Как использовать оператор lsmeans в sas (с примером)
Однофакторный дисперсионный анализ используется для определения наличия или отсутствия статистически значимой разницы между средними значениями трех или более независимых групп.
Если общее значение p таблицы ANOVA ниже определенного уровня значимости, то у нас есть достаточно доказательств, чтобы сказать, что по крайней мере одно из групповых средних значений отличается от других.
Чтобы точно выяснить, какие групповые средние значения различаются, нам нужно провести апостериорный тест .
Вы можете использовать оператор LSMEANS в SAS для выполнения различных апостериорных тестов.
В следующем примере показано, как использовать оператор LSMEANS на практике.
Пример: Как использовать оператор LSMEANS в SAS
Предположим, исследователь набирает 30 студентов для участия в исследовании. Студентам случайным образом назначаются использовать один из трех методов обучения для подготовки к экзамену.
Результаты экзамена для каждого студента показаны ниже:
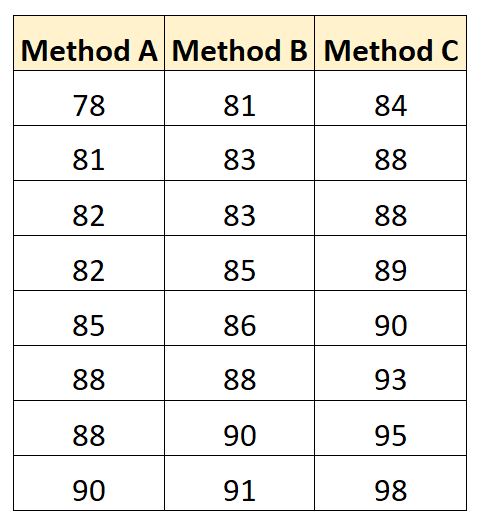
Мы можем использовать следующий код для создания этого набора данных в SAS:
/*create dataset*/
data my_data;
input Method $Score;
datalines ;
At 78
At 81
At 82
At 82
At 85
At 88
At 88
At 90
B 81
B 83
B 83
B85
B 86
B 88
B90
B91
C 84
C 88
C 88
C 89
C 90
C 93
C 95
C 98
;
run ;
Далее мы будем использовать процедуру ANOVA для выполнения одностороннего дисперсионного анализа:
/*perform one-way ANOVA*/
proc ANOVA data =my_data;
classMethod ;
modelScore = Method;
run ;
В результате получается следующая таблица ANOVA:
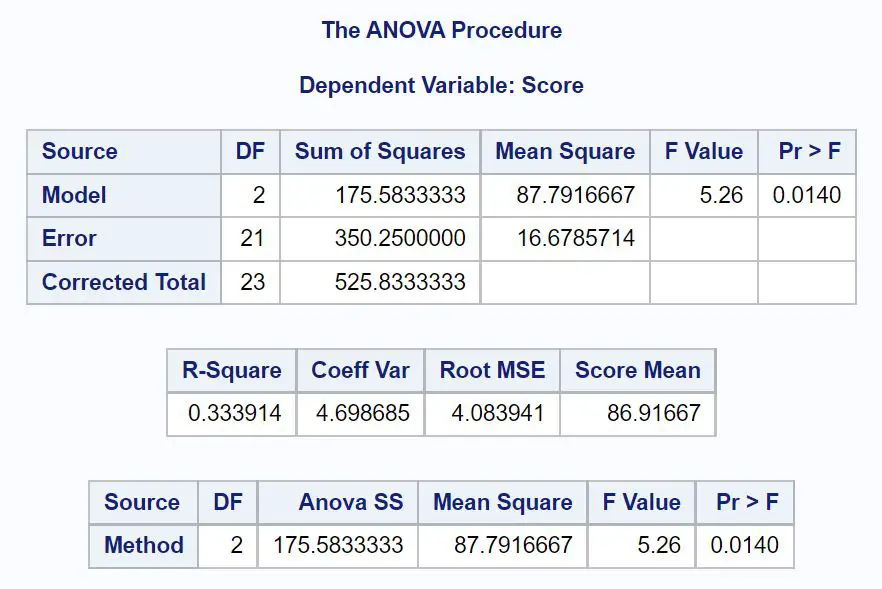
Из этой таблицы мы видим:
- Общее значение F: 5,26
- Соответствующее значение p: 0,0140.
Напомним, что однофакторный дисперсионный анализ использует следующие нулевые и альтернативные гипотезы:
- H 0 : Все средние значения группы равны.
- H A : По крайней мере одно среднее значение группы отличается отдых.
Поскольку значение p таблицы ANOVA ( 0,0140 ) меньше α = 0,05, мы отклоняем нулевую гипотезу.
Это говорит нам о том, что средний балл на экзамене не одинаков для всех трех методов обучения.
Чтобы точно определить, какие групповые средние значения отличаются, мы можем использовать оператор PROC GLIMMIX с оператором LSMEANS и опцию ADJUST=TUKEY для выполнения апостериорных тестов Тьюки:
/*perform Tukey post-hoc comparisons*/
proc glimmix data =my_data;
classMethod ;
modelScore = Method;
lsmeans Method / adjust =tukey alpha = .05 ;
run ;
Последняя таблица результатов показывает результаты апостериорных сравнений Тьюки:

Мы можем посмотреть столбец Adj P , чтобы просмотреть значения p, скорректированные с учетом разницы в групповых средних значениях.
В этом столбце мы видим, что есть только одна строка со скорректированным значением p меньше 0,05: строка, в которой сравнивается средняя разница между группой A и группой C.
Это говорит нам о том, что существует статистически значимая разница в средних баллах на экзаменах между группой A и группой C.
Конкретно мы можем увидеть:
- Разница между средними экзаменационными баллами студентов группы А и группы Б составила – 6,375 . (т.е. студенты группы А имели средний балл на экзамене на 6,375 балла ниже, чем студенты группы С)
- Скорректированное значение p для разницы средних составляет 0,0137 .
- Скорректированный 95% доверительный интервал для истинной разницы в средних баллах на экзамене между этими двумя группами составляет [-11,5219, -1,2281] .
Статистически значимых различий между средними значениями других групп нет.
Примечание . В этом примере мы использовали ADJUST=TUKEY для выполнения апостериорных сравнений Тьюки, но вы также можете указать BON , BUNNET , NELSON , SCHEFFE , SIDAK и SMM для выполнения других типов апостериорных сравнений.
Связанный: Тьюки против. Бонферрони против. Шеффе: какой тест следует использовать?
Дополнительные ресурсы
В следующих руководствах представлена дополнительная информация о моделях ANOVA:
Руководство по использованию апостериорного тестирования с помощью ANOVA
Как выполнить односторонний дисперсионный анализ в SAS
Как выполнить двусторонний дисперсионный анализ в SAS
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше