Excel: как удалить повторяющиеся строки на основе столбца
Часто вам может потребоваться удалить повторяющиеся строки на основе столбца в Excel.
К счастью, это легко сделать с помощью функции «Удалить дубликаты» на вкладке «Данные» .
В следующем примере показано, как использовать эту функцию на практике.
Пример. Удаление дубликатов на основе столбца в Excel
Допустим, у нас есть следующий набор данных в Excel, содержащий информацию о различных баскетболистах:
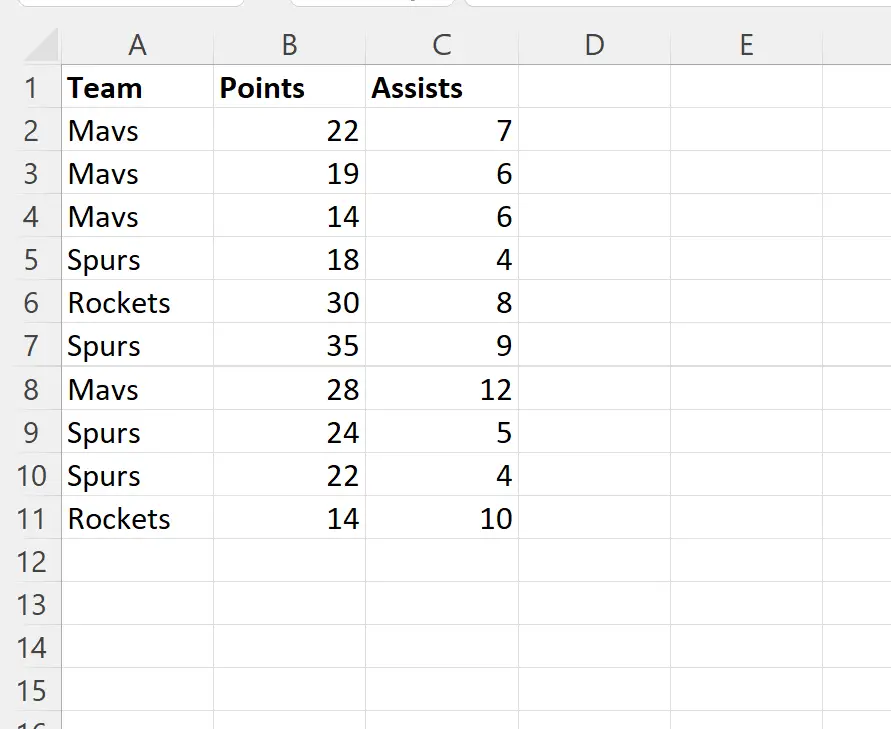
Обратите внимание, что в столбце «Команда» есть несколько повторяющихся значений.
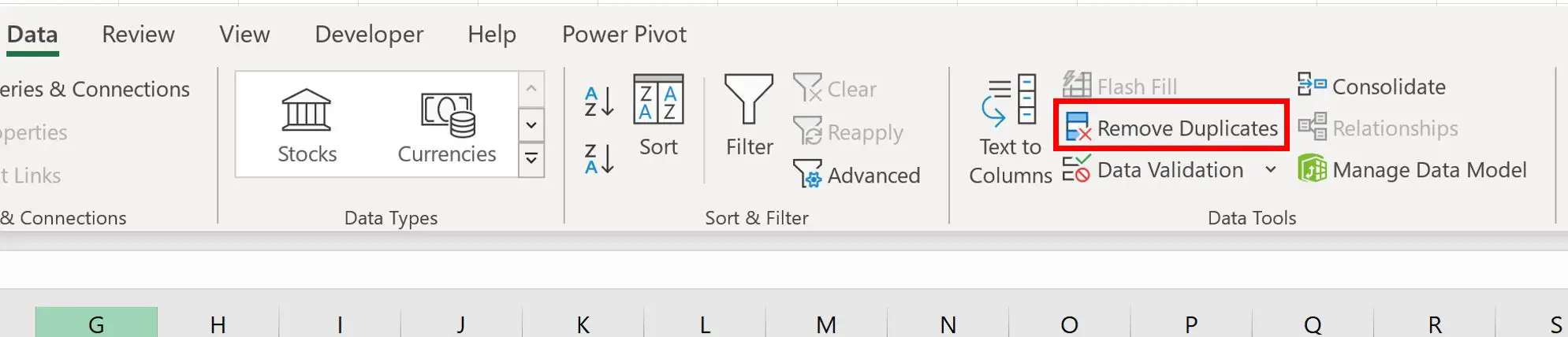
Чтобы удалить строки с повторяющимися значениями в столбце «Команда» , выделите диапазон ячеек A1:C11 , затем щелкните вкладку «Данные» на верхней ленте и нажмите «Удалить дубликаты »:
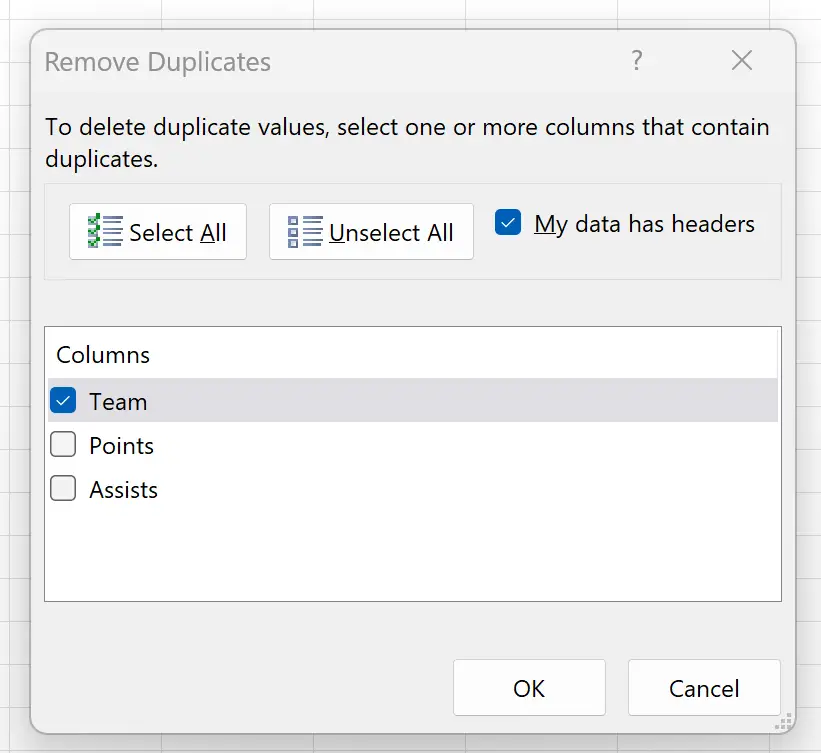
В появившемся новом окне убедитесь, что установлен флажок рядом с пунктом «Мои данные имеют заголовки» , и убедитесь, что установлен только флажок рядом с пунктом «Команда» :
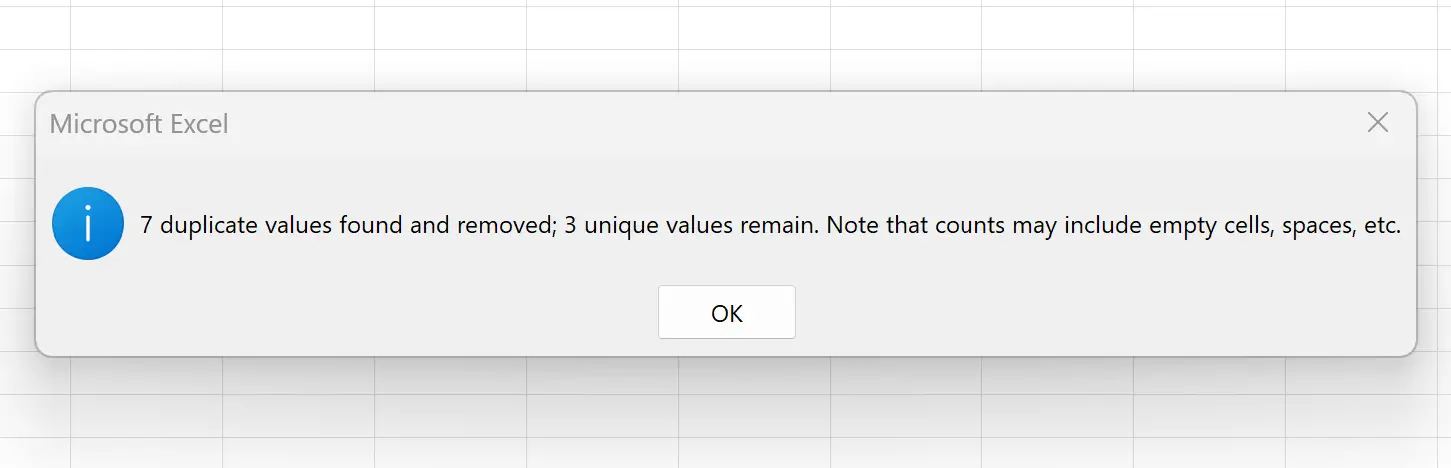
Как только вы нажмете «ОК» , строки с повторяющимися значениями в столбце «Команда» будут автоматически удалены:
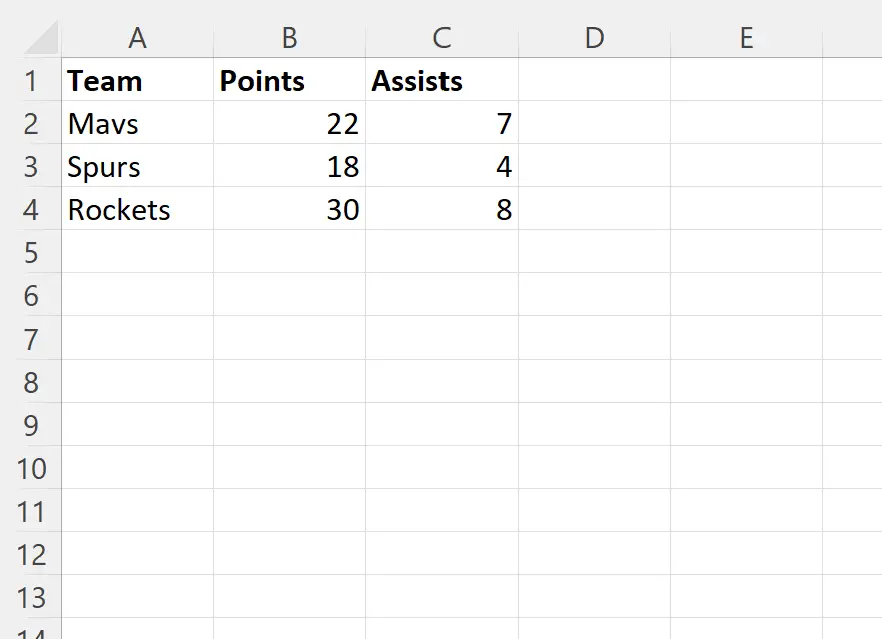
Excel сообщает нам, что было найдено и удалено 7 повторяющихся строк, а осталось 3 уникальных строки.
Обратите внимание, что ни одна из оставшихся строк не имеет повторяющихся значений в столбце «Команда» .
Также обратите внимание, что строка, содержащая первое вхождение каждого уникального названия команды, сохраняется.
Например:
- Строка с «Мавсом», 22 очками и 7 передачами — это первая строка в наборе данных со словом «Мавс» в столбце «Команда» .
- Строка со «Шпорами», 18 очками и 4 передачами — это первая строка в наборе данных со словом «Шпоры» в столбце «Команда» .
И так далее.
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные операции в Excel:
Excel: как удалить строки с определенным текстом
Excel: как игнорировать пустые ячейки при использовании формул
Расширенный фильтр Excel: показывать строки с непустыми значениями
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше