Краткое введение в перекрестную проверку с исключением одного (loocv)
Чтобы оценить эффективность модели на наборе данных, нам необходимо измерить, насколько хорошо прогнозы, сделанные моделью, соответствуют наблюдаемым данным.
Самый распространенный способ измерить это — использовать среднеквадратическую ошибку (MSE), которая рассчитывается следующим образом:
MSE = (1/n)*Σ(y i – f(x i )) 2
Золото:
- n: общее количество наблюдений
- y i : Значение ответа i-го наблюдения.
- f(x i ): прогнозируемое значение ответа i- го наблюдения.
Чем ближе предсказания модели к наблюдениям, тем ниже будет MSE.
На практике мы используем следующий процесс для расчета MSE данной модели:
1. Разделите набор данных на обучающий и тестовый набор.
2. Создайте модель, используя только данные из обучающего набора.
3. Используйте модель для прогнозирования набора тестов и измерения MSE – это называется тестовой MSE . 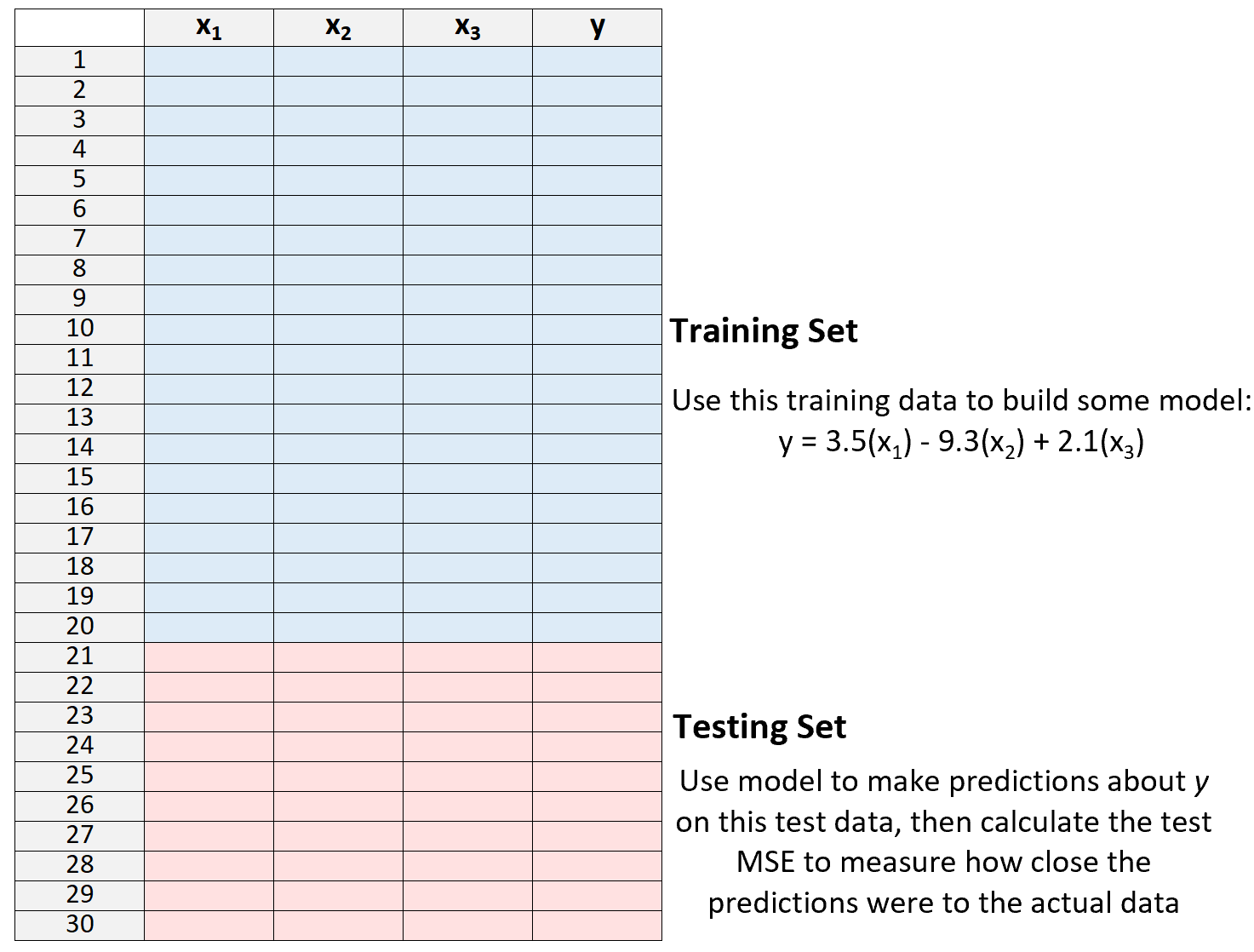
Тестирование MSE дает нам представление о том, насколько хорошо модель работает на данных, которых она раньше не видела, то есть на данных, которые не использовались для «обучения» модели.
Однако недостатком использования одного набора тестов является то, что тест MSE может значительно различаться в зависимости от наблюдений, используемых в обучающем и тестовом наборах.
Вполне возможно, что если мы будем использовать разные наборы наблюдений для обучающего набора и тестового набора, наша тестовая MSE может оказаться намного больше или меньше.
Один из способов избежать этой проблемы — подобрать модель несколько раз, используя каждый раз разные наборы для обучения и тестирования, а затем вычислить тестовую MSE как среднее значение всех тестовых MSE.
Этот общий метод известен как перекрестная проверка, а его конкретная форма известна как перекрестная проверка с исключением одного .
Перекрестная проверка с исключением одного
Перекрестная проверка с исключением одного использует следующий подход для оценки модели:
1. Разделите набор данных на обучающий набор и тестовый набор, используя все наблюдения, кроме одного, как часть обучающего набора:
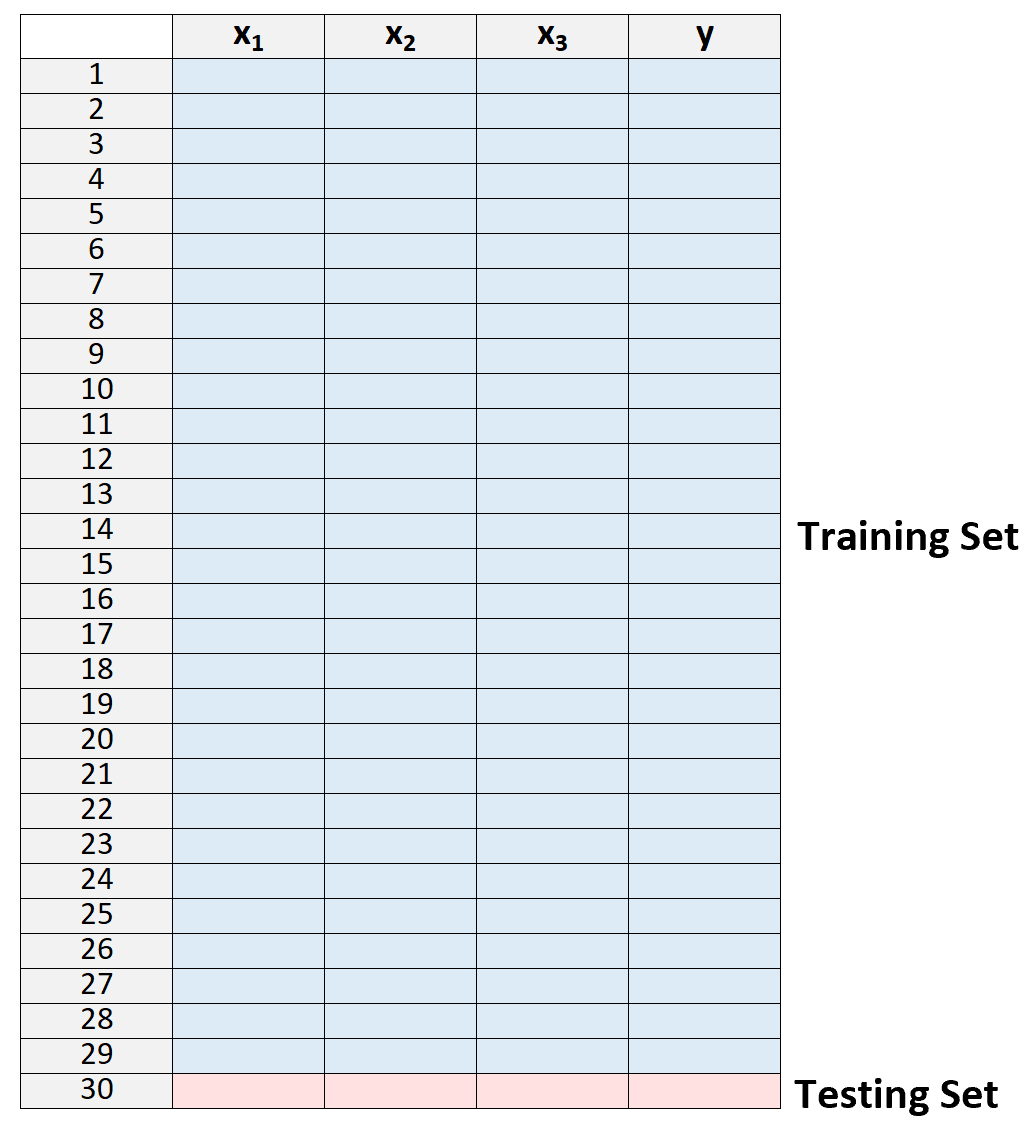
Обратите внимание, что мы оставляем только одно наблюдение «за пределами» обучающего набора. Именно здесь метод получил название перекрестной проверки с исключением одного.
2. Создайте модель, используя только данные из обучающего набора.
3. Используйте модель, чтобы спрогнозировать значение отклика одного наблюдения, исключенного из модели, и вычислить MSE.
4. Повторите процесс n раз.
Наконец, мы повторяем этот процесс n раз (где n — общее количество наблюдений в наборе данных), каждый раз исключая разные наблюдения из обучающего набора.
Затем мы вычисляем тестовую MSE как среднее значение всех тестовых MSE:
Тест MSE = (1/n)*ΣMSE i
Золото:
- n: общее количество наблюдений в наборе данных
- MSEi: тест MSE в течение i-го периода подбора модели.
Преимущества и недостатки LOOCV
Перекрестная проверка с исключением одного дает следующие преимущества :
- Он обеспечивает гораздо менее предвзятую оценку теста MSE по сравнению с использованием одного набора тестов, поскольку мы неоднократно подгоняем модель к набору данных, содержащему n-1 наблюдений.
- Он имеет тенденцию не переоценивать MSE теста по сравнению с использованием одного набора тестов.
Однако неавтоматическая перекрестная проверка имеет следующие недостатки:
- Использование этого процесса может занять много времени, если n велико.
- Это также может занять много времени, если модель особенно сложна и требуется много времени, чтобы соответствовать набору данных.
- Это может быть дорогостоящим в вычислительном отношении.
К счастью, современные вычисления стали настолько эффективными в большинстве областей, что использование LOOCV стало гораздо более разумным методом, чем много лет назад.
Обратите внимание, что LOOCV также можно использовать в контексте регрессии и классификации . Для задач регрессии он вычисляет тест MSE как среднеквадратическую разницу между прогнозами и наблюдениями, тогда как в задачах классификации он рассчитывает тест MSE как процент наблюдений, правильно классифицированных при n повторных корректировках модели.
Как запустить LOOCV в R & Python
В следующих руководствах представлены пошаговые примеры запуска LOOCV для заданной модели в R и Python:
Перекрестная проверка с исключением одного в R
Перекрестная проверка с исключением одного в Python
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше