Как выполнить множественную линейную регрессию в spss
Множественная линейная регрессия — это метод, который мы можем использовать, чтобы понять взаимосвязь между двумя или более объясняющими переменными и переменной отклика.
В этом руководстве объясняется, как выполнить множественную линейную регрессию в SPSS.
Пример: множественная линейная регрессия в SPSS
Предположим, мы хотим знать, влияет ли количество часов, потраченных на обучение, и количество сданных практических экзаменов на оценку, которую студент получает на данном экзамене. Чтобы изучить это, мы можем выполнить множественную линейную регрессию, используя следующие переменные:
Пояснительные переменные:
- Количество изученных часов
- Подготовительные экзамены сданы
Переменная ответа:
- Результаты экзамена
Используйте следующие шаги, чтобы выполнить эту множественную линейную регрессию в SPSS.
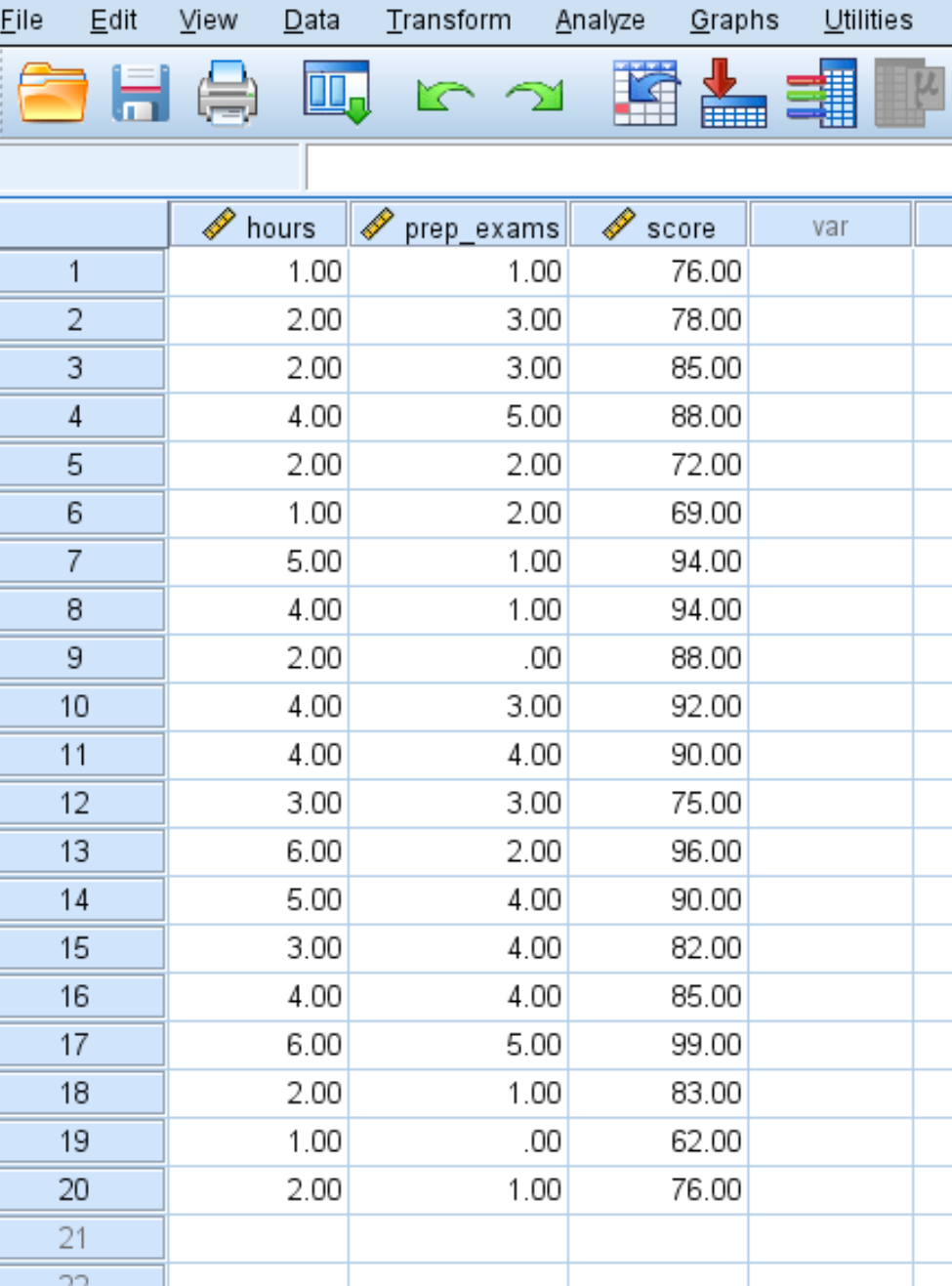
Шаг 1: Введите данные.
Введите следующие данные о количестве учебных часов, сданных подготовительных экзаменов и полученных результатах экзаменов для 20 студентов:
Шаг 2. Выполните множественную линейную регрессию.
Перейдите на вкладку «Анализ» , затем «Регрессия» , затем «Линейная» :
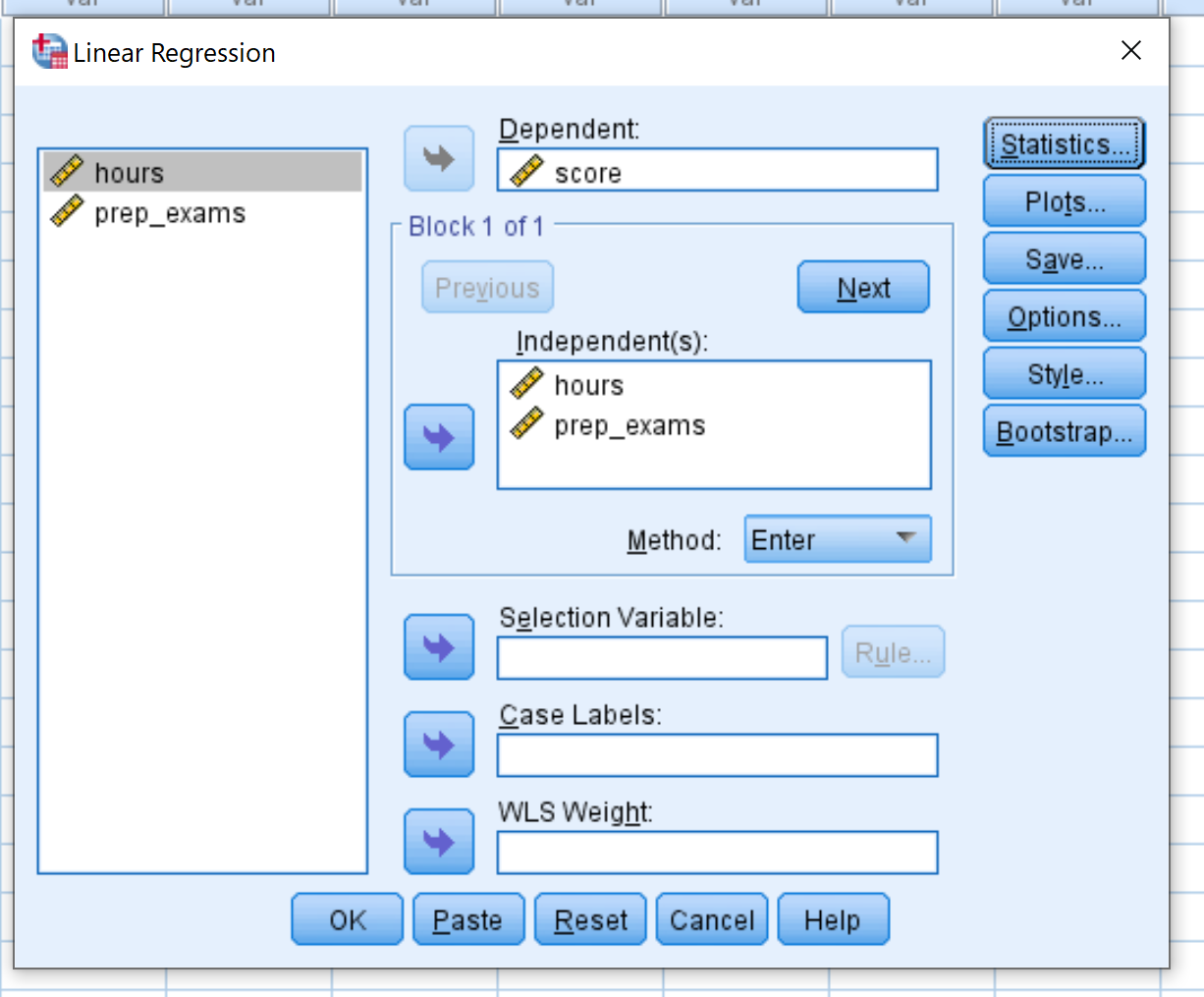
Перетащите переменную оценку в поле «Зависимый». Перетащите переменные часы и prep_exams в поле с надписью «Независимые». Затем нажмите ОК .
Шаг 3: Интерпретируйте результат.
Как только вы нажмете «ОК» , результаты множественной линейной регрессии появятся в новом окне.
Первая таблица, которая нас интересует, называется Model Summary :
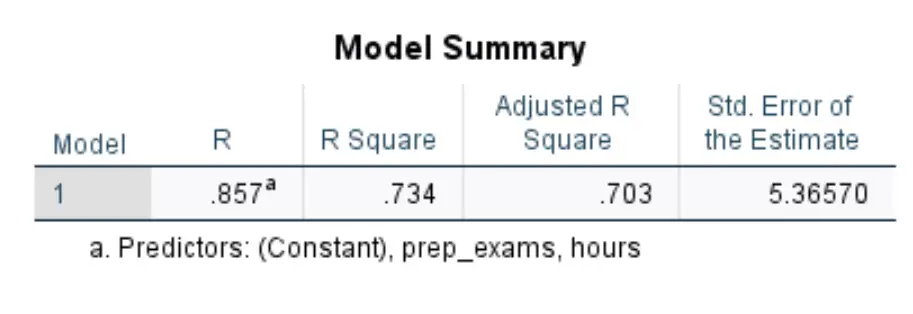
Вот как интерпретировать наиболее важные цифры в этой таблице:
- R-квадрат: это доля дисперсии переменной ответа, которую можно объяснить объясняющими переменными. В этом примере 73,4% различий в результатах экзаменов можно объяснить количеством учебных часов и количеством сданных подготовительных экзаменов.
- Стандарт. Ошибка оценки: стандартная ошибка — это среднее расстояние между наблюдаемыми значениями и линией регрессии. В данном примере наблюдаемые значения отклоняются в среднем на 5,3657 единиц от линии регрессии.
Следующая таблица, которая нас интересует, называется ANOVA :
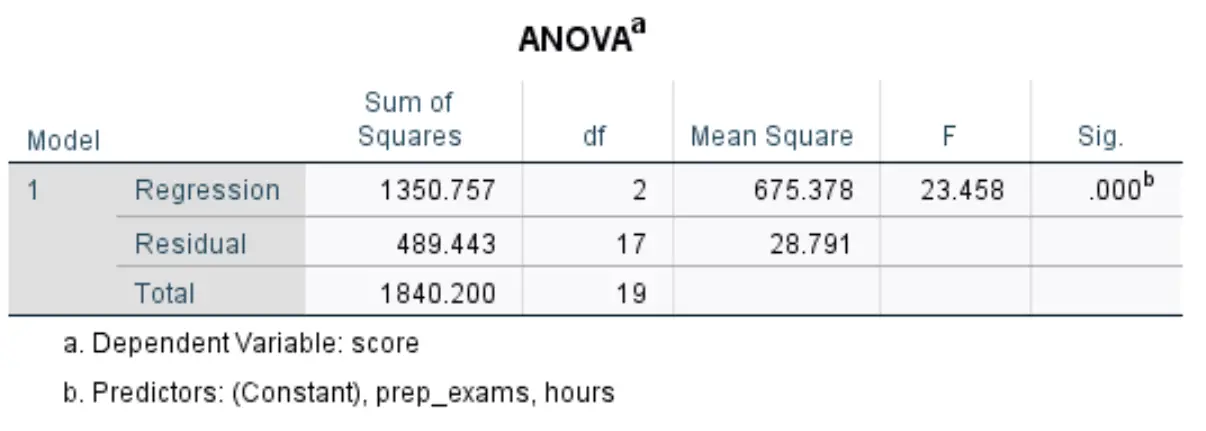
Вот как интерпретировать наиболее важные цифры в этой таблице:
- F: это общая статистика F для регрессионной модели, рассчитанная как среднеквадратическая регрессия / среднеквадратическая невязка.
- Sig: Это значение p, связанное с общей статистикой F. Это говорит нам, является ли регрессионная модель в целом статистически значимой или нет. Другими словами, он говорит нам, имеют ли две объединенные объясняющие переменные статистически значимую связь с переменной ответа. В этом случае значение p равно 0,000, что указывает на то, что объясняющие переменные, часы обучения и сданные подготовительные экзамены имеют статистически значимую связь с результатом экзамена.
Следующая таблица, которая нас интересует, называется Коэффициенты :
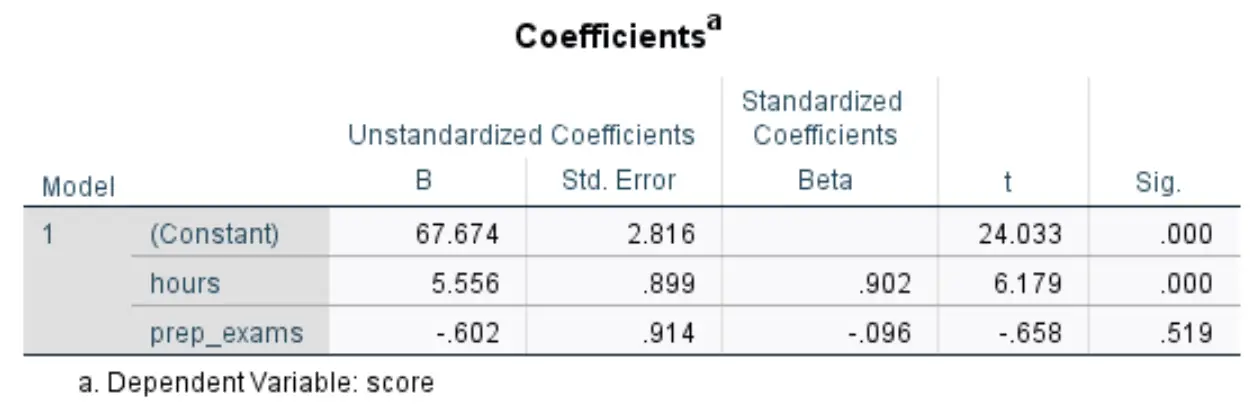
Вот как интерпретировать наиболее важные цифры в этой таблице:
- B нестандартизированный (постоянный): это говорит нам о среднем значении переменной ответа, когда обе переменные-предикторы равны нулю. В этом примере средний балл на экзамене составляет 67 674 , когда часы обучения и сданные подготовительные экзамены равны нулю.
- Нестандартизированный B (часы): Это говорит нам о среднем изменении экзаменационных баллов, связанном с увеличением учебных часов на одну единицу, при условии, что количество сданных подготовительных экзаменов остается постоянным. В этом случае каждый дополнительный час, потраченный на обучение, связан с увеличением экзаменационной оценки на 5556 баллов при условии, что количество сдаваемых практических экзаменов остается постоянным.
- Нестандартизированный B (prep_exams): это говорит нам о среднем изменении экзаменационного балла, связанном с увеличением количества сданных подготовительных экзаменов на одну единицу, при условии, что количество учебных часов остается постоянным. В этом случае каждый дополнительный сданный подготовительный экзамен связан со снижением экзаменационной оценки на 0,602 балла при условии, что количество изучаемых часов остается постоянным.
- Сиг. (часы): это значение p для объясняющей переменной Часы . Поскольку это значение (0,000) меньше 0,05, мы можем заключить, что изученные часы имеют статистически значимую связь с оценками на экзаменах.
- Сиг. (prep_exams): это значение p для объясняющей переменной prep_exams . Поскольку это значение (0,519) не меньше 0,05, мы не можем заключить, что количество сданных подготовительных экзаменов имеет статистически значимую связь с результатом экзамена.
Наконец, мы можем сформировать уравнение регрессии, используя приведенные в таблице значения констант , часов и prep_exams . В этом случае уравнение будет иметь вид:
Предполагаемый балл за экзамен = 67,674 + 5,556*(часы) – 0,602*(prep_exams)
Мы можем использовать это уравнение, чтобы найти примерный балл студента на экзамене, исходя из количества часов обучения и количества сданных практических экзаменов. Например, студент, который учится 3 часа и сдает 2 подготовительных экзамена, должен получить экзаменационный балл 83,1:
Предполагаемый балл на экзамене = 67,674 + 5,556*(3) – 0,602*(2) = 83,1
Примечание. Поскольку независимая переменная для подготовительных экзаменов не оказалась статистически значимой, мы можем решить удалить ее из модели и вместо этого выполнить простую линейную регрессию , используя изученные часы в качестве единственной объясняющей переменной.
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше