Как выполнить многомерное масштабирование в r (с примером)
В статистике многомерное масштабирование — это способ визуализировать сходство наблюдений в наборе данных в абстрактном декартовом пространстве (обычно в двумерном пространстве).
Самый простой способ выполнить многомерное масштабирование в R — использовать встроенную функцию cmdscale() , которая использует следующий базовый синтаксис:
cmdscale(d, eig = FALSE, k = 2, …)
Золото:
- d : матрица расстояний, обычно рассчитываемая функцией dist() .
- eig : возвращать или нет собственные значения.
- k : количество измерений, в которых можно просматривать данные. Значение по умолчанию — 2 .
В следующем примере показано, как использовать эту функцию на практике.
Пример: многомерное масштабирование в R
Предположим, у нас есть следующий кадр данных в R, содержащий информацию о различных баскетболистах:
#create data frame df <- data. frame (points=c(4, 4, 6, 7, 8, 14, 16, 19, 25, 25, 28), assists=c(3, 2, 2, 5, 4, 8, 7, 6, 8, 10, 11), blocks=c(7, 3, 6, 7, 5, 8, 8, 4, 2, 2, 1), rebounds=c(4, 5, 5, 6, 5, 8, 10, 4, 3, 2, 2)) #add row names row. names (df) <- LETTERS[1:11] #view data frame df points assists blocks rebounds A 4 3 7 4 B 4 2 3 5 C 6 2 6 5 D 7 5 7 6 E 8 4 5 5 F 14 8 8 8 G 16 7 8 10 H 19 6 4 4 I 25 8 2 3 D 25 10 2 2 K 28 11 1 2
Мы можем использовать следующий код для выполнения многомерного масштабирования с помощью функции cmdscale() и визуализации результатов в 2D-пространстве:
#calculate distance matrix
d <- dist(df)
#perform multidimensional scaling
fit <- cmdscale(d, eig= TRUE , k= 2 )
#extract (x, y) coordinates of multidimensional scaling
x <- fit$points[,1]
y <- fit$points[,2]
#create scatterplot
plot(x, y, xlab=" Coordinate 1 ", ylab=" Coordinate 2 ",
main=" Multidimensional Scaling Results ", type=" n ")
#add row names of data frame as labels
text(x, y, labels=row. names (df))
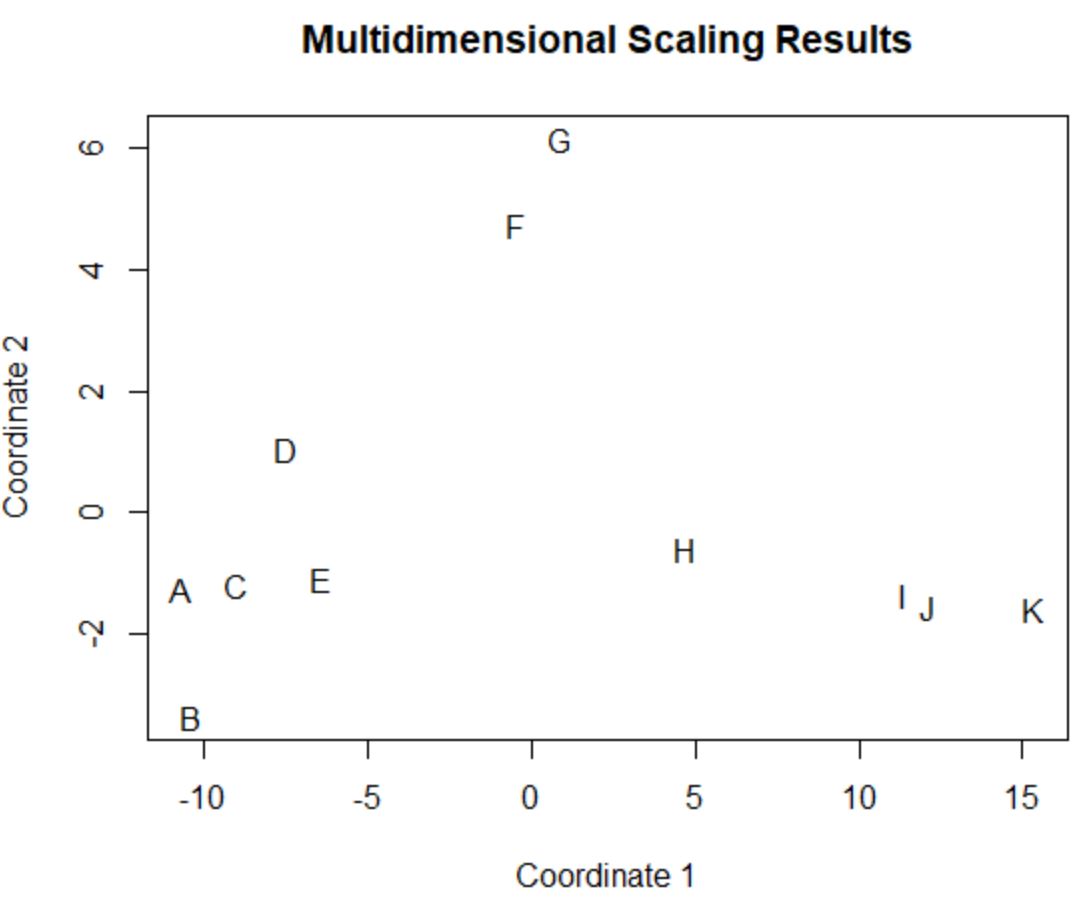
Игроки в исходном фрейме данных, имеющие одинаковые значения в исходных четырех столбцах (очки, передачи, блоки и подборы), находятся на графике близко друг к другу.
Например, игроки А и С закрыты друг для друга. Вот их значения из исходного фрейма данных:
#view data frame values for players A and C df[rownames(df) %in% c(' A ', ' C '), ] points assists blocks rebounds A 4 3 7 4 C 6 2 6 5
Их значения очков, передач, блоков и подборов очень похожи, что объясняет, почему они так близки друг к другу на 2D-графике.
Напротив, рассмотрим игроков B и K , которые находятся далеко друг от друга в сюжете.
Если мы обратимся к их значениям в исходных данных, то увидим, что они совершенно разные:
#view data frame values for players B and K df[rownames(df) %in% c(' B ', ' K '), ] points assists blocks rebounds B 4 2 3 5 K 28 11 1 2
Таким образом, двумерный график — хороший способ визуализировать, насколько похожи каждый игрок по всем переменным в фрейме данных.
Игроки со схожими характеристиками группируются близко друг к другу, а игроки с очень разными характеристиками находятся дальше друг от друга по сюжету.
Обратите внимание, что вы также можете получить точные координаты (x, y) каждого игрока на графике, набрав fit — имя переменной, в которой мы сохранили результаты функции cmdscale() :
#view (x, y) coordinates of points in the plot
fit
[,1] [,2]
A -10.6617577 -1.2511291
B -10.3858237 -3.3450473
C -9.0330408 -1.1968116
D -7.4905743 1.0578445
E -6.4021114 -1.0743669
F -0.4618426 4.7392534
G 0.8850934 6.1460850
H 4.7352436 -0.6004609
I 11.3793381 -1.3563398
J 12.0844168 -1.5494108
K 15.3510585 -1.5696166
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные задачи в R:
Как нормализовать данные в R
Как создать дата-центр в R
Как удалить выбросы в R
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше