Как получить прогнозируемые значения и остатки в stata
Линейная регрессия — это метод, который мы можем использовать, чтобы понять взаимосвязь между одной или несколькими объясняющими переменными и переменной отклика.
Когда мы выполняем линейную регрессию для набора данных, мы получаем уравнение регрессии, которое можно использовать для прогнозирования значений переменной отклика с учетом значений объясняющих переменных.
Затем мы можем измерить разницу между прогнозируемыми значениями и фактическими значениями, чтобы получить остатки для каждого прогноза. Это помогает нам получить представление о том, насколько хорошо наша регрессионная модель предсказывает значения ответа.
В этом руководстве объясняется, как получить как прогнозируемые значения , так и остатки для модели регрессии в Stata.
Пример: Как получить прогнозируемые значения и остатки
В этом примере мы будем использовать встроенный набор данных Stata под названием auto . Мы будем использовать расход топлива и расход топлива в качестве объясняющих переменных, а цену — в качестве переменной отклика.
Используйте следующие шаги, чтобы выполнить линейную регрессию, а затем получить прогнозируемые значения и остатки для модели регрессии.
Шаг 1: Загрузите и отобразите данные.
Сначала мы загрузим данные с помощью следующей команды:
автоматическое использование системы
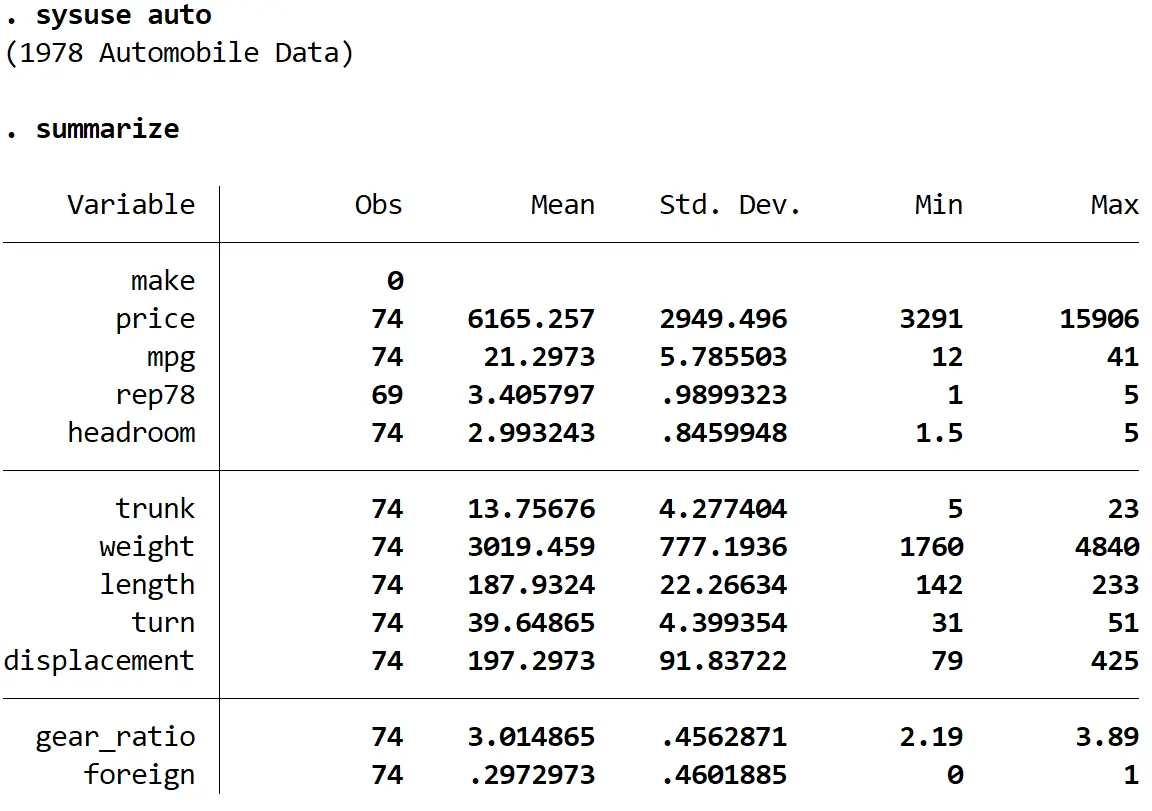
Далее мы получим краткую сводку данных, используя следующую команду:
обобщить
Шаг 2: Подберите регрессионную модель.
Далее мы будем использовать следующую команду для соответствия модели регрессии:
регрессия, цена, расход миль на галлон
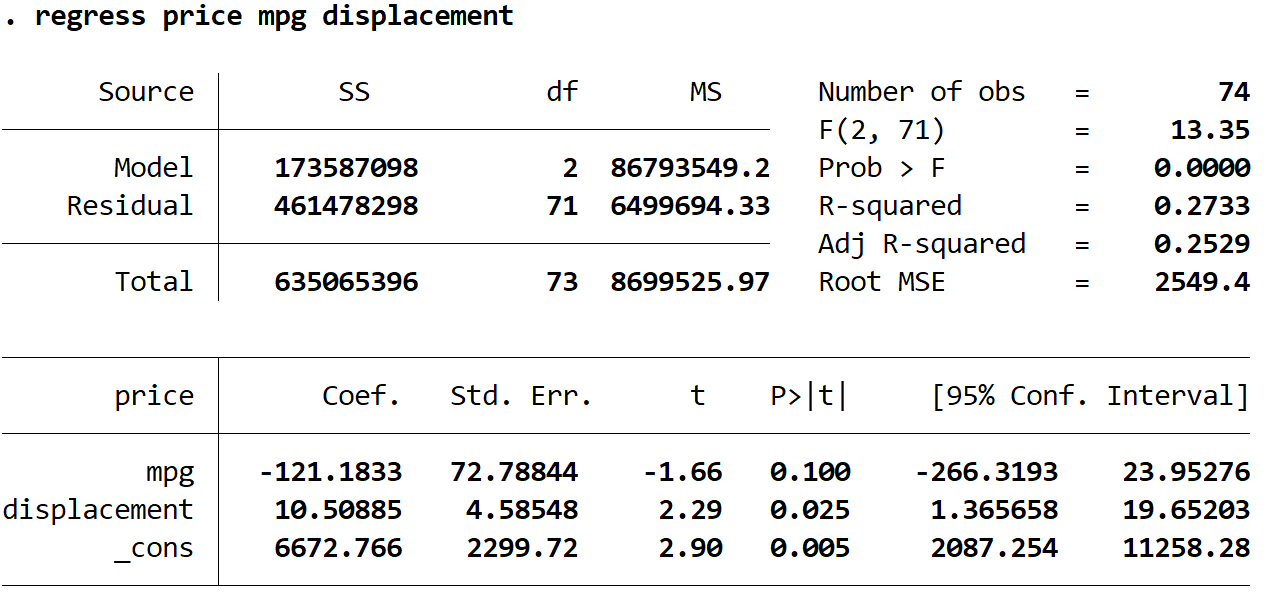
Предполагаемое уравнение регрессии:
ориентировочная цена = 6672,766 -121,1833*(миль на галлон) + 10,50885*(объем двигателя)
Шаг 3: Получите прогнозируемые значения.
Мы можем получить прогнозируемые значения, используя команду прогнозирования и сохранив эти значения в переменной с любым именем. В этом случае мы будем использовать имя pred_price :
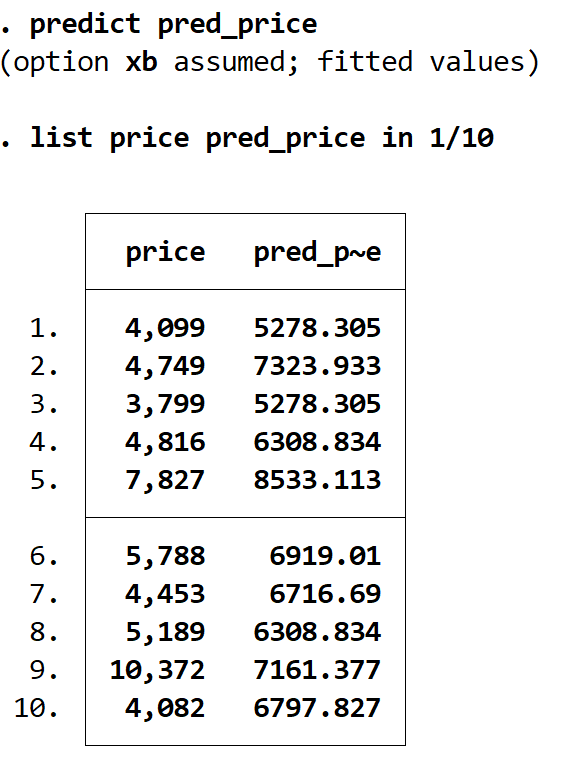
предсказать пред_цену
Мы можем отображать фактические и прогнозируемые цены рядом, используя команду list . Всего существует 74 прогнозируемых значения, но мы отобразим только первые 10 с помощью команды in 1/10 :
прейскурантная цена pred_price в 1/10
Шаг 4: Получите остаток.
Мы можем получить остатки каждого прогноза, используя команду остатков и сохраняя эти значения в переменной с любым именем. В данном случае мы будем использовать имя resid_price :
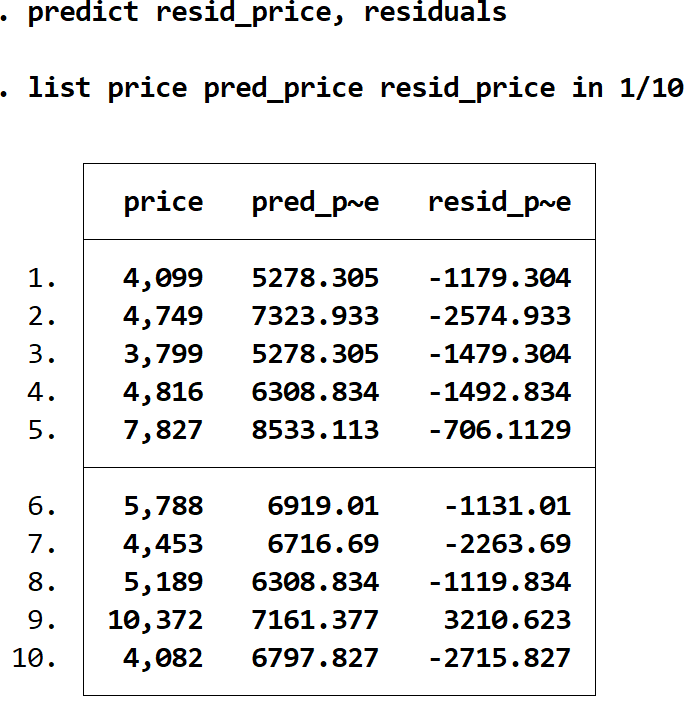
предсказать residency_price, остатки
Мы можем отобразить фактическую цену, ожидаемую цену и остатки рядом, снова используя команду list :
прейскурантная цена pred_price resid_price в 1/10
Шаг 5. Создайте график прогнозируемых значений в зависимости от остатков.
Наконец, мы можем создать диаграмму рассеяния, чтобы визуализировать связь между прогнозируемыми значениями и остатками:
дисперсия
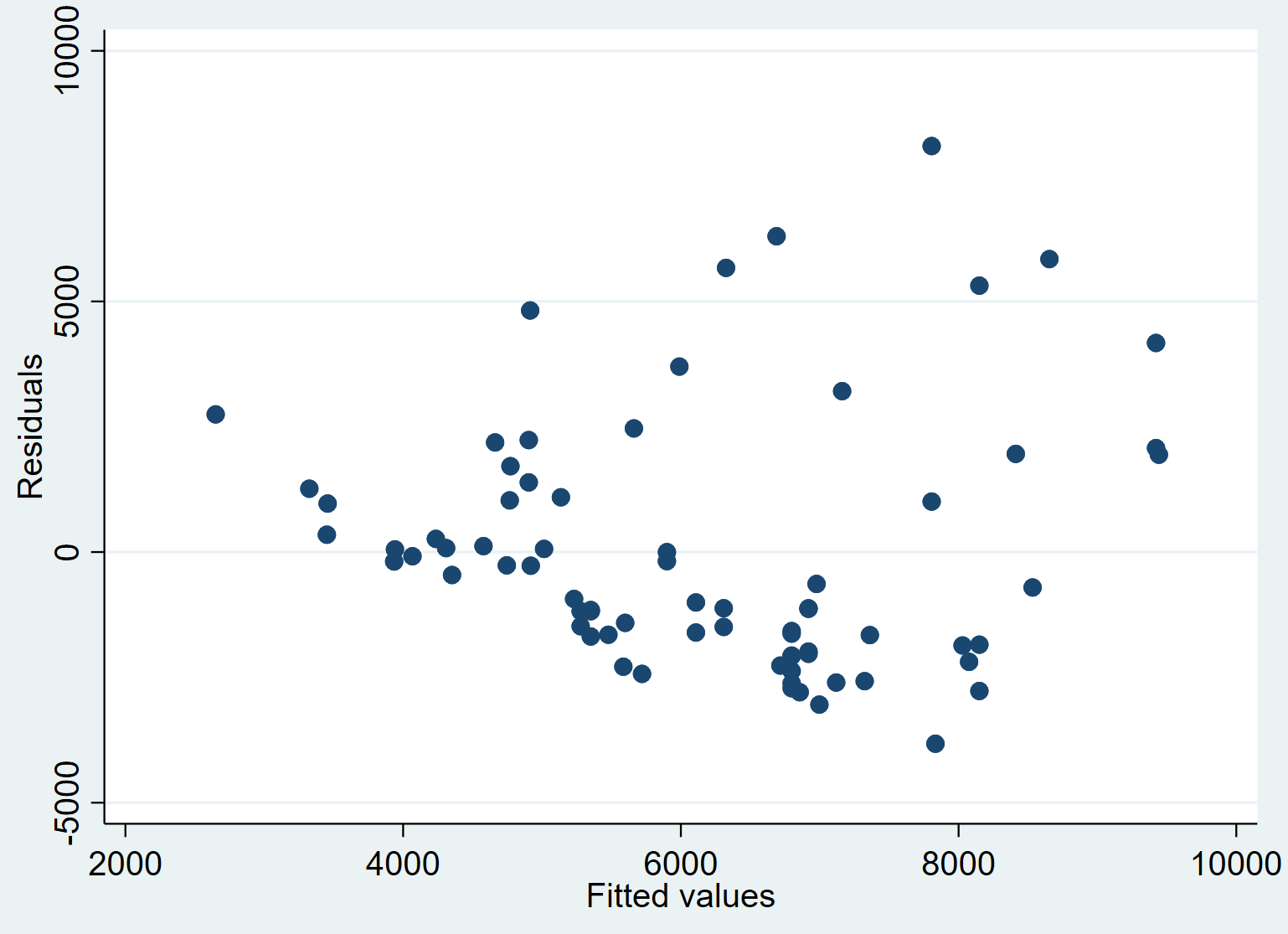
Мы видим, что в среднем остатки имеют тенденцию к увеличению по мере увеличения подобранных значений. Это может быть признаком гетероскедастичности – когда распределение остатков не является постоянным на каждом уровне ответа.
Мы могли бы формально проверить гетероскедастичность с помощью теста Бреуша-Пэгана и решить эту проблему, используя надежные стандартные ошибки .
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше