Как использовать функцию логест в google таблицах (с примером)
Вы можете использовать функцию ЛИНГЕСТ в Google Таблицах, чтобы вычислить формулу экспоненциальной кривой, которая соответствует вашим данным.
Уравнение кривой примет следующий вид:
у = б* мх
Эта функция использует следующий базовый синтаксис:
= LOGEST ( known_data_y, [known_data_x], [b], [verbose] )
Золото:
- known_data_y : Массив известных значений y.
- known_data_x : Массив известных значений x.
- б : Необязательный аргумент. Если TRUE, константа b обрабатывается нормально. Если значение FALSE, константа b устанавливается в 1.
- подробный : необязательный аргумент. Если TRUE, возвращается дополнительная статистика регрессии. Если значение FALSE, дополнительная статистика регрессии не возвращается.
Следующий пошаговый пример показывает, как использовать эту функцию на практике.
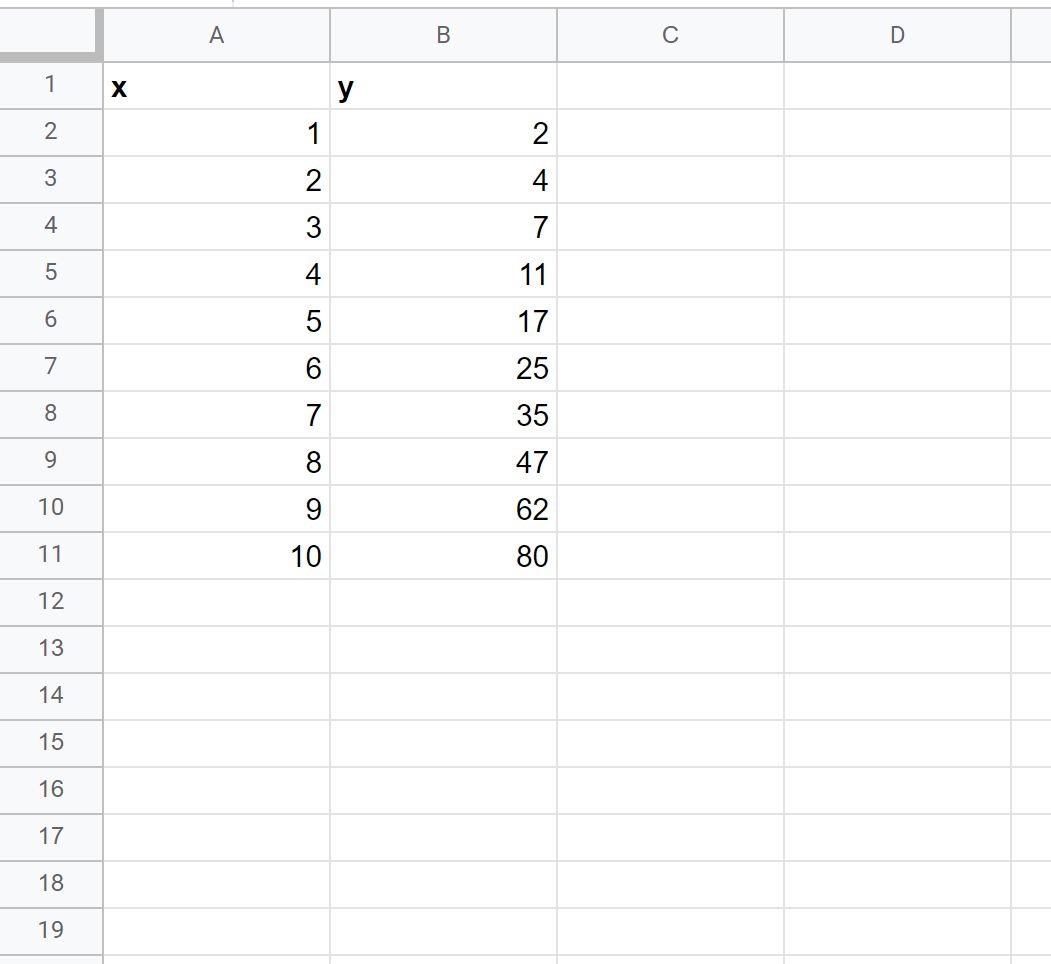
Шаг 1: Введите данные
Сначала давайте введем следующий набор данных в Google Таблицы:
Шаг 2. Визуализируйте данные
Далее давайте создадим быструю диаграмму рассеяния x и y, чтобы убедиться, что данные действительно следуют экспоненциальной кривой:
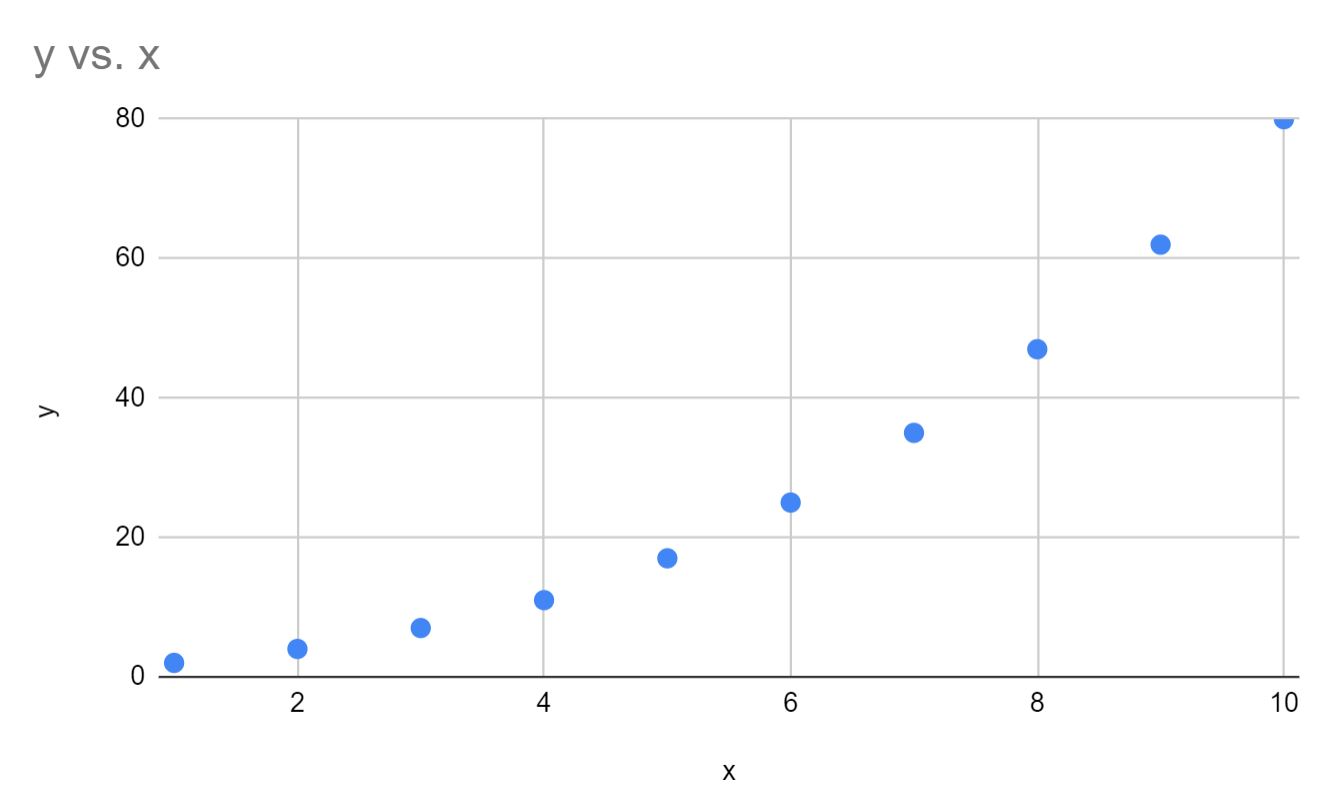
Мы видим, что данные действительно следуют экспоненциальной кривой.
Шаг 3. Используйте ЛИНГЕСТ, чтобы найти формулу экспоненциальной кривой.
Затем мы можем ввести следующую формулу в любую ячейку, чтобы вычислить формулу экспоненциальной кривой:
=LOGEST( B2:B11 , A2:A11 )
На следующем снимке экрана показано, как использовать эту формулу на практике:
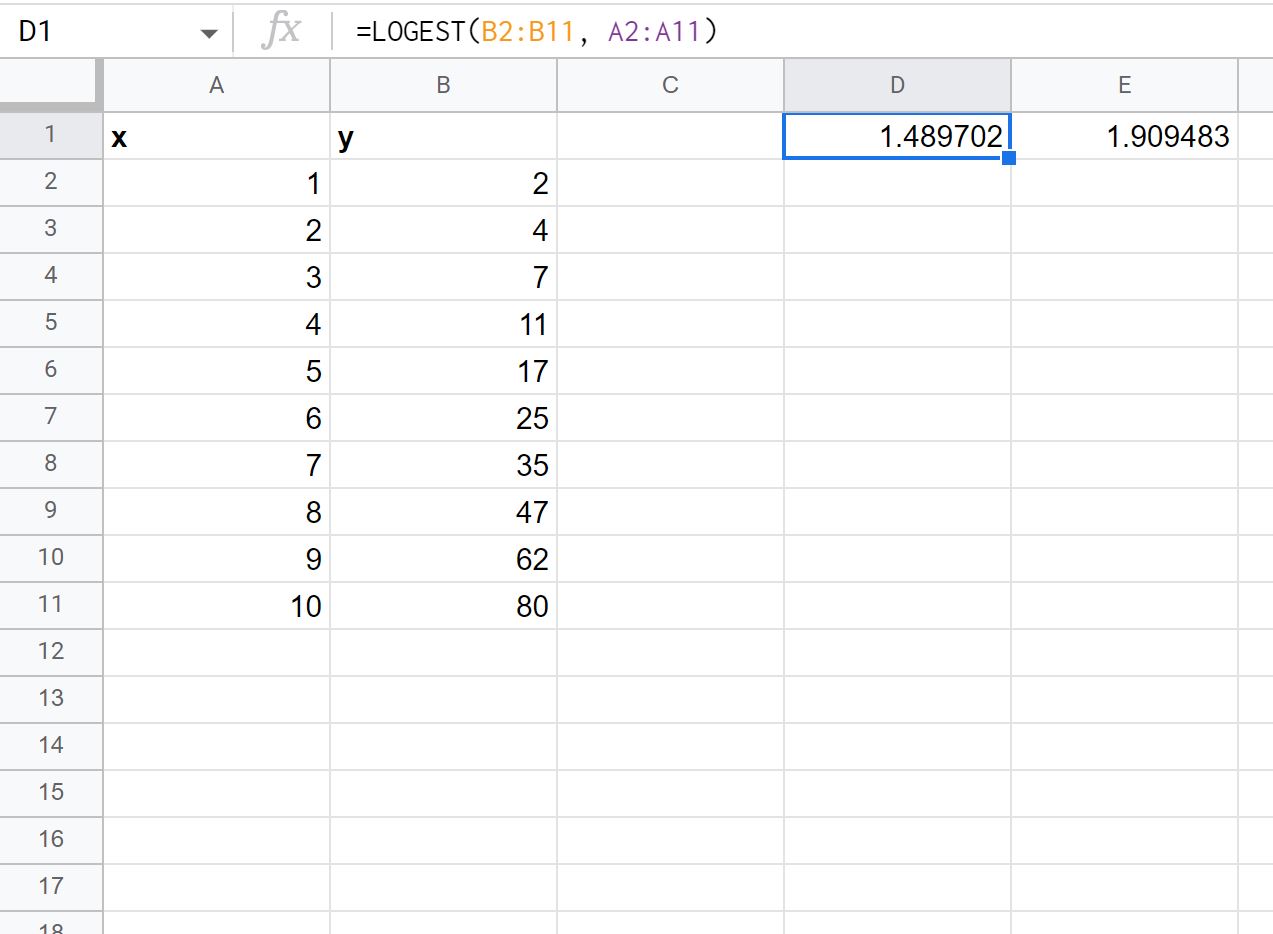
Первое выходное значение представляет значение m , а второе выходное значение представляет значение b в уравнении:
у = б* мх
Итак, мы бы записали эту формулу экспоненциальной кривой следующим образом:
у = 1,909483 * 1,489702x
Затем мы могли бы использовать эту формулу для прогнозирования значений y на основе значения x.
Например, если xa имеет значение 8, мы прогнозируем, что y имеет значение 46,31 :
у = 1,909483 * 1,489702 8 = 46,31
Шаг 4 (необязательно): просмотрите дополнительную статистику регрессии.
Мы можем установить подробное значение аргумента в функции ЛИНГЕСТ , равное ИСТИНЕ , чтобы отобразить дополнительную статистику регрессии для подобранного уравнения регрессии:
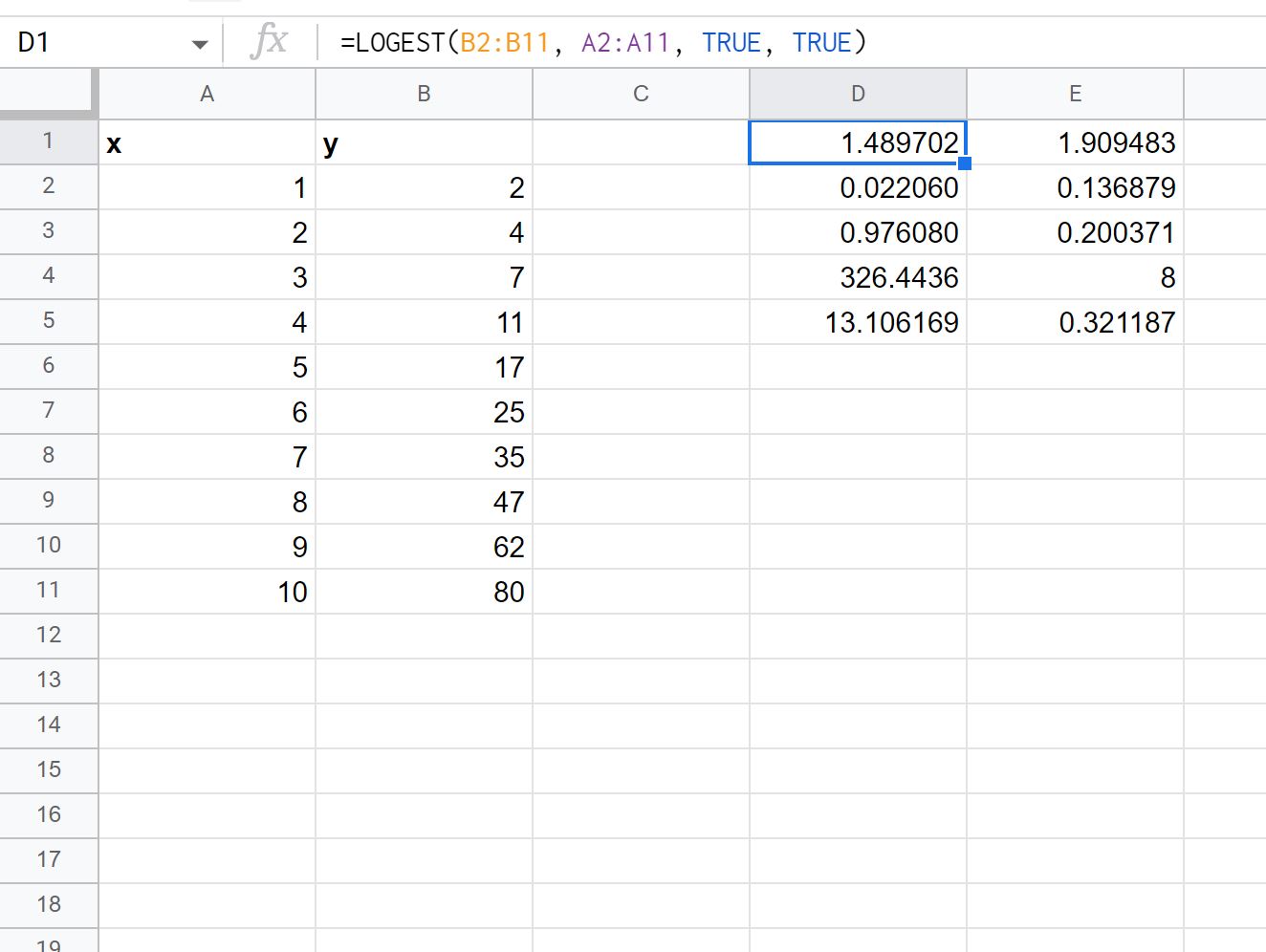
Вот как интерпретировать каждое значение в результате:
- Стандартная ошибка для m составляет 0,02206 .
- Стандартная ошибка для b равна 0,136879 .
- R 2 модели равен 0,97608 .
- Стандартная ошибка для y — .200371 .
- Статистика F равна 326,4436 .
- Степеней свободы 8 .
- Сумма квадратов регрессии равна 13,106169 .
- Остаточная сумма квадратов равна .321187 .
В общем, мерой, представляющей наибольший интерес в этой дополнительной статистике, является значение R 2 , которое представляет собой долю дисперсии переменной ответа, которую можно объяснить переменной-предиктором.
Значение R 2 может изменяться от 0 до 1.
Поскольку R 2 этой конкретной модели близок к 1, это говорит нам о том, что переменная-предиктор x хорошо предсказывает значение переменной отклика y.
Связанный: Что такое хорошее значение R-квадрата?
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные действия в Google Таблицах:
Как выполнить линейную регрессию в Google Sheets
Как выполнить полиномиальную регрессию в Google Sheets
Как посчитать R-квадрат в Google Таблицах
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше