Как выполнить простую линейную регрессию в python (шаг за шагом)
Простая линейная регрессия — это метод, который мы можем использовать, чтобы понять взаимосвязь между одной объясняющей переменной и одной переменной отклика .
Этот метод находит строку, которая лучше всего «соответствует» данным, и принимает следующую форму:
ŷ = б 0 + б 1 х
Золото:
- ŷ : Предполагаемое значение ответа.
- b 0 : Начало линии регрессии.
- b 1 : Наклон линии регрессии.
Это уравнение может помочь нам понять взаимосвязь между объясняющей переменной и переменной ответа и (при условии, что оно статистически значимо) его можно использовать для прогнозирования значения переменной ответа с учетом значения объясняющей переменной.
В этом руководстве представлено пошаговое объяснение того, как выполнить простую линейную регрессию в Python.
Шаг 1. Загрузите данные
В этом примере мы создадим поддельный набор данных, содержащий следующие две переменные для 15 студентов:
- Общее количество часов, отработанных для определенных экзаменов
- Результаты экзамена
Мы попытаемся подобрать простую модель линейной регрессии, используя часы в качестве объясняющей переменной и результаты обследования в качестве переменной отклика.
Следующий код показывает, как создать этот поддельный набор данных в Python:
import pandas as pd #create dataset df = pd. DataFrame ({' hours ': [1, 2, 4, 5, 5, 6, 6, 7, 8, 10, 11, 11, 12, 12, 14], ' score ': [64, 66, 76, 73, 74, 81, 83, 82, 80, 88, 84, 82, 91, 93, 89]}) #view first six rows of dataset df[0:6] hours score 0 1 64 1 2 66 2 4 76 3 5 73 4 5 74 5 6 81
Шаг 2. Визуализируйте данные
Прежде чем подобрать простую модель линейной регрессии, мы должны сначала визуализировать данные, чтобы понять их.
Во-первых, мы хотим убедиться, что взаимосвязь между часами и баллами примерно линейна, поскольку это является основным предположением простой линейной регрессии.
Мы можем создать простую диаграмму рассеяния, чтобы визуализировать связь между двумя переменными:
import matplotlib.pyplot as plt plt. scatter (df.hours, df.score) plt. title (' Hours studied vs. Exam Score ') plt. xlabel (' Hours ') plt. ylabel (' Score ') plt. show ()
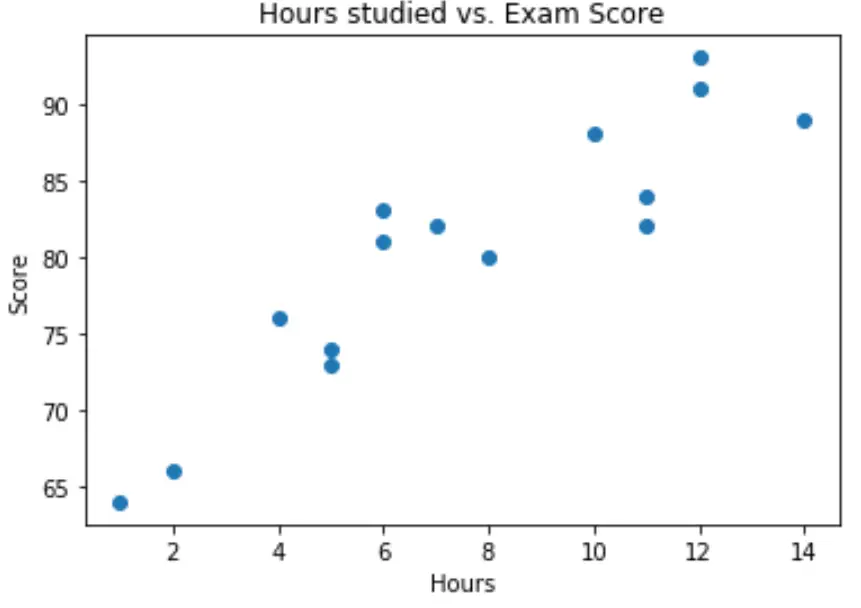
Из графика видно, что зависимость линейная. По мере увеличения количества часов оценка также имеет тенденцию к линейному увеличению.
Затем мы можем создать коробчатую диаграмму, чтобы визуализировать распределение результатов экзамена и проверить наличие выбросов . По умолчанию Python определяет наблюдение как выброс, если оно в 1,5 раза превышает межквартильный диапазон выше третьего квартиля (Q3) или в 1,5 раза превышает межквартильный диапазон ниже первого квартиля (Q1).
Если наблюдение является выбросом, на диаграмме появится небольшой кружок:
df. boxplot (column=[' score '])
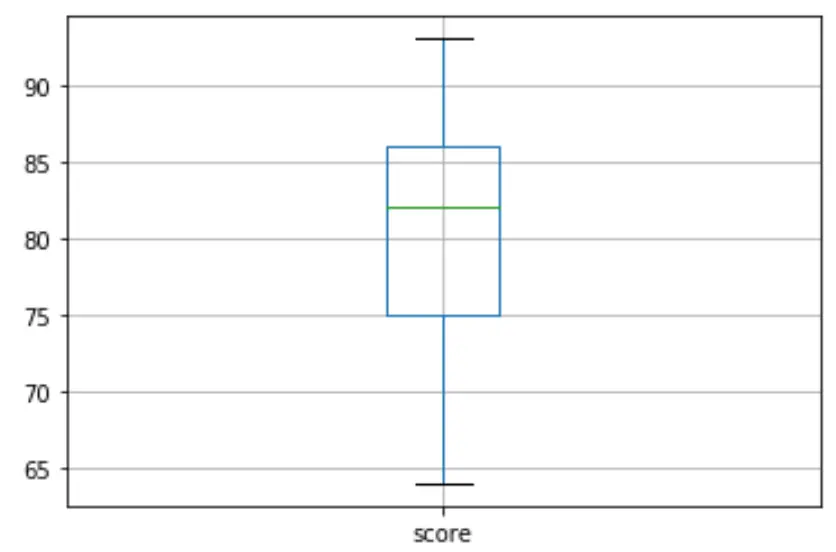
На диаграмме нет маленьких кружков, что означает, что в нашем наборе данных нет выбросов.
Шаг 3. Выполните простую линейную регрессию
Как только мы подтвердим, что связь между нашими переменными является линейной и нет выбросов, мы можем приступить к подбору простой модели линейной регрессии, используя часы в качестве объясняющей переменной и балл в качестве переменной ответа:
Примечание. Мы будем использовать функцию OLS() из библиотеки statsmodels, чтобы соответствовать модели регрессии.
import statsmodels.api as sm #define response variable y = df[' score '] #define explanatory variable x = df[[' hours ']] #add constant to predictor variables x = sm. add_constant (x) #fit linear regression model model = sm. OLS (y,x). fit () #view model summary print ( model.summary ()) OLS Regression Results ==================================================== ============================ Dept. Variable: R-squared score: 0.831 Model: OLS Adj. R-squared: 0.818 Method: Least Squares F-statistic: 63.91 Date: Mon, 26 Oct 2020 Prob (F-statistic): 2.25e-06 Time: 15:51:45 Log-Likelihood: -39,594 No. Observations: 15 AIC: 83.19 Df Residuals: 13 BIC: 84.60 Model: 1 Covariance Type: non-robust ==================================================== ============================ coef std err t P>|t| [0.025 0.975] -------------------------------------------------- ---------------------------- const 65.3340 2.106 31.023 0.000 60.784 69.884 hours 1.9824 0.248 7.995 0.000 1.447 2.518 ==================================================== ============================ Omnibus: 4,351 Durbin-Watson: 1,677 Prob(Omnibus): 0.114 Jarque-Bera (JB): 1.329 Skew: 0.092 Prob(JB): 0.515 Kurtosis: 1.554 Cond. No. 19.2 ==================================================== ============================
Из сводки модели мы видим, что подобранное уравнение регрессии имеет вид:
Оценка = 65,334 + 1,9824*(часы)
Это означает, что каждый дополнительный час обучения связан с увеличением среднего балла на экзамене на 1,9824 балла. А исходное значение 65 334 говорит нам о среднем ожидаемом балле на экзамене для студента, обучающегося ноль часов.
Мы также можем использовать это уравнение, чтобы найти ожидаемый результат экзамена на основе количества часов обучения студента. Например, студент, который учится 10 часов, должен набрать на экзамене балл 85,158 :
Оценка = 65,334 + 1,9824*(10) = 85,158
Вот как интерпретировать остальную часть описания модели:
- Р>|т| : это значение p, связанное с коэффициентами модели. Поскольку значение p для часов (0,000) значительно меньше 0,05, мы можем сказать, что существует статистически значимая связь между часами и баллами .
- R-квадрат: это число говорит нам о том, что процент вариации результатов экзамена можно объяснить количеством изученных часов. В общем, чем больше значение R-квадрата регрессионной модели, тем лучше объясняющие переменные способны предсказать значение переменной отклика. При этом 83,1% разницы в баллах объясняется количеством учебных часов.
- F-статистика и значение p: F-статистика ( 63.91 ) и соответствующее значение p ( 2.25e-06 ) говорят нам об общей значимости регрессионной модели, т.е. полезны ли объясняющие переменные в модели для объяснения вариаций. . в переменной ответа. Поскольку значение p в этом примере меньше 0,05, наша модель статистически значима, и часы считаются полезными для объяснения изменения оценок .
Шаг 4. Создайте остаточные графики
После подгонки простой модели линейной регрессии к данным последним шагом является создание остаточных графиков.
Одним из ключевых предположений линейной регрессии является то, что остатки регрессионной модели примерно нормально распределены и гомоскедастичны на каждом уровне объясняющей переменной. Если эти предположения не выполняются, результаты нашей регрессионной модели могут ввести в заблуждение или быть ненадежными.
Чтобы убедиться, что эти предположения выполняются, мы можем создать следующие остаточные графики:
График остатков в сравнении с подобранными значениями: этот график полезен для подтверждения гомоскедастичности. По оси X отображаются подобранные значения, а по оси Y — остатки. Пока остатки кажутся случайными и равномерно распределенными по графу вокруг нулевого значения, мы можем предположить, что гомоскедастичность не нарушена:
#define figure size fig = plt. figure (figsize=(12.8)) #produce residual plots fig = sm.graphics. plot_regress_exog (model, ' hours ', fig=fig)
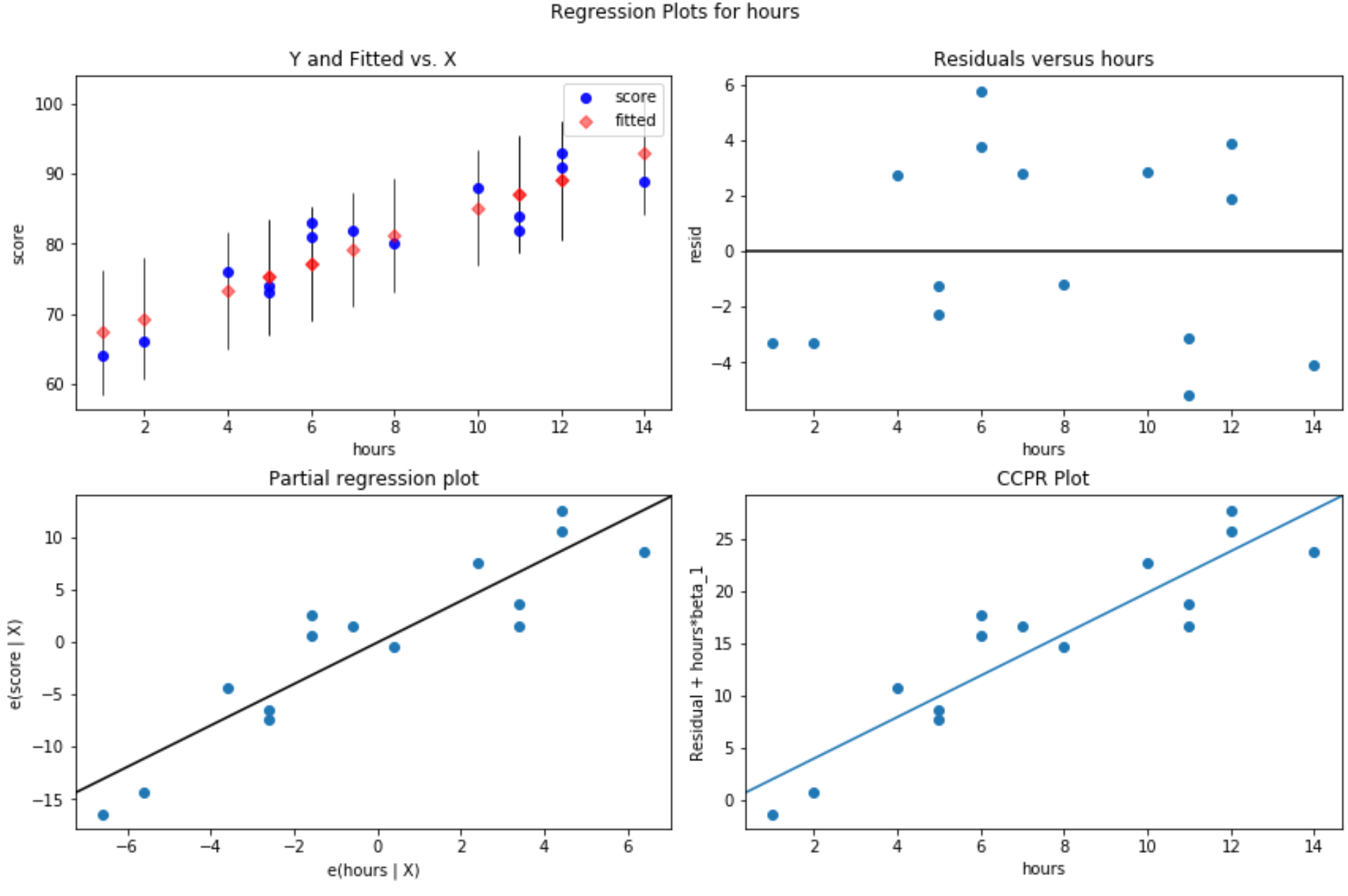
Создаются четыре сюжета. В правом верхнем углу показан остаточный график по сравнению с скорректированным графиком. Ось X на этом графике показывает фактические значения точек переменной-предиктора, а ось Y показывает невязку для этого значения.
Поскольку остатки кажутся случайным образом разбросанными вокруг нуля, это указывает на то, что гетероскедастичность не является проблемой для объясняющей переменной.
График QQ: этот график полезен для определения того, соответствуют ли остатки нормальному распределению. Если значения данных на графике следуют примерно прямой линии под углом 45 градусов, то данные распределяются нормально:
#define residuals res = model. reside #create QQ plot fig = sm. qqplot (res, fit= True , line=" 45 ") plt.show()
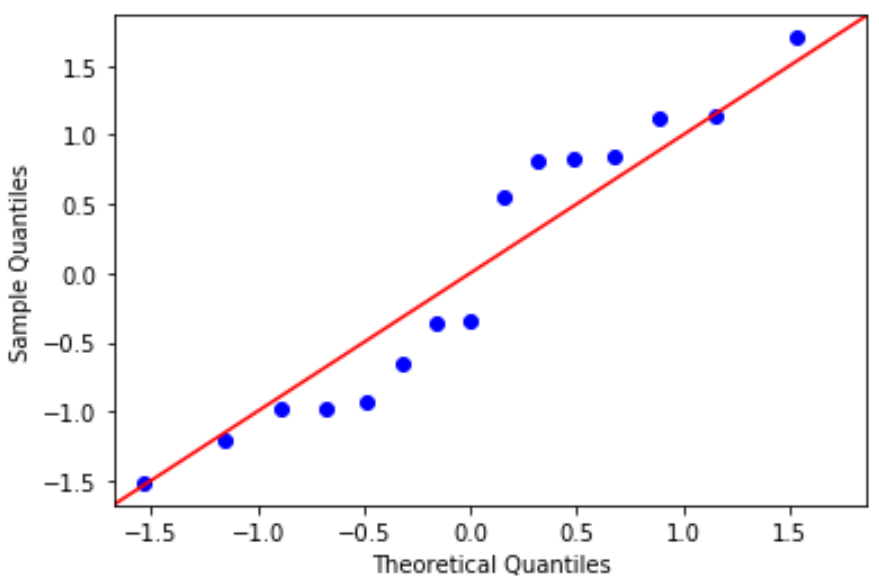
Остатки немного отклоняются от линии в 45 градусов, но не настолько, чтобы вызывать серьезное беспокойство. Можно предположить, что предположение о нормальности выполнено.
Поскольку остатки нормально распределены и гомоскедастичны, мы проверили, что предположения простой модели линейной регрессии выполняются. Таким образом, выходные данные нашей модели надежны.
Полный код Python, используемый в этом уроке, можно найти здесь .
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше