Как использовать proc cluster в sas (с примером)
Кластеризация — это метод машинного обучения, который пытается найти группы наблюдений в наборе данных.
Цель состоит в том, чтобы найти кластеры, в которых наблюдения внутри каждого кластера очень похожи друг на друга, а наблюдения в разных кластерах сильно отличаются друг от друга.
Самый простой способ выполнить кластеризацию в SAS — использовать PROC CLUSTER .
В следующем примере показано, как использовать PROC CLUSTER на практике.
Пример: Как использовать PROC CLUSTER в SAS
Допустим, у нас есть следующий набор данных, содержащий информацию об очках, передачах и подборах для 20 разных баскетболистов:
/*create dataset*/
data my_data;
input points assists rebounds;
datalines ;
18 3 15
20 3 14
19 4 14
14 5 10
14 4 8
15 7 14
20 8 13
28 7 9
30 6 5
31 9 4
35 12 11
33 14 6
29 9 5
25 9 5
25 4 3
27 3 8
29 4 12
30 12 7
19 5 6
23 11 5
;
run ;
/*view dataset*/
proc print data =my_data;
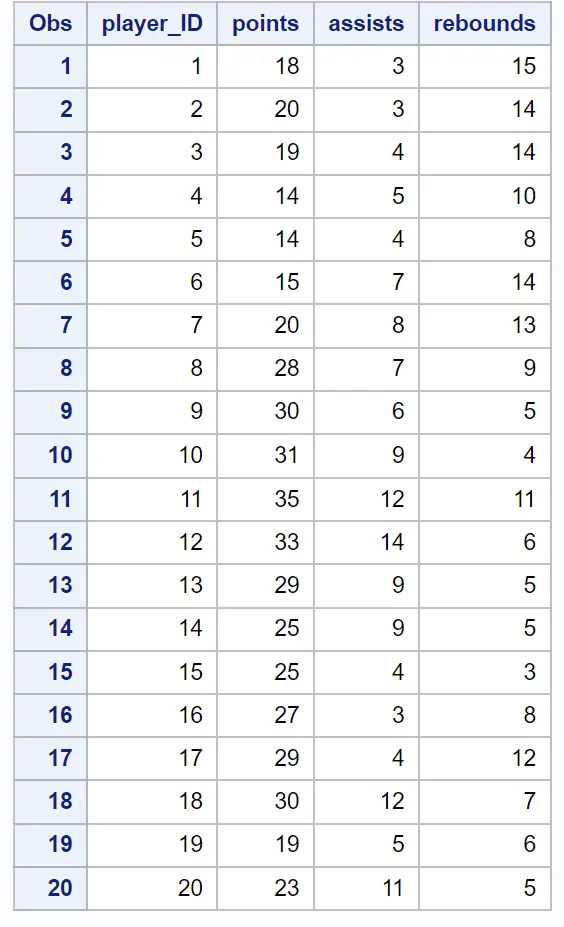
Допустим, мы хотим провести некоторую группировку, чтобы попытаться определить «кластеры» игроков со схожими характеристиками.
Следующий код показывает, как использовать PROC CLUSTER в SAS для выполнения кластеризации:
/*perform clustering using points, assists and rebounds variables*/
proc cluster data =my_data method =average;
var points assists rebounds;
run ;
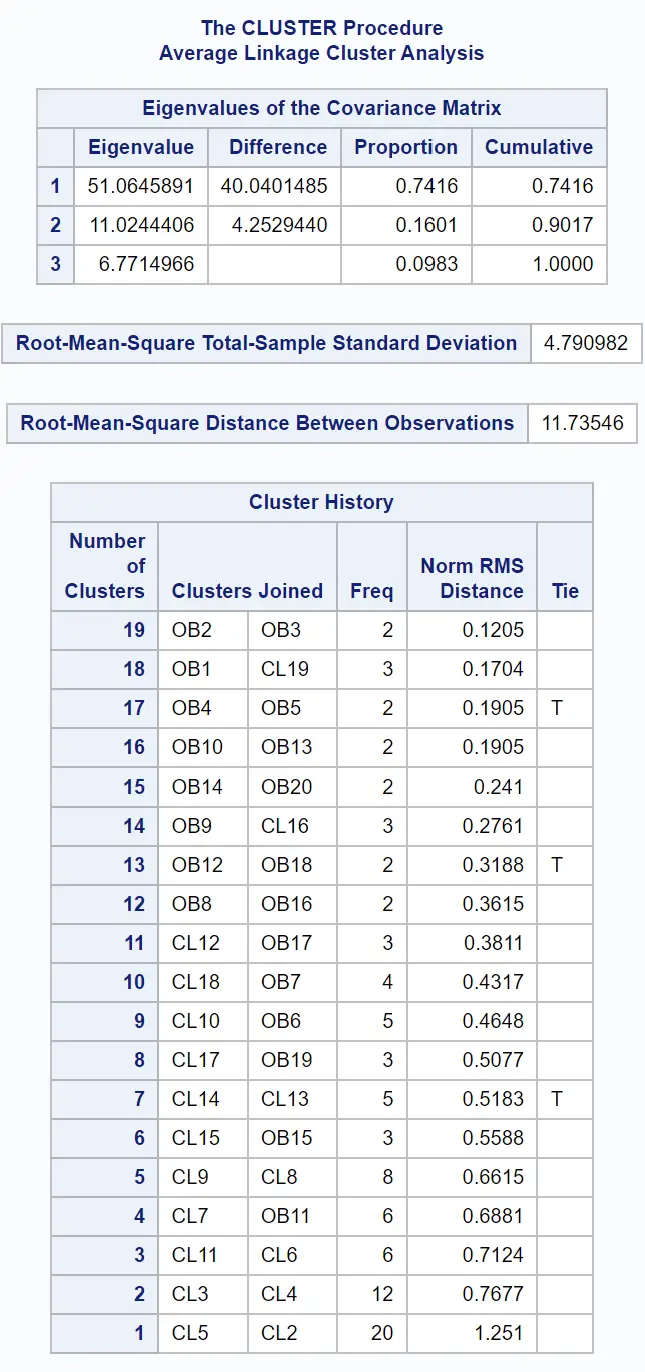
Первые таблицы результата предоставляют информацию о том, как проводилась кластеризация:
Также создается дендрограмма, чтобы мы могли визуально проверить сходство между наблюдениями в наборе данных:
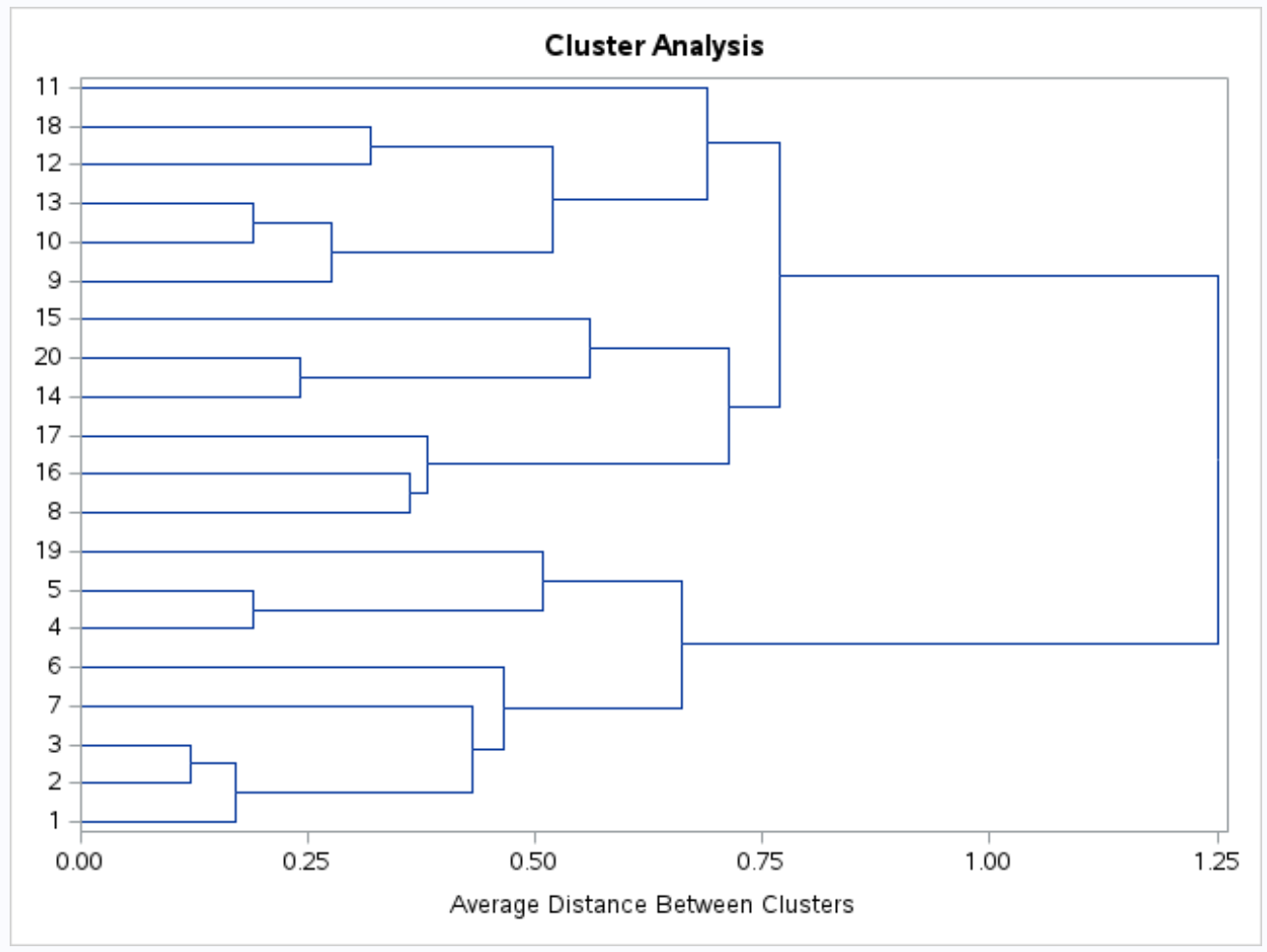
По оси Y показаны отдельные наблюдения, а по оси X показано среднее расстояние между кластерами.
Глядя на эту дендрограмму, кажется, что наблюдения естественным образом делятся на три группы:
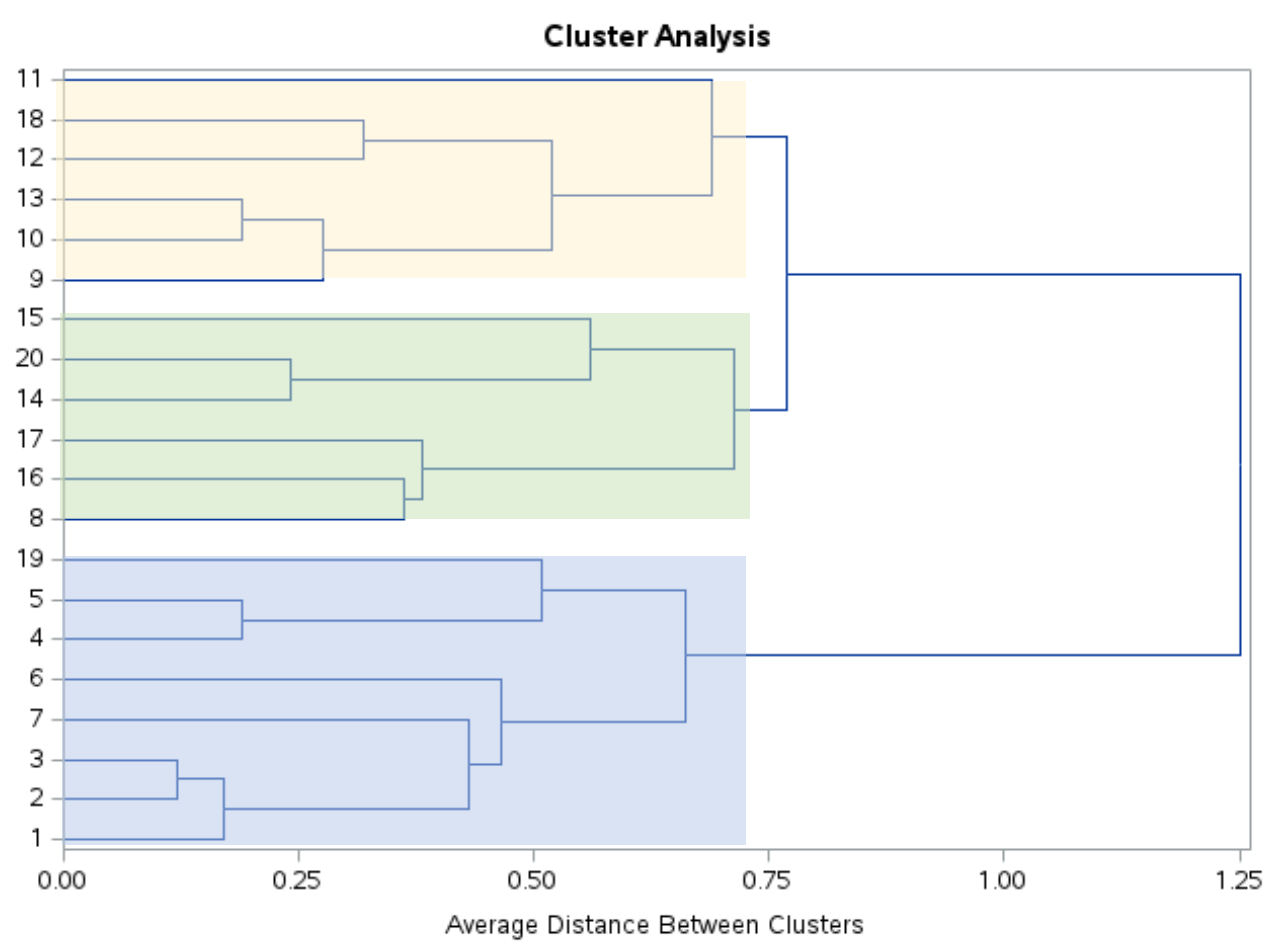
Затем мы можем использовать оператор PROC TREE с ncl=3 , чтобы указать SAS назначить каждое наблюдение в исходном наборе данных одному из трех кластеров:
/*assign each observation to one of three clusters*/
proc tree data =clustd noprint ncl =3 out =clusts;
copy points assists rebounds;
id player_ID;
run ;
proc sort ;
by cluster;
run ;
/*view cluster assignments*/
proc print data = clusters;
id player_ID;
run ;
Результирующий набор данных показывает каждое из исходных наблюдений вместе с кластером, к которому они принадлежат:
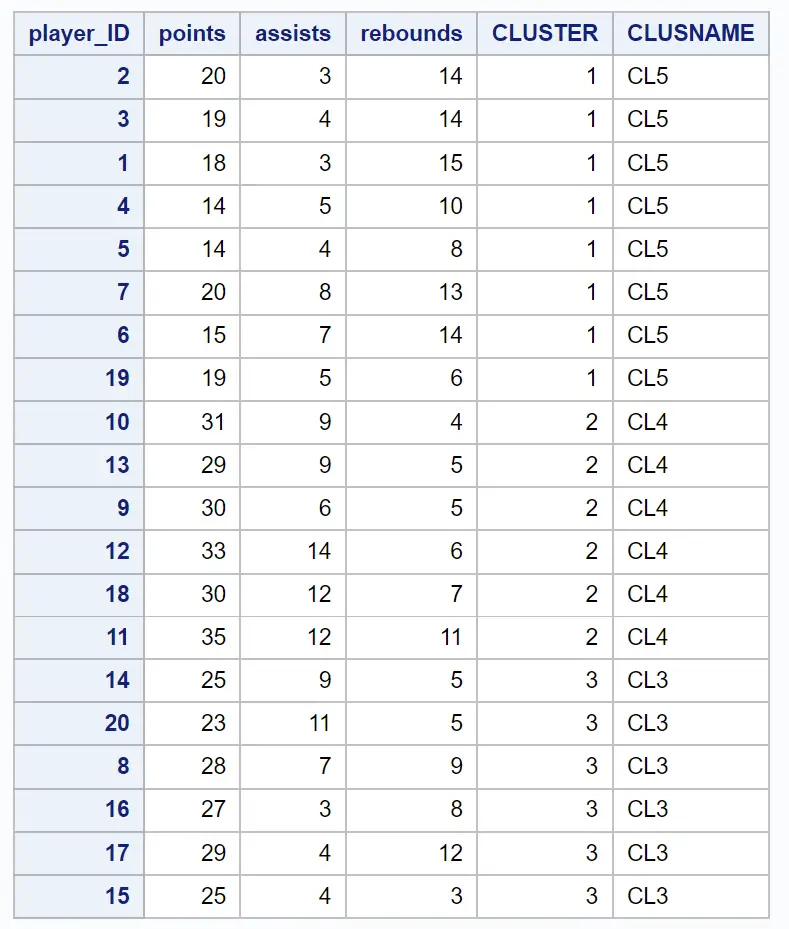
Например, мы можем видеть: все игроки с идентификаторами 2, 3, 1, 4, 5, 7, 6 и 19 принадлежат кластеру 1 .
Это говорит нам о том, что эти восемь игроков «похожи» с точки зрения набранных очков, передач и подборов.
Примечание . В этом примере мы решили использовать усреднение в качестве метода связывания для кластеризации. Полный список других методов привязки, которые вы можете использовать, см. в документации SAS .
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные задачи в SAS:
Как выполнить анализ главных компонентов в SAS
Как выполнить множественную линейную регрессию в SAS
Как выполнить логистическую регрессию в SAS
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше