Как выполнить иерархическую регрессию в stata
Иерархическая регрессия — это метод, который мы можем использовать для сравнения нескольких различных линейных моделей.
Основная идея заключается в том, что мы сначала адаптируем модель линейной регрессии к одной объясняющей переменной. Затем мы подбираем другую модель регрессии, используя дополнительную независимую переменную. Если R-квадрат (доля дисперсии переменной отклика, которую можно объяснить объясняющими переменными) во второй модели значительно выше, чем R-квадрат в предыдущей модели, это означает, что вторая модель лучше.
Затем мы повторяем процесс подбора дополнительных моделей регрессии с большим количеством объясняющих переменных и смотрим, предлагают ли новые модели улучшение по сравнению с предыдущими моделями.
В этом руководстве представлен пример выполнения иерархической регрессии в Stata.
Пример: иерархическая регрессия в Stata
Мы будем использовать встроенный набор данных под названием auto , чтобы проиллюстрировать, как выполнять иерархическую регрессию в Stata. Сначала загрузите набор данных, введя в поле команды следующее:
автоматическое использование системы
Мы можем получить краткую сводку данных, используя следующую команду:
обобщить
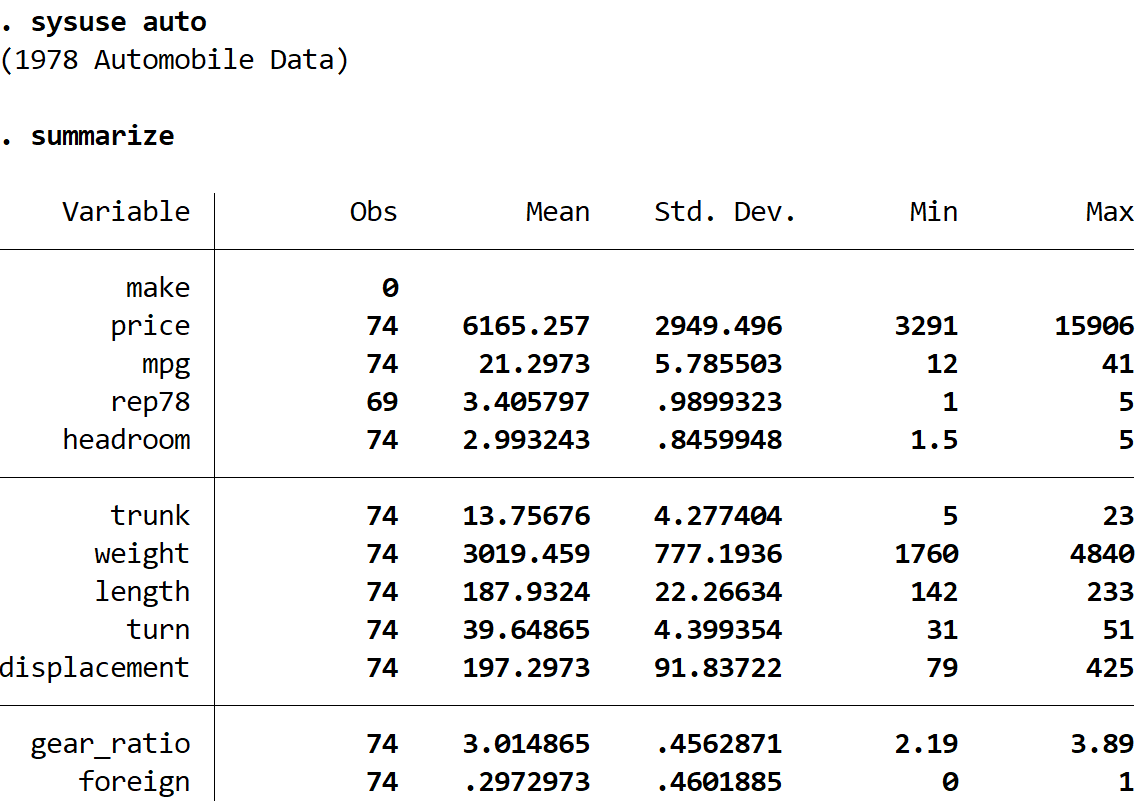
Мы видим, что набор данных содержит информацию о 12 различных переменных всего для 74 автомобилей.
Мы подберем следующие три модели линейной регрессии и будем использовать иерархическую регрессию, чтобы увидеть, обеспечивает ли каждая последующая модель значительное улучшение по сравнению с предыдущей моделью:
Модель 1: цена = перехват + миль на галлон
Модель 2: цена = перехват + мили на галлон + вес
Модель 3: цена = перехват + миль на галлон + вес + передаточное число.
Чтобы выполнить иерархическую регрессию в Stata, нам сначала нужно установить пакет Hireg . Для этого введите в поле «Команда» следующее:
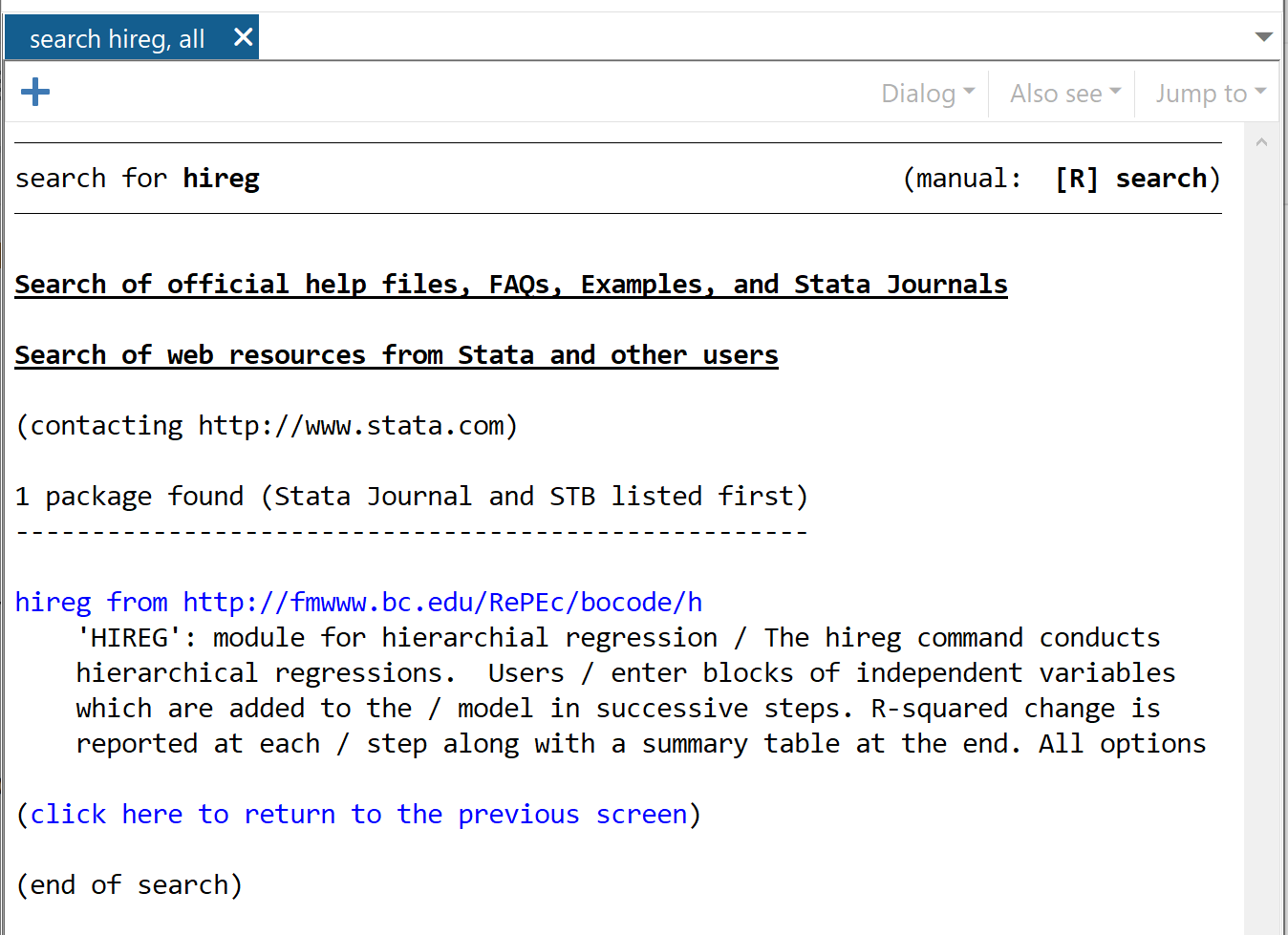
найти Хирега
В появившемся окне нажмите Hireg с https://fmwww.bc.edu/RePEc/bocode/h.
В следующем окне нажмите ссылку « Нажмите здесь, чтобы установить» .
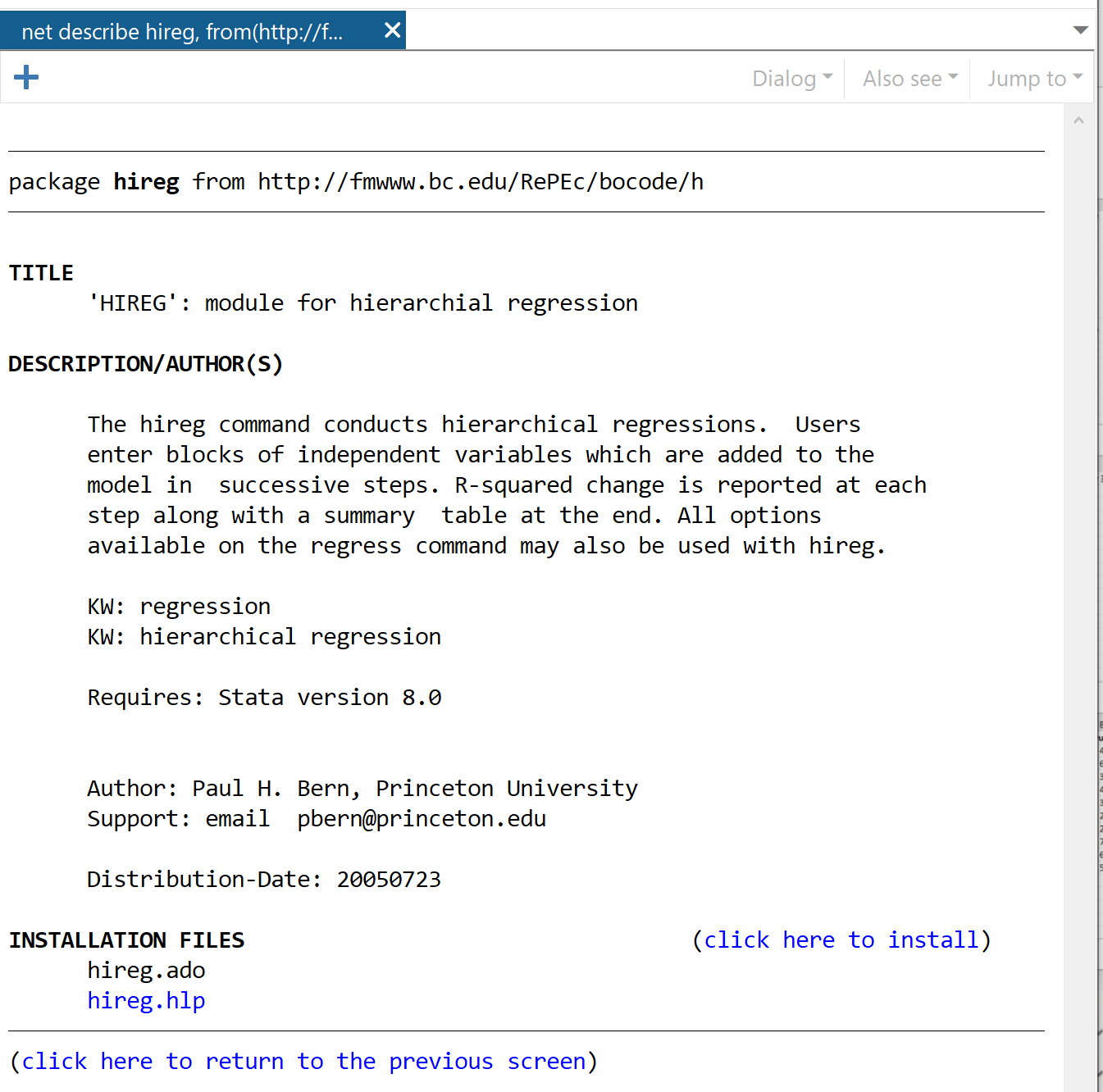
Пакет будет установлен за считанные секунды. Затем, чтобы выполнить иерархическую регрессию, мы будем использовать следующую команду:
стоимость аренды (миль на галлон) (вес) (gear_ratio)
Вот что требуется от Stata:
- Выполните иерархическую регрессию, используя цену в качестве переменной ответа в каждой модели.
- Для первой модели используйте миль на галлон в качестве объясняющей переменной.
- Для второй модели добавьте вес в качестве дополнительной объясняющей переменной.
- Для третьей модели добавьте gear_ratio в качестве еще одной объясняющей переменной.
Вот результат первой модели:
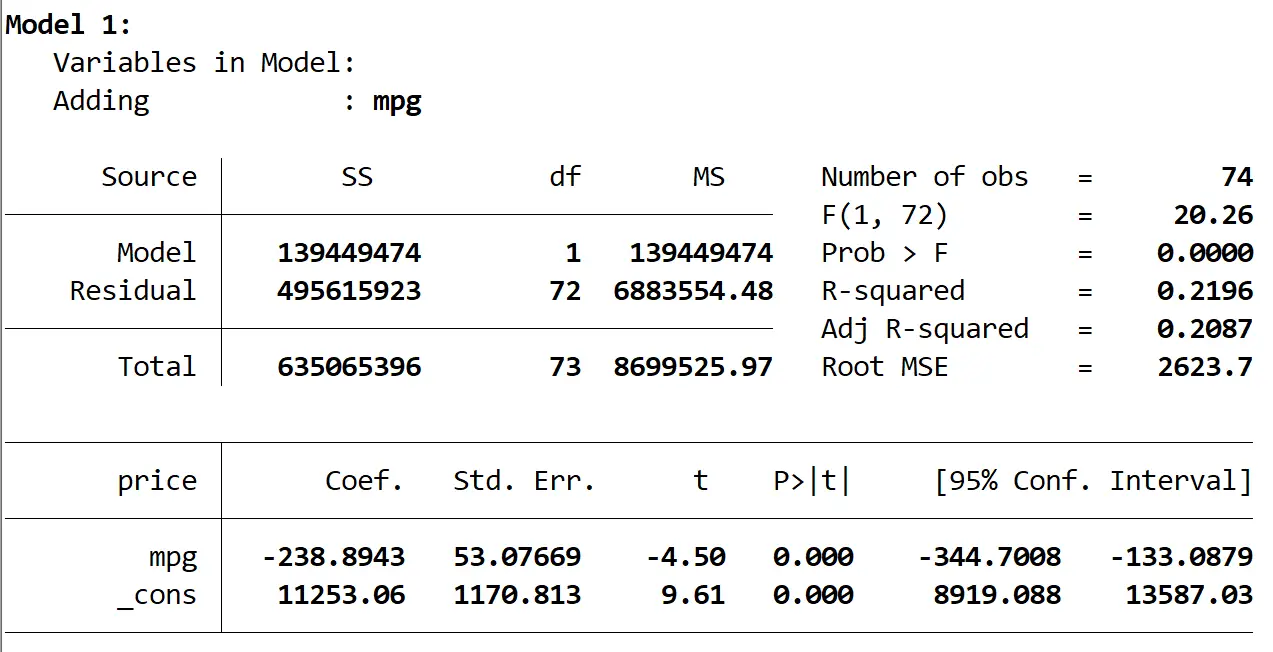
Мы видим, что R-квадрат модели равен 0,2196 , а общее значение p (Prob > F) модели составляет 0,0000 , что статистически значимо при α = 0,05.
Далее мы видим результат второй модели:
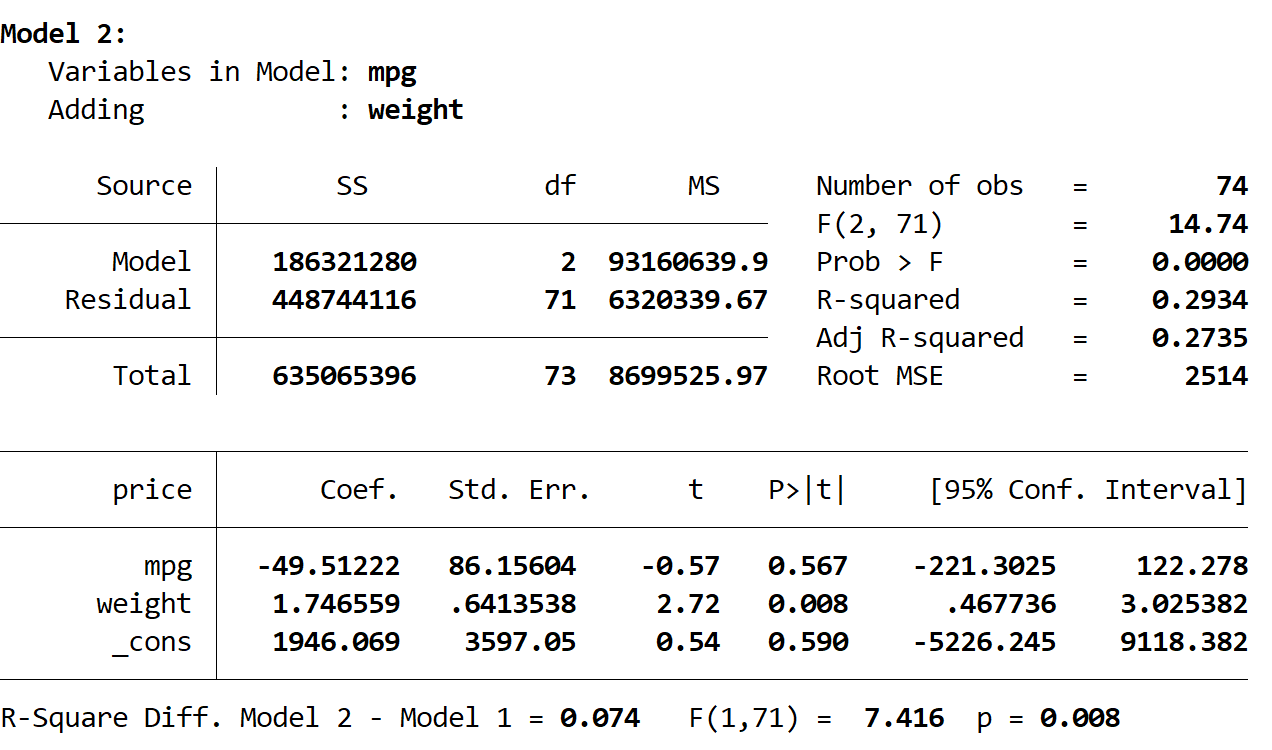
Квадрат R этой модели равен 0,2934 , что больше, чем у первой модели. Чтобы определить, является ли эта разница статистически значимой, Stata провела F-тест, который дал следующие цифры в нижней части результата:
- Разница в квадрате R между двумя моделями = 0,074.
- Статистика F для разницы = 7,416
- Соответствующее p-значение статистики F = 0,008.
Поскольку значение p меньше 0,05, мы приходим к выводу, что во второй модели наблюдается статистически значимое улучшение по сравнению с первой моделью.
Наконец, мы можем увидеть результат третьей модели:
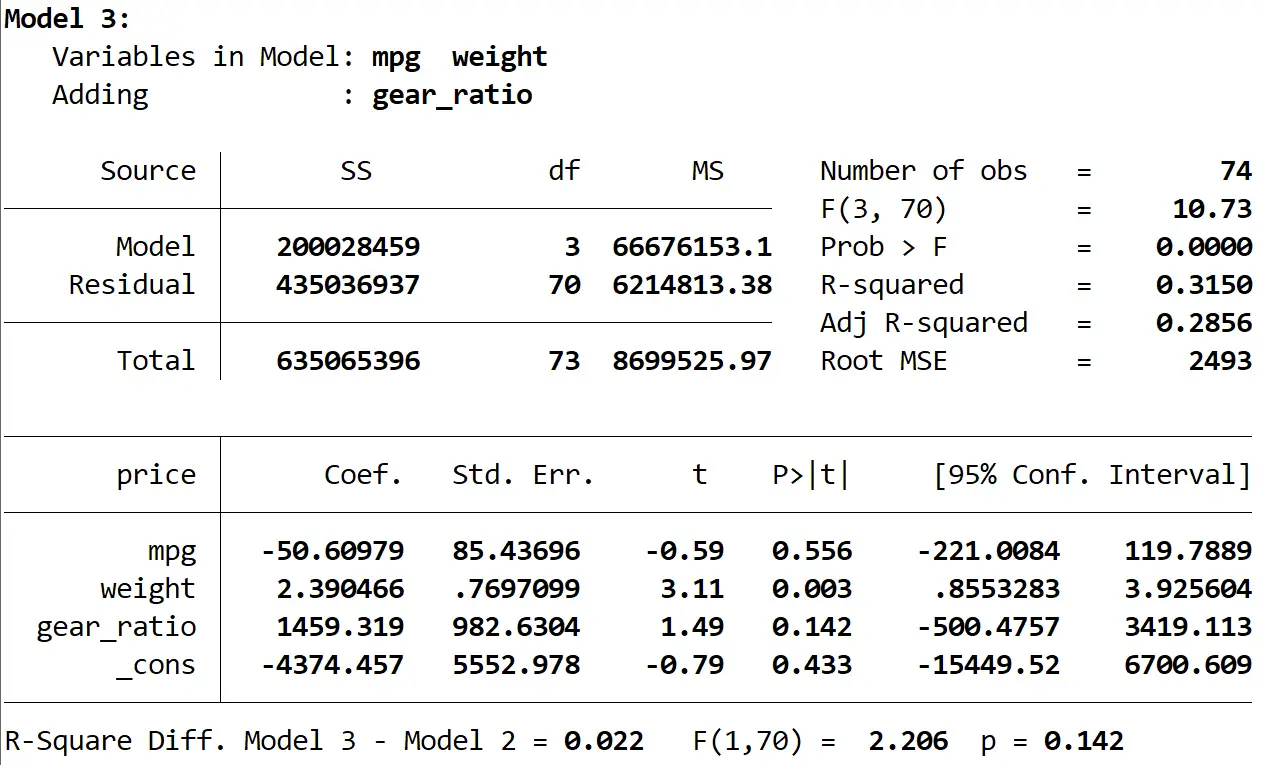
Квадрат R этой модели равен 0,3150 , что больше, чем у второй модели. Чтобы определить, является ли эта разница статистически значимой, Stata провела F-тест, который дал следующие цифры в нижней части результата:
- Разница в квадрате R между двумя моделями = 0,022.
- F-статистика для разницы = 2,206
- Соответствующее p-значение статистики F = 0,142.
Поскольку значение p составляет не менее 0,05, у нас нет достаточных доказательств, чтобы сказать, что третья модель обеспечивает улучшение по сравнению со второй моделью.
В самом конце результата мы видим, что Stata предоставляет сводку результатов:

В этом конкретном примере мы пришли бы к выводу, что Модель 2 предлагает значительное улучшение по сравнению с Моделью 1, но что Модель 3 не предлагает значительного улучшения по сравнению с Моделью 2.
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше