Как прочитать определенные строки из файла csv в r
Вы можете использовать следующие методы для чтения определенных строк из файла CSV в R:
Способ 1. Импортируйте CSV-файл из определенной строки.
df <- read. csv (" my_data.csv ", skip= 2 )
В этом конкретном примере будут пропущены первые две строки файла CSV и импортированы все остальные строки файла, начиная с третьей строки.
Способ 2. Импортируйте файл CSV, строки которого соответствуют условию.
library (sqldf) df <- read. csv . sql (" my_data.csv ", sql = " select * from file where `points` > 90 ", eol = " \n ")
В этом конкретном примере из файла CSV будут импортированы только строки, значение которых в столбце «точки» превышает 90.
В следующих примерах показано, как использовать каждый из этих методов на практике со следующим CSV-файлом с именем my_data.csv :
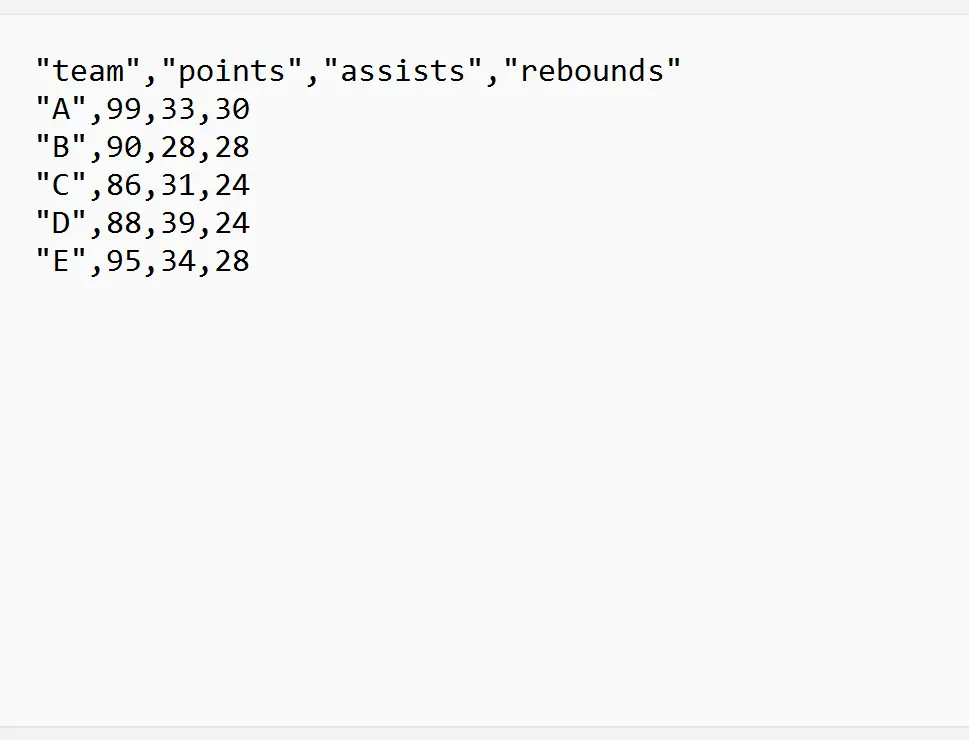
Пример 1. Импортируйте CSV-файл из определенной строки.
Следующий код показывает, как импортировать файл CSV, игнорируя первые две строки файла:
#import data frame and skip first two rows
df <- read. csv (' my_data.csv ', skip= 2 )
#view data frame
df
B X90 X28 X28.1
1 C 86 31 24
2 D 88 39 24
3 E 95 34 28
Обратите внимание, что первые две строки (с командами A и B) были проигнорированы при импорте файла CSV.
По умолчанию R пытается использовать значения следующей доступной строки в качестве имен столбцов.
Чтобы переименовать столбцы, вы можете использовать функцию Names() следующим образом:
#rename columns
names(df) <- c(' team ', ' points ', ' assists ', ' rebounds ')
#view updated data frame
df
team points assists rebounds
1 C 86 31 24
2 D 88 39 24
3 E 95 34 28
Пример 2. Импортируйте файл CSV, строки которого соответствуют условию.
Предположим, мы хотим импортировать из CSV-файла только те строки, значение которых в столбце точек больше 90.
Для этого мы можем использовать функцию read.csv.sql из пакета sqldf :
library (sqldf)
#only import rows where points > 90
df <- read. csv . sql (" my_data.csv ",
sql = " select * from file where `points` > 90 ", eol = " \n ")
#view data frame
df
team points assists rebounds
1 “A” 99 33 30
2 “E” 95 34 28
Обратите внимание, что были импортированы только две строки файла CSV, значение которых в столбце «точки» превышает 90.
Примечание № 1. В этом примере мы использовали аргумент eol , чтобы указать, что «конец строки» в файле обозначается \n , который представляет собой новую строку.
Примечание № 2. В этом примере мы использовали простой SQL-запрос, но вы можете написать более сложные запросы для фильтрации строк по еще большему количеству условий.
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные задачи в R:
Как прочитать CSV по URL-адресу в R
Как объединить несколько файлов CSV в R
Как экспортировать фрейм данных в файл CSV в R
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше