Что такое открытое распространение?
В статистике открытое распределение — это распределение частот, в котором один или несколько классов (или «ячейок») открыты.
Например, следующее распределение частот представляет собой открытое распределение, в котором открыт наименьший класс:
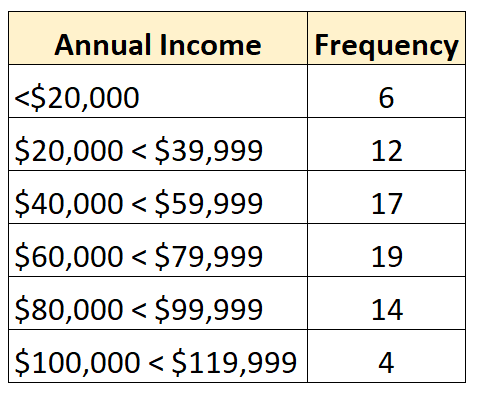
А следующее распределение частот показывает открытое распределение, в котором открыт самый большой класс:
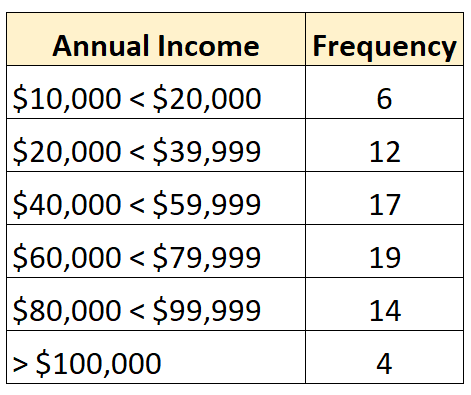
И наоборот, закрытое распределение — это распределение, в котором каждый класс распределения частот имеет верхний и нижний предел, например:
Что вызывает открытые дистрибутивы?
Открытые дистрибутивы часто являются результатом того, что исследователи решают собирать данные таким образом, что один из классов оказывается открытым.
Например, предположим, что исследователь опрашивает жителей определенного города и спрашивает их об их годовом семейном доходе.
Исследователь может дать максимально широкий ответ: «> 100 000 долларов», поскольку он знает, что жителям с высоким доходом может быть неудобно делиться своим заработком, если он значительно превышает 100 000 долларов.
И наоборот, исследователь может дать самый короткий ответ, поскольку он или она знает, что жителям, которые зарабатывают очень мало, также будет неудобно делиться тем малым, что они зарабатывают.
Короче говоря, исследователи часто включают открытые курсы в свои опросы, потому что хотят максимально увеличить количество людей, которые чувствуют себя комфортно, отвечая на вопросы опроса.
Проблема с открытыми дистрибутивами
Проблема с открытыми дистрибутивами заключается в том, что реальные данные подвергаются цензуре . Другими словами, мы можем знать количество людей, которые зарабатывают более 100 000 долларов в определенном городе, но на самом деле мы не знаем их точных годовых доходов.
Вполне возможно, что некоторые люди зарабатывают 150 000, 250 000, 500 000 долларов или даже больше, но мы понятия не имеем, поскольку каждый из этих людей не может указать в «расследовании», что он зарабатывает «>100 000 долларов».
Поскольку данные в открытых дистрибутивах подвергаются цензуре, мы также не можем вычислить точное среднее и стандартное отклонение значений в наборе данных, поскольку у нас нет доступа ко всем значениям в необработанных данных.
Как анализировать открытый дистрибутив
Поскольку мы не можем вычислить точное среднее значение открытого распределения, мы часто используем медиану как меру «центра» набора данных.
Напомним, что медиана представляет собой среднее значение набора данных.
При работе с открытыми распределениями мы можем использовать следующую формулу, чтобы найти наилучшую оценку медианы:
Наилучшая оценка медианы: L + ((n/2 – F) / f) * w
Золото:
- L: Нижний предел средней группы.
- n: Общее количество наблюдений
- F: Суммарная частота до средней группы.
- f: Частота средней группы
- w: Ширина средней группы
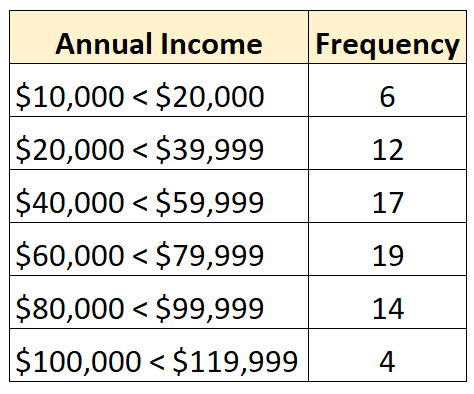
Например, предположим, что у нас есть следующий открытый дистрибутив:
Всего в наборе данных 72 значения. Итак, мы знаем, что медианное значение будет между 36-м и 37-м по величине значениями в наборе данных. Каждое из этих значений попадает в класс «60 000–79 999 долларов», поэтому мы знаем, что средний доход находится в этом диапазоне.
Наилучшая оценка медианы будет следующей:
Медиана: 60 000 + ((72/2 – 25) / 19) * 19 999 = 71 578 долларов США.
Это значение представляет собой нашу лучшую оценку среднего годового дохода людей в этом наборе данных.
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше