proc ttest data =my_data alpha = 0.05 ; varHeight ; run ;
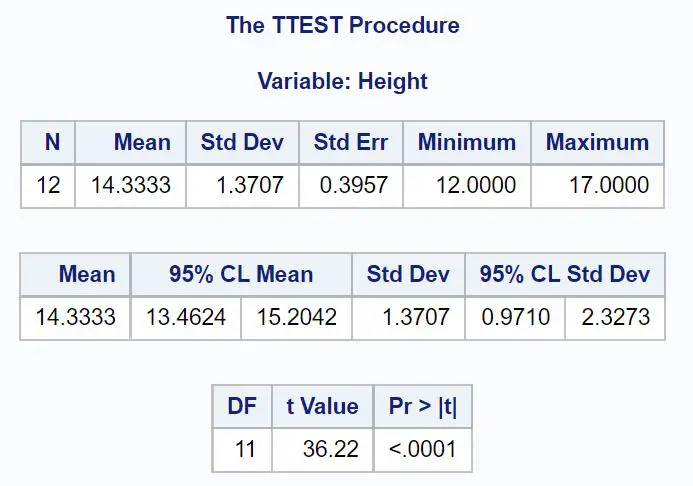
Значение Mean указывает выборочное среднее значение, а значения менее 95% CL Mean показывают 95% доверительный интервал для среднего генерального значения.
Из результатов мы видим, что 95% доверительный интервал для средней массы растений в этой популяции составляет [13,4624 дюйма, 15,2042 дюйма] .
Пример 2: Доверительный интервал для разницы в генеральных средних в SAS
Предположим, у нас есть следующий набор данных, содержащий высоту (в дюймах) случайной выборки растений, принадлежащих к двум разным видам:
/*create dataset*/
data my_data2;
input Species $Height;
datalines ;
At 14
At 14
At 16
At 13
AT 12
At 17
At 15
At 14
At 15
At 13
B15
B14
B 19
B 19
B17
B 18
B20
B 19
B17
B15
;
run ;
/*view dataset*/
proc print data =my_data2;
Предположим, мы хотим рассчитать уровень достоверности 95% для разницы в средней численности популяции между видами A и видами B.
Для этого мы можем использовать следующий код в SAS:
/*sort data by Species to ensure confidence interval is calculated correctly*/
proc sort data =my_data2;
by Species;
run ;
/*generate 95% confidence interval for difference in population means*/
proc ttest data =my_data2 alpha = 0.05 ;
class Species;
varHeight ;
run ;
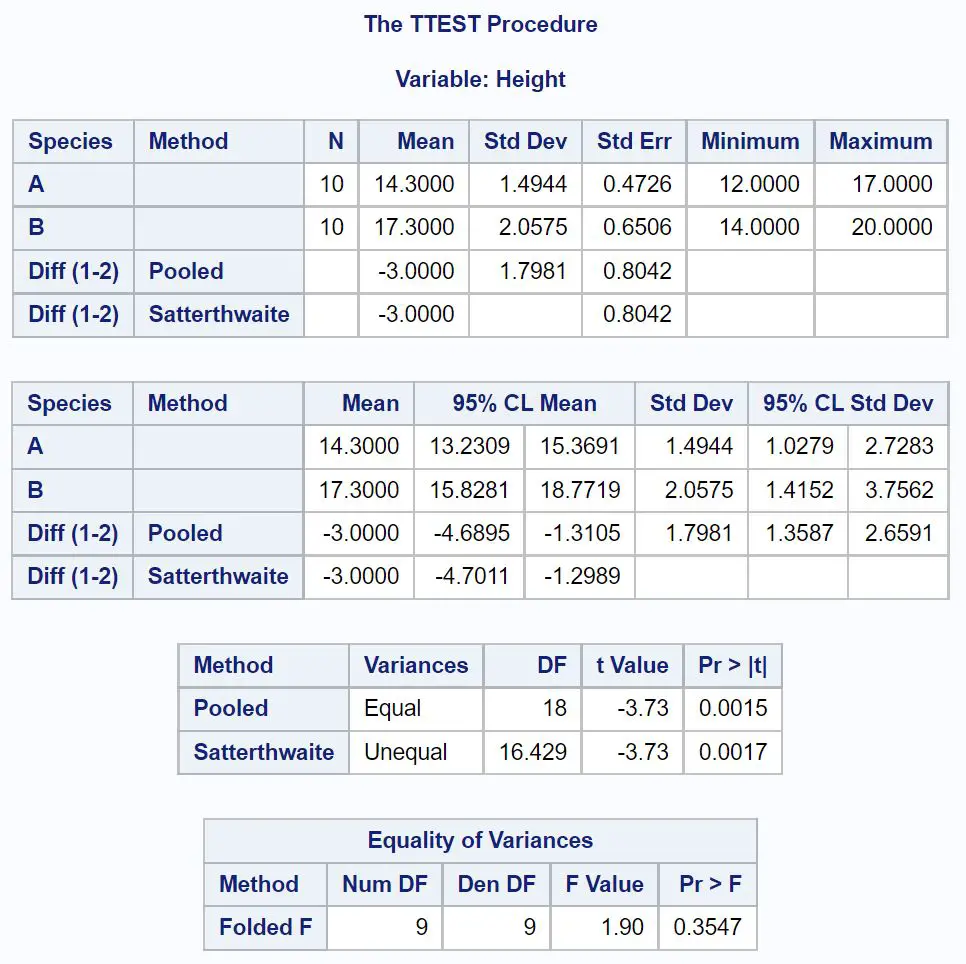
Первая таблица, на которую нам нужно взглянуть в результате, — это «Равенство дисперсий» , которая проверяет, равна ли дисперсия между каждой выборкой или нет.
Поскольку значение p в этой таблице составляет не менее 0,05, мы можем предположить, что различия между двумя группами равны.
Таким образом, мы можем посмотреть на линию, в которой используется объединенная дисперсия, чтобы найти 95% доверительный интервал для разницы в средних значениях генеральной совокупности.
Из результата мы видим, что 95% доверительный интервал для разницы между средними значениями генеральной совокупности составляет [-4,6895 дюйма, -1,1305 дюйма] .
Это говорит нам о том, что мы можем быть на 95% уверены, что истинная разница между средней высотой растений видов A и B составляет от -4,6895 дюймов до -1,1305 дюймов.
Поскольку 0 не находится в этом доверительном интервале , это указывает на то, что существует статистически значимая разница между средними значениями двух популяций.
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные задачи в SAS:
Как выполнить одновыборочный t-тест в SAS
Как выполнить t-тест с двумя выборками в SAS
Как выполнить t-тест парных выборок в SAS
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше