Как выполнить частичный f-тест в excel
Частичный F-тест используется, чтобы определить, существует ли статистически значимая разница между регрессионной моделью и вложенной версией той же модели.
Вложенная модель — это просто модель, которая содержит подмножество переменных-предикторов в общей модели регрессии.
Например, предположим, что у нас есть следующая модель регрессии с четырьмя переменными-предикторами:
Y = β 0 + β 1 x 1 + β 2 x 2 + β 3 x 3 + β 4 x 4 + ε
Примером вложенной модели может быть следующая модель только с двумя исходными переменными-предикторами:
Y = β 0 + β 1 x 1 + β 2 x 2 + ε
Чтобы определить, существенно ли отличаются эти две модели, мы можем выполнить частичный F-тест, который вычисляет следующую статистику F-теста:
F = (( Уменьшенный RSS – Полный RSS)/p) / ( Полный RSS /nk)
Золото:
- Уменьшенный RSS : Остаточная сумма квадратов уменьшенной (т.е. «вложенной») модели.
- RSS полный : Остаточная сумма квадратов полной модели.
- p: количество предикторов, удаленных из полной модели.
- n: общее количество наблюдений в наборе данных.
- k: количество коэффициентов (включая точку пересечения) в полной модели.
В этом тесте используются следующие нулевые и альтернативные гипотезы :
H 0 : Все коэффициенты, удаленные из полной модели, равны нулю.
H A : По крайней мере один из коэффициентов, удаленных из полной модели, не равен нулю.
Если значение p, соответствующее статистике F-теста, ниже определенного уровня значимости (например, 0,05), то мы можем отвергнуть нулевую гипотезу и сделать вывод, что по крайней мере один из коэффициентов, удаленных из полной модели, является значимым.
В следующем примере показано, как выполнить частичный F-тест в Excel.
Пример: частичный F-тест в Excel
Предположим, у нас есть следующий набор данных в Excel:
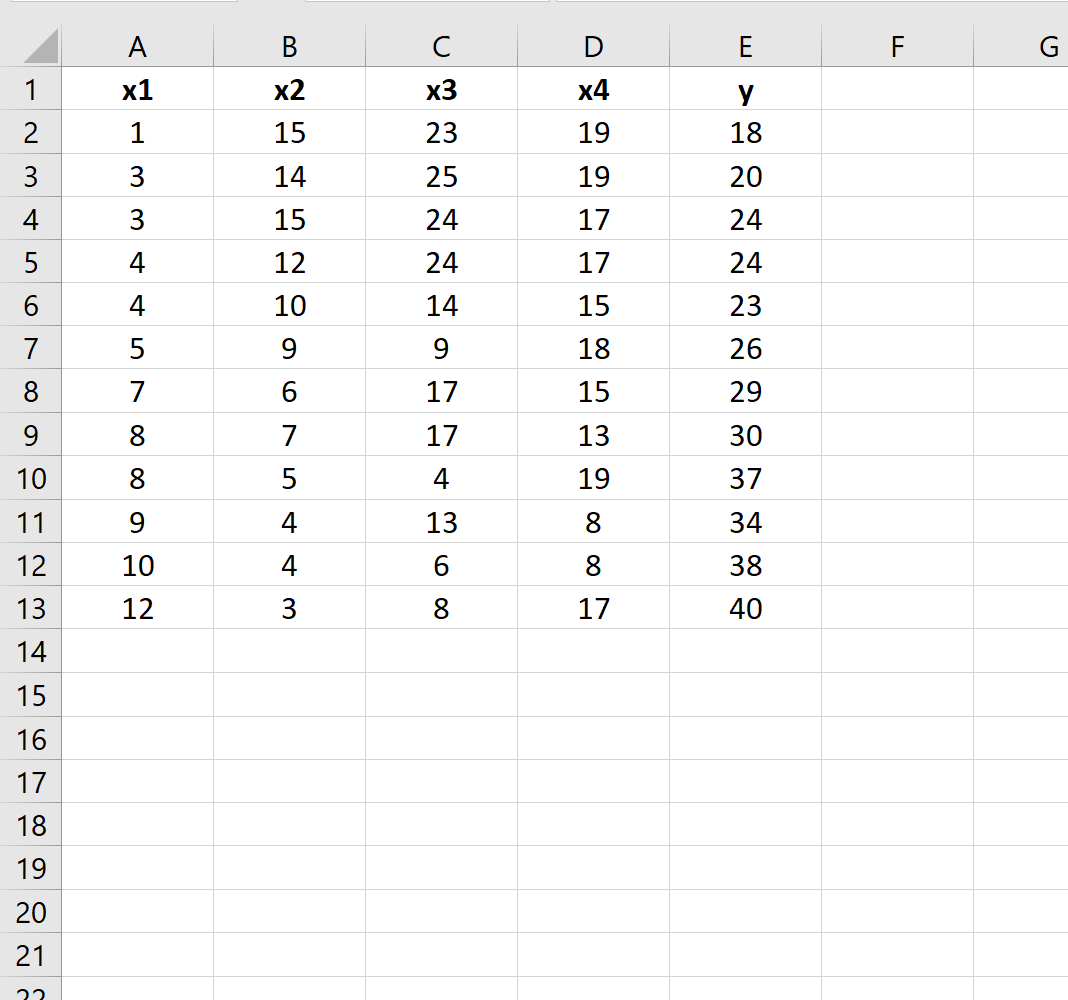
Предположим, мы хотим определить, есть ли разница между следующими двумя регрессионными моделями:
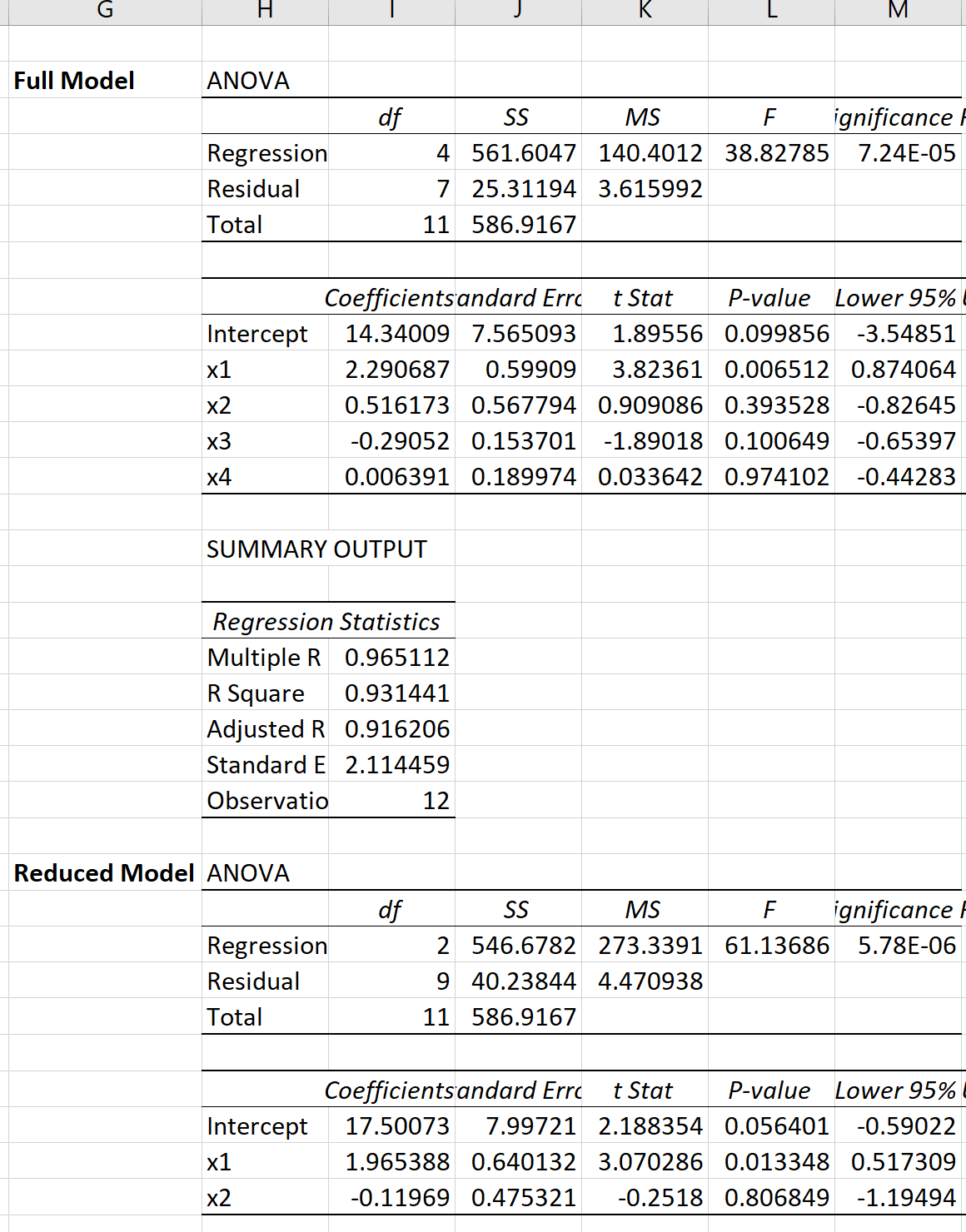
Полная модель: y = β 0 + β 1 x 1 + β 2 x 2 + β 3 x 3 + β 4 x 4.
Сокращенная модель: y = β 0 + β 1 x 1 + β 2 x 2
Мы можем выполнить множественную линейную регрессию в Excel для каждой модели, чтобы получить следующий результат:
Затем мы можем использовать следующую формулу для расчета статистики F-теста для частичного F-теста:
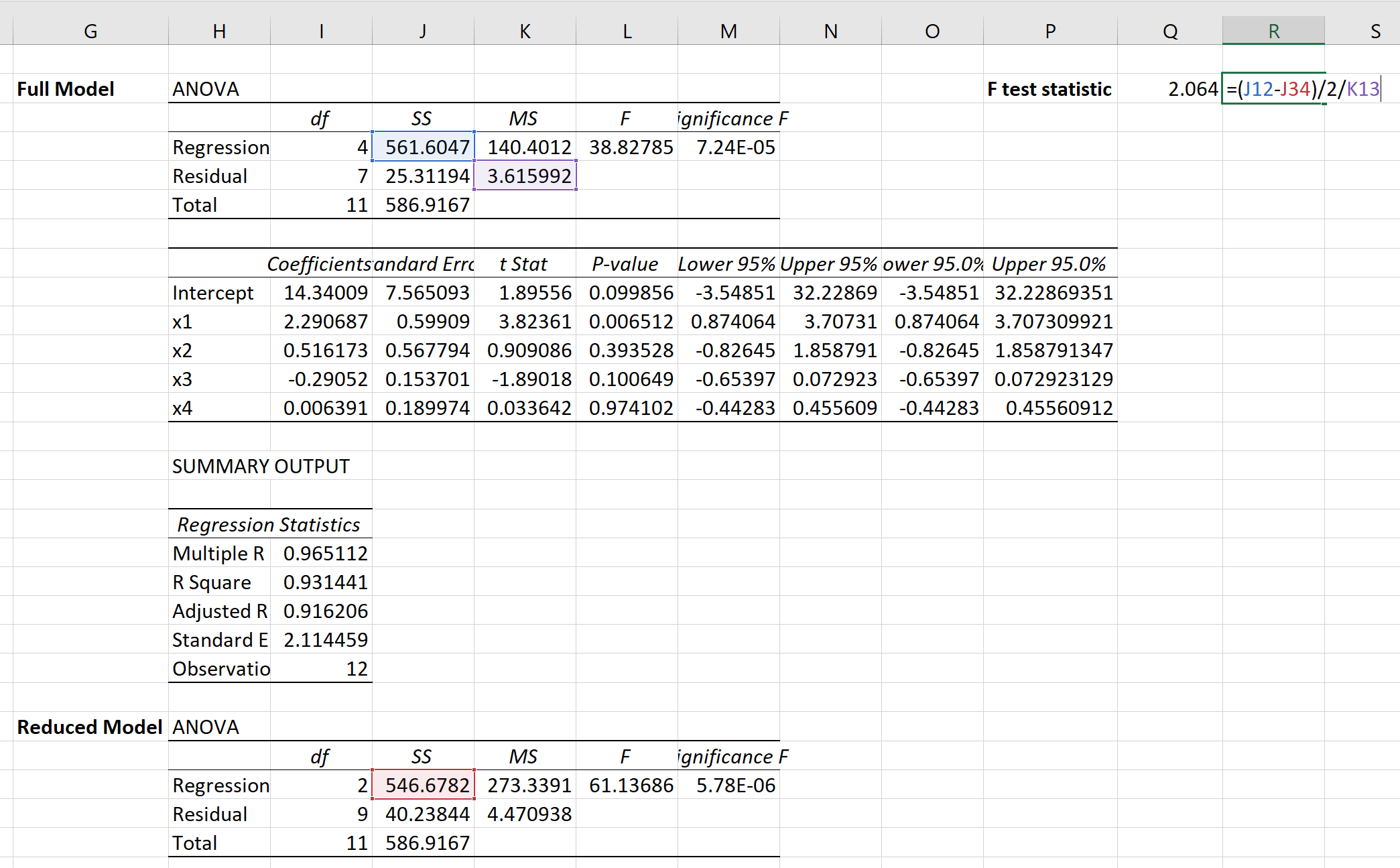
Статистика теста оказывается 2,064 .
Затем мы можем использовать следующую формулу для расчета соответствующего значения p:
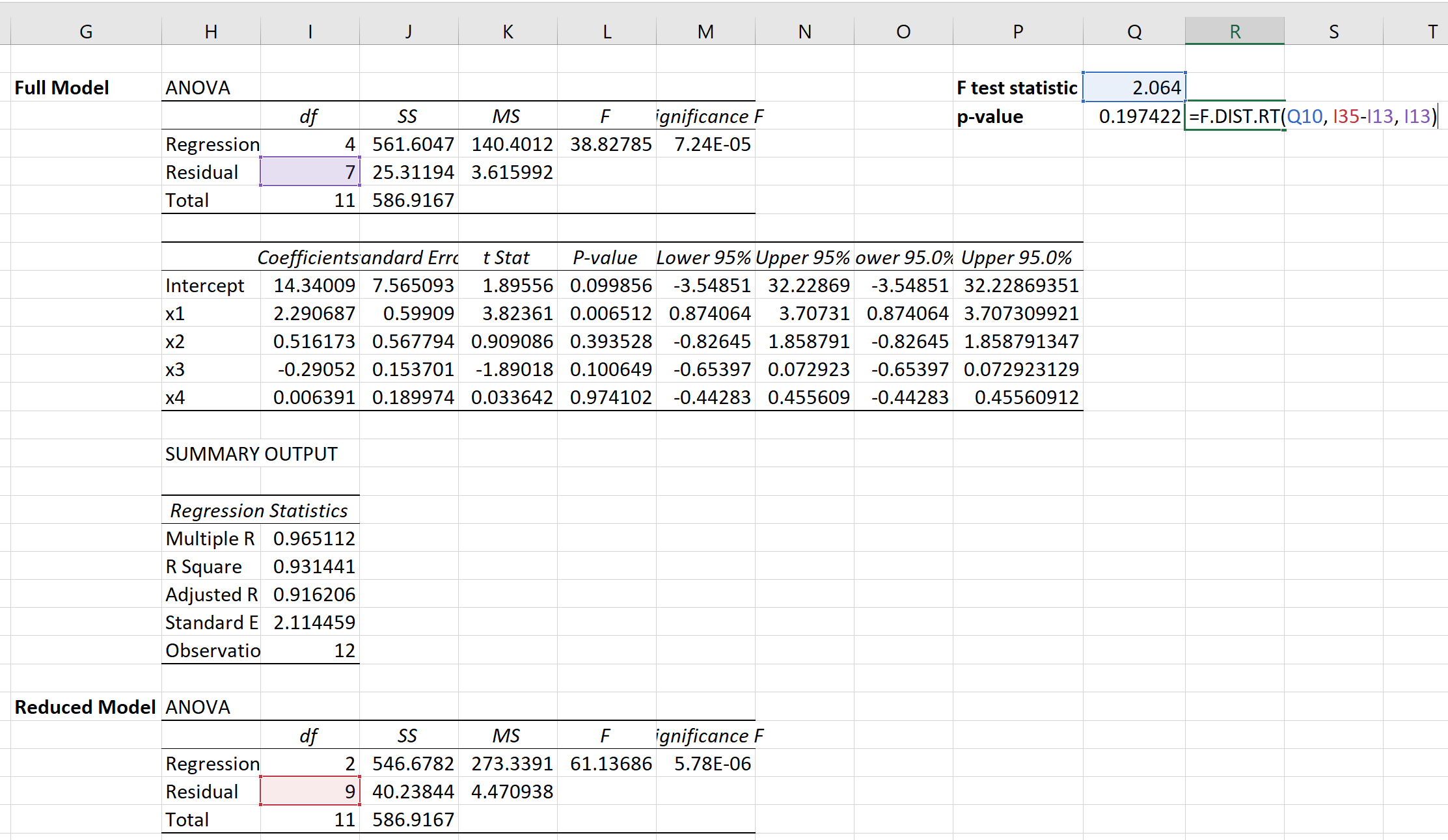
Значение p оказывается равным 0,1974 .
Поскольку это значение p не меньше 0,05, мы не сможем отвергнуть нулевую гипотезу. Это означает, что у нас недостаточно доказательств, чтобы сказать, что какая-либо из переменных-предикторов x3 или x4 является статистически значимой.
Другими словами, добавление x3 и x4 к регрессионной модели существенно не улучшает соответствие модели.
Дополнительные ресурсы
Как выполнить простую линейную регрессию в Excel
Как выполнить множественную линейную регрессию в Excel
Как рассчитать стандартную ошибку регрессии в Excel
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше