Как читать распределительную плату f
В этом руководстве объясняется, как читать и интерпретировать таблицу распределения F.
Что такое таблица распределения F?
Таблица распределения F представляет собой таблицу, в которой показаны критические значения распределения F. Чтобы использовать таблицу распределения F, вам нужны всего три значения:
- Степени свободы числителя
- Степени свободы знаменателя
- Альфа-уровень (обычно выбираются 0,01, 0,05 и 0,10)
В следующей таблице показана таблица распределения F для альфа = 0,10. Числа в верхней части таблицы представляют степени свободы числителя (обозначены в таблице DF1 ), а числа в левой части таблицы представляют степени свободы знаменателя (обозначены в таблице DF2 ).
Не стесняйтесь нажимать на таблицу для увеличения.
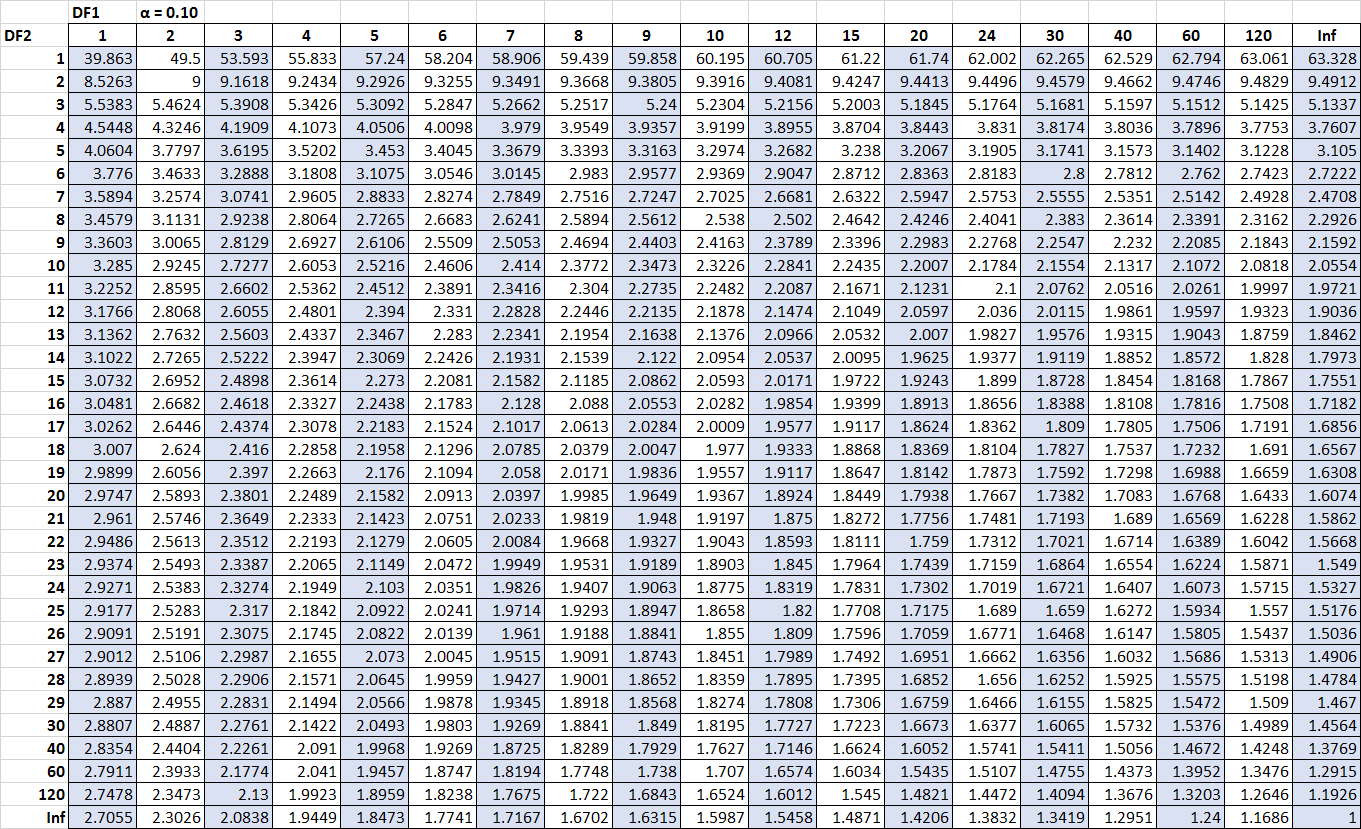
Критические значения в таблице часто сравнивают со статистикой F F-теста. Если статистика F больше критического значения, найденного в таблице, то вы можете отвергнуть нулевую гипотезу F-теста и сделать вывод, что результаты теста статистически значимы.
Примеры использования таблицы распределения F
Таблица распределения F используется для определения критического значения для F-теста. Три наиболее распространенных сценария, в которых вы будете выполнять F-тест:
- F-тест в регрессионном анализе для проверки общей значимости регрессионной модели.
- F-тест в ANOVA (дисперсионный анализ) для проверки общей разницы между средними значениями группы.
- F-тест, чтобы выяснить, имеют ли две популяции равные дисперсии.
Давайте посмотрим пример использования таблицы распределения F в каждом из этих сценариев.
F-тест в регрессионном анализе
Предположим, мы проводим множественный линейный регрессионный анализ, используя часы обучения и подготовительные экзамены, принимаемые в качестве предикторных переменных, а оценку за выпускной экзамен в качестве переменной ответа. Когда мы запускаем регрессионный анализ, мы получаем следующий результат:
| Источник | SS | дф | РС. | Ф | П. |
|---|---|---|---|---|---|
| Регрессия | 546,53 | 2 | 273,26 | 5.09 | 0,033 |
| Остаточный | 483,13 | 9 | 53,68 | ||
| Общий | 1029,66 | 11 |
В регрессионном анализе статистика f рассчитывается как регрессионное MS/остаточное MS. Эта статистика показывает, обеспечивает ли регрессионная модель лучшее соответствие данным, чем модель, не содержащая независимых переменных. По сути, он проверяет, полезна ли регрессионная модель в целом.
В этом примере статистика F равна 273,26/53,68 = 5,09 .
Предположим, мы хотим знать, значима ли эта статистика F на уровне альфа = 0,05. Используя таблицу распределения F для альфа = 0,05, со степенями свободы в числителе 2 ( df для регрессии) и степенями свободы в знаменателе 9 ( df для остатка) , мы находим, что критическое значение F равно 4, 2565 .
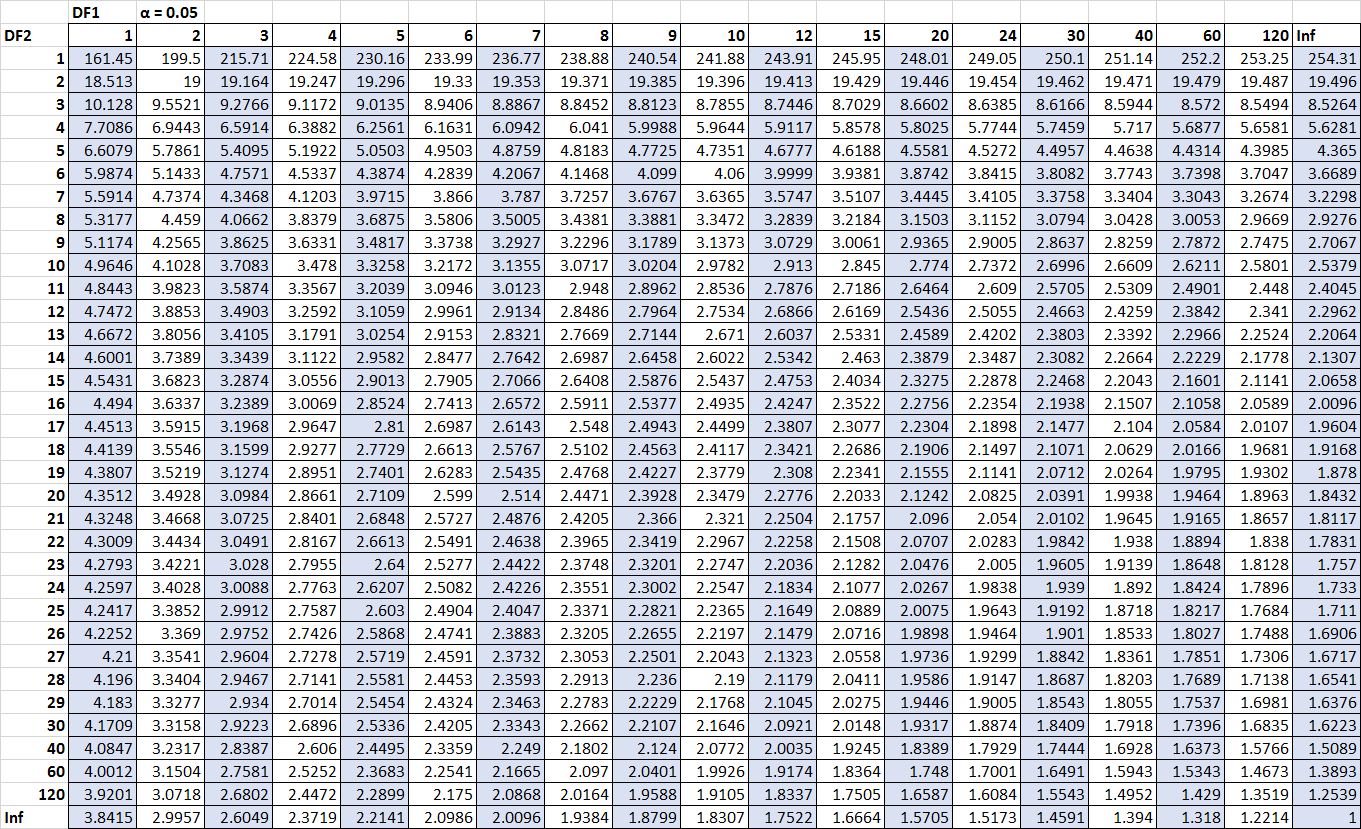
Поскольку наша статистика f( 5,09 ) больше критического значения F( 4,2565) , мы можем заключить, что регрессионная модель в целом статистически значима.
F-тест в ANOVA
Предположим, мы хотим знать, приводят ли три разных метода исследования к разным результатам тестов. Чтобы проверить это, мы набираем 60 студентов. Мы случайным образом назначаем каждому из 20 студентов использовать один из трех методов обучения в течение месяца при подготовке к экзамену. После того как все учащиеся сдали экзамен, мы проводим однофакторный дисперсионный анализ , чтобы определить, влияет ли методика обучения на результаты экзамена. В следующей таблице показаны результаты однофакторного дисперсионного анализа:
| Источник | SS | дф | РС. | Ф | П. |
|---|---|---|---|---|---|
| Уход | 58,8 | 2 | 29,4 | 1,74 | 0,217 |
| Ошибка | 202,8 | 12 | 16,9 | ||
| Общий | 261,6 | 14 |
В ANOVA статистика f рассчитывается как MS лечения/MS ошибки. Эта статистика показывает, равен ли средний балл трех групп или нет.
В этом примере статистика F равна 29,4/16,9 = 1,74 .
Предположим, мы хотим знать, значима ли эта статистика F на уровне альфа = 0,05. Используя таблицу распределения F для альфа = 0,05, с числителем степеней свободы 2 ( df для Лечение) и знаменателем степеней свободы 12 ( df для Error) , мы находим, что критическое значение F равно 3,8853 .
Поскольку наша статистика f ( 1,74 ) не превышает критического значения F ( 3,8853) , мы заключаем, что нет статистически значимой разницы между средними баллами трех групп.
F-тест для равных дисперсий двух популяций
Предположим, мы хотим знать, равны ли дисперсии двух совокупностей или нет. Чтобы проверить это, мы можем выполнить F-тест для равных дисперсий, в котором мы берем случайную выборку из 25 наблюдений из каждой совокупности и находим выборочную дисперсию для каждой выборки.
Статистика теста для этого F-теста определяется следующим образом:
Статистика F = с 1 2 / с 2 2
где s 1 2 и s 2 2 — выборочные дисперсии. Чем дальше это соотношение от единицы, тем сильнее доказательства неравных дисперсий внутри генеральной совокупности.
Критическое значение F-теста определяется следующим образом:
Критическое значение F = значение, найденное в таблице распределения F с n 1 -1 и n 2 -1 степенями свободы и уровнем значимости α.
Предположим, что выборочная дисперсия для выборки 1 равна 30,5, а выборочная дисперсия для выборки 2 равна 20,5. Это означает, что наша тестовая статистика равна 30,5/20,5 = 1,487 . Чтобы выяснить, является ли эта тестовая статистика значимой при альфа = 0,10, мы можем найти критическое значение в таблице распределения F, связанной с альфа = 0,10, числителем df = 24 и знаменателем df = 24. Это число оказалось равным 1,7019. .
Поскольку наша статистика f( 1,487 ) не превышает критического значения F( 1,7019) , мы заключаем, что нет статистически значимой разницы между дисперсиями этих двух популяций.
Дополнительные ресурсы
Полный набор таблиц распределения F для значений альфа 0,001, 0,01, 0,025, 0,05 и 0,10 смотрите на этой странице .
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше