Что считается «хорошим»? результат ф1?
При использовании моделей классификации в машинном обучении общей метрикой, которую мы используем для оценки качества модели, является показатель F1 .
Этот показатель рассчитывается следующим образом:
Оценка F1 = 2 * (Точность * Отзыв) / (Точность + Отзыв)
Золото:
- Точность : правильные положительные прогнозы относительно общего числа положительных прогнозов.
- Напоминание : корректировка положительных прогнозов по сравнению с общим фактическим положительным результатом.
Например, предположим, что мы используем модель логистической регрессии, чтобы предсказать, будут ли 400 баскетболистов из разных колледжей выбраны в НБА.
Следующая матрица путаницы суммирует прогнозы, сделанные моделью:

Вот как можно рассчитать оценку модели в Формуле-1:
Точность = истинно положительный результат / (истинный положительный результат + ложный положительный результат) = 120/ (120+70) = 0,63157
Напомним = истинно положительный результат / (истинный положительный результат + ложный отрицательный результат) = 120 / (120 + 40) = 0,75.
Оценка F1 = 2 * (0,63157 * 0,75) / (0,63157 + 0,75) = . 6857
Что такое хороший результат в Формуле-1?
Студенты часто задают вопрос:
Что такое хороший результат в Формуле-1?
Проще говоря, чем выше результат в Формуле-1, тем лучше.
Напомним, что баллы F1 могут варьироваться от 0 до 1, где 1 представляет модель, которая идеально классифицирует каждое наблюдение в правильный класс, а 0 представляет модель, которая не может классифицировать наблюдение в правильный класс.
Чтобы проиллюстрировать это, предположим, что у нас есть модель логистической регрессии, которая создает следующую матрицу путаницы:
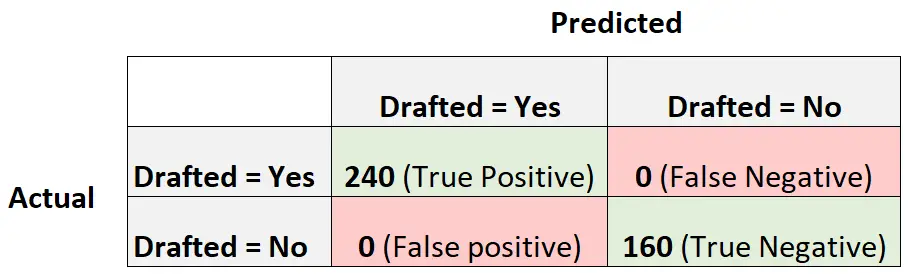
Вот как можно рассчитать оценку модели в Формуле-1:
Точность = истинное срабатывание / (истинное срабатывание + ложное срабатывание) = 240/ (240+0) = 1
Напомним = Истинно Положительный / (Истинно Положительный + Ложно Отрицательный) = 240 / (240+0) = 1
Оценка F1 = 2 * (1 * 1) / (1 + 1) = 1
Оценка F1 равна единице, поскольку она позволяет идеально классифицировать каждое из 400 наблюдений в класс.
Теперь рассмотрим другую модель логистической регрессии, которая просто предсказывает, что каждый игрок будет выбран на драфте:
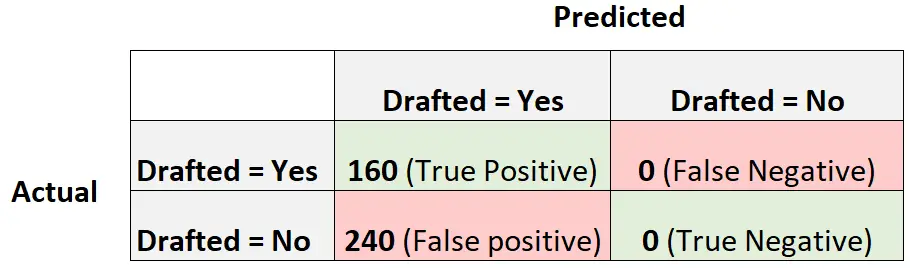
Вот как можно рассчитать оценку модели в Формуле-1:
Точность = истинное срабатывание / (истинное срабатывание + ложное срабатывание) = 160/ (160+240) = 0,4
Отзыв = Истинно положительный / (Истинно положительный + Ложно отрицательный) = 160 / (160 + 0) = 1
Оценка F1 = 2 * (0,4 * 1) / (0,4 + 1) = 0,5714
Это будет считаться базовой моделью , с которой мы могли бы сравнить нашу модель логистической регрессии, поскольку она представляет собой модель, которая делает один и тот же прогноз для каждого наблюдения в наборе данных.
Чем выше наш балл F1 по сравнению с эталонной моделью, тем полезнее наша модель.
Напомним, что ранее наша модель имела показатель F1 0,6857 . Это значение ненамного превышает 0,5714 , что указывает на то, что наша модель более полезна, чем базовая модель, но ненамного.
О сравнении результатов Формулы-1
На практике мы обычно используем следующий процесс для выбора «лучшей» модели для задачи классификации:
Шаг 1. Подберите эталонную модель, которая делает одинаковый прогноз для каждого наблюдения.
Шаг 2. Подберите несколько различных моделей классификации и рассчитайте оценку F1 для каждой модели.
Шаг 3. Выберите модель с наивысшим баллом F1 как «лучшую» модель, проверив, что она дает более высокий балл F1, чем эталонная модель.
Никакое конкретное значение не считается «хорошим» показателем F1, поэтому мы обычно выбираем модель классификации, которая дает наивысший балл F1.
Дополнительные ресурсы
Оценка F1 против точности: что использовать?
Как посчитать счет F1 в R
Как рассчитать оценку F1 в Python
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше