Как использовать pandas get dummies – pd.get_dummies
Часто в статистике наборы данных, с которыми мы работаем, включают категориальные переменные .
Это переменные, которые принимают имена или метки. Примеры включают в себя:
- Семейное положение («женат», «холост», «разведен»)
- Статус курения («курящий», «некурящий»)
- Цвет глаз («голубой», «зеленый», «карий»)
- Уровень образования (например, «средняя школа», «степень бакалавра», «степень магистра»)
При настройке алгоритмов машинного обучения (таких как линейная регрессия , логистическая регрессия , случайные леса и т. д.) мы часто конвертируем категориальные переменные в фиктивные переменные , которые представляют собой числовые переменные, используемые для категориального представления данных.
Например, предположим, что у нас есть набор данных, содержащий категориальную переменную Gender . Чтобы использовать эту переменную в качестве предиктора в регрессионной модели, сначала необходимо преобразовать ее в фиктивную переменную.
Чтобы создать эту фиктивную переменную, мы можем выбрать одно из значений («Мужской») для обозначения 0, а другое значение («Женский») для обозначения 1:
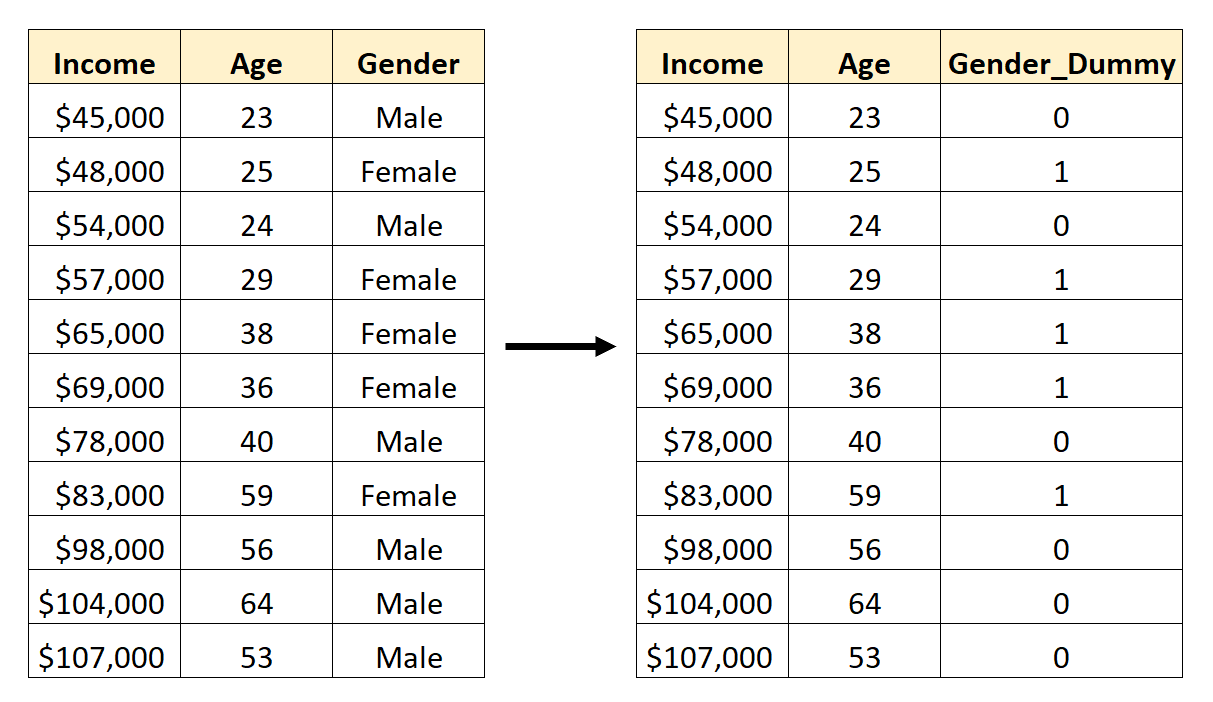
Как создать фиктивные переменные в Pandas
Чтобы создать фиктивные значения для переменной в DataFrame pandas, мы можем использовать функцию pandas.get_dummies() , которая использует следующий базовый синтаксис:
pandas.get_dummies(данные, префикс=Нет, столбцы=Нет, drop_first=False)
Золото:
- data : имя панды DataFrame.
- префикс : строка, добавляемая в начало нового столбца фиктивной переменной.
- columns : имя столбца(ов), которые необходимо преобразовать в фиктивную переменную.
- drop_first : удалять или нет первый столбец фиктивной переменной.
Следующие примеры показывают, как использовать эту функцию на практике.
Пример 1. Создайте одну фиктивную переменную.
Предположим, у нас есть следующий DataFrame pandas:
import pandas as pd #createDataFrame df = pd. DataFrame ({' income ': [45, 48, 54, 57, 65, 69, 78], ' age ': [23, 25, 24, 29, 38, 36, 40], ' gender ': ['M', 'F', 'M', 'F', 'F', 'F', 'M']}) #view DataFrame df income age gender 0 45 23 M 1 48 25 F 2 54 24 M 3 57 29 F 4 65 38 F 5 69 36 F 6 78 40 M
Мы можем использовать функцию pd.get_dummies() , чтобы превратить пол в фиктивную переменную:
#convert gender to dummy variable p.d. get_dummies (df, columns=[' gender '], drop_first= True ) income age gender_M 0 45 23 1 1 48 25 0 2 54 24 1 3 57 29 0 4 65 38 0 5 69 36 0 6 78 40 1
Столбец пола теперь является фиктивной переменной, где:
- Значение 0 представляет «Женский».
- Значение 1 представляет «Мужской».
Пример 2. Создание нескольких фиктивных переменных
Предположим, у нас есть следующий DataFrame pandas:
import pandas as pd #createDataFrame df = pd. DataFrame ({' income ': [45, 48, 54, 57, 65, 69, 78], ' age ': [23, 25, 24, 29, 38, 36, 40], ' gender ': ['M', 'F', 'M', 'F', 'F', 'F', 'M'], ' college ': ['Y', 'N', 'N', 'N', 'Y', 'Y', 'Y']}) #view DataFrame df income age gender college 0 45 23 M Y 1 48 25 F N 2 54 24 M N 3 57 29 F N 4 65 38 F Y 5 69 36 F Y 6 78 40 M Y
Мы можем использовать функцию pd.get_dummies() для преобразования пола и колледжа в фиктивные переменные:
#convert gender to dummy variable p.d. get_dummies (df, columns=[' gender ', ' college '], drop_first= True ) income age gender_M college_Y 0 45 23 1 1 1 48 25 0 0 2 54 24 1 0 3 57 29 0 0 4 65 38 0 1 5 69 36 0 1 6 78 40 1 1
Столбец пола теперь является фиктивной переменной, где:
- Значение 0 представляет «Женский».
- Значение 1 представляет «Мужской».
И столбец колледжа теперь является фиктивной переменной, где:
- Значение 0 означает отсутствие университета.
- Значение 1 означает «Да» колледжу.
Дополнительные ресурсы
Как использовать фиктивные переменные в регрессионном анализе
Что такое ловушка фиктивной переменной?
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше