Pandas: импортируйте csv с разным количеством столбцов в строке
Вы можете использовать следующий базовый синтаксис для импорта файла CSV в pandas, если в строке имеется разное количество столбцов:
df = pd. read_csv (' uneven_data.csv ', header= None , names=range( 4 ))
Значением внутри функции range() должно быть количество столбцов в строке с максимальным количеством столбцов.
В следующем примере показано, как использовать этот синтаксис на практике.
Пример: импорт CSV в Pandas с разным количеством столбцов в строке.
Допустим, у нас есть следующий CSV-файл с именем uneven_data.csv :
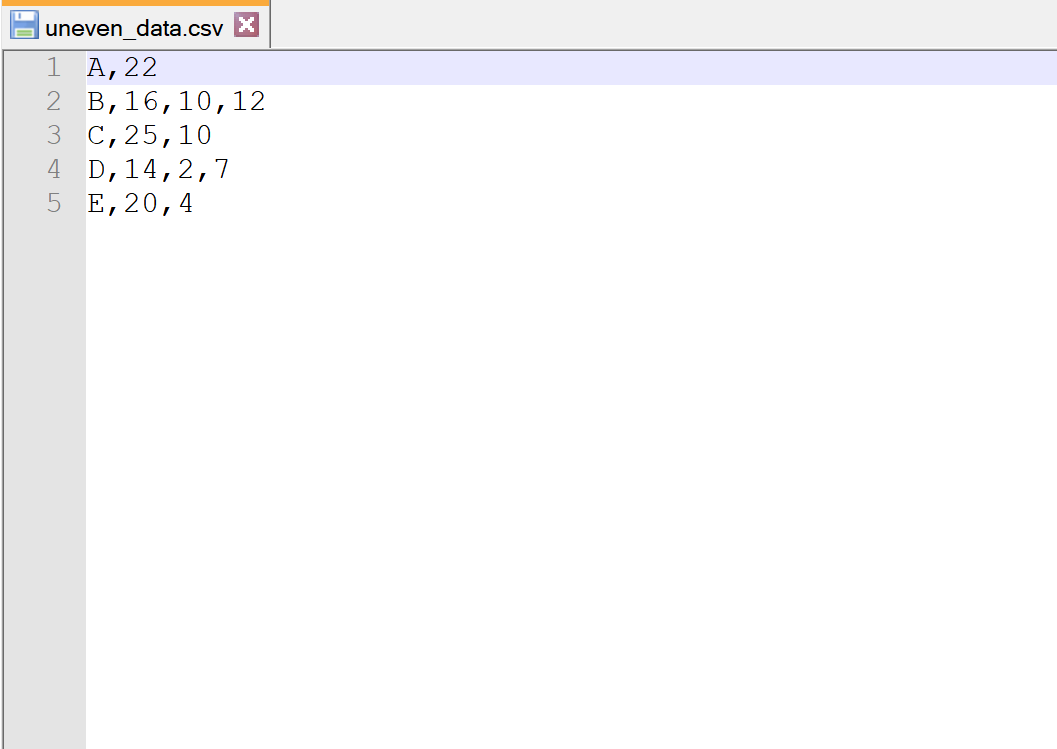
Обратите внимание, что каждая строка имеет разное количество столбцов.
Если мы попытаемся использовать функцию read_csv() для импорта этого CSV-файла в DataFrame pandas, мы получим ошибку:
import pandas as pd #attempt to import CSV file with differing number of columns per row df = pd. read_csv (' uneven_data.csv ', header= None ) ParserError: Error tokenizing data. C error: Expected 2 fields in line 2, saw 4
Мы получаем ошибку ParserError , которая сообщает нам, что pandas ожидал 2 поля (так как это было количество столбцов в первой строке), но увидел 4 .
Эта ошибка сообщает нам, что максимальное количество столбцов в данной строке равно 4 .
Итак, мы можем импортировать файл CSV и указать значение диапазона (4) в аргументе имен :
import pandas as pd #import CSV file with differing number of columns per row df = pd. read_csv (' uneven_data.csv ', header= None , names=range( 4 ))) #view DataFrame print (df) 0 1 2 3 0 to 22 NaN NaN 1 B 16 10.0 12.0 2 C 25 10.0 NaN 3 D 14 2.0 7.0 4 E 20 4.0 NaN
Обратите внимание, что мы можем успешно импортировать CSV-файл в DataFrame pandas без каких-либо ошибок, поскольку мы явно сказали пандам ожидать 4 столбца.
По умолчанию pandas заполняет все пропущенные значения в каждой строке значением NaN.
Если вы хотите, чтобы пропущенные значения отображались как ноль, вы можете использовать функцию fillna() следующим образом:
#fill NaN values with zeros df_new = df. fillna ( 0 ) #view new DataFrame print (df_new) 0 1 2 3 0 to 22 0.0 0.0 1 B 16 10.0 12.0 2 C 25 10.0 0.0 3 D 14 2.0 7.0 4 E 20 4.0 0.0
Каждое значение NaN в DataFrame теперь заменено нулем.
Примечание . Полную документацию по функции pandas read_csv() можно найти здесь .
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные задачи на Python:
Pandas: как пропускать строки при чтении файла CSV
Pandas: как добавить данные в существующий файл CSV
Pandas: как указать типы при импорте файла CSV
Pandas: задайте имена столбцов при импорте файла CSV
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше