Как выполнить вложенный дисперсионный анализ в r (шаг за шагом)
Вложенный дисперсионный анализ — это тип дисперсионного анализа («дисперсионный анализ»), в котором по крайней мере один фактор вложен в другой фактор.
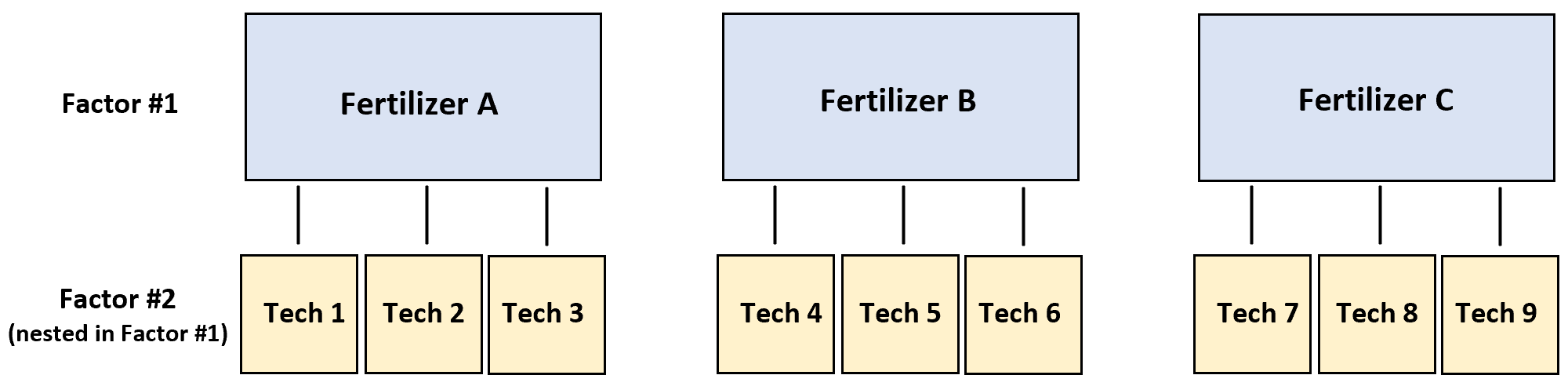
Например, предположим, что исследователь хочет знать, обеспечивают ли три разных удобрения разные уровни роста растений.
Чтобы проверить это, три разных техника опрыскивают удобрением А по четыре растения, трое других техников опрыскивают удобрением В по четыре растения и еще три техника опрыскивают удобрением С по четыре растения.
В этом сценарии переменной отклика является рост растений, а двумя факторами являются техника и удобрения. Оказывается, в удобрении угнездилась техника:
В следующем пошаговом примере показано, как выполнить этот вложенный дисперсионный анализ в R.
Шаг 1. Создайте данные
Во-первых, давайте создадим фрейм данных для хранения наших данных в R:
#create data df <- data. frame (growth=c(13, 16, 16, 12, 15, 16, 19, 16, 15, 15, 12, 15, 19, 19, 20, 22, 23, 18, 16, 18, 19, 20, 21, 21, 21, 23, 24, 22, 25, 20, 20, 22, 24, 22, 25, 26), fertilizer=c(rep(c(' A ', ' B ', ' C '), each= 12 )), tech=c(rep(1:9, each= 4 ))) #view first six rows of data head(df) growth fertilizer tech 1 13 A 1 2 16 A 1 3 16 A 1 4 12 A 1 5 15 A 2 6 16 A 2
Шаг 2. Настройте вложенный дисперсионный анализ
Мы можем использовать следующий синтаксис для соответствия вложенному дисперсионному анализу в R:
aov(ответ ~ фактор А/фактор Б)
Золото:
- ответ: переменная ответа
- фактор А: первый фактор
- фактор B: второй фактор, вложенный в первый фактор
Следующий код показывает, как подогнать вложенный дисперсионный анализ для нашего набора данных:
#fit nested ANOVA nest <- aov(df$growth ~ df$fertilizer / factor(df$tech)) #view summary of nested ANOVA summary(nest) Df Sum Sq Mean Sq F value Pr(>F) df$fertilizer 2 372.7 186.33 53.238 4.27e-10 *** df$fertilizer:factor(df$tech) 6 31.8 5.31 1.516 0.211 Residuals 27 94.5 3.50 --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Шаг 3: Интерпретируйте результат
Мы можем посмотреть на столбец значений p, чтобы определить, оказывает ли каждый фактор статистически значимое влияние на рост растений.
Из приведенной выше таблицы мы видим, что удобрения оказывают статистически значимое влияние на рост растений (значение p <0,05), а техник — нет (значение p = 0,211).
Это говорит нам о том, что если мы хотим увеличить рост растений, нам нужно сосредоточиться на используемых удобрениях, а не на отдельных специалистах, применяющих удобрения.
Шаг 4. Визуализируйте результаты
Наконец, мы можем использовать коробчатые диаграммы, чтобы визуализировать распределение роста растений по удобрениям и техникам:
#load ggplot2 data visualization package library (ggplot2) #create boxplots to visualize plant growth ggplot(df, aes (x=factor(tech), y=growth, fill=fertilizer)) + geom_boxplot()
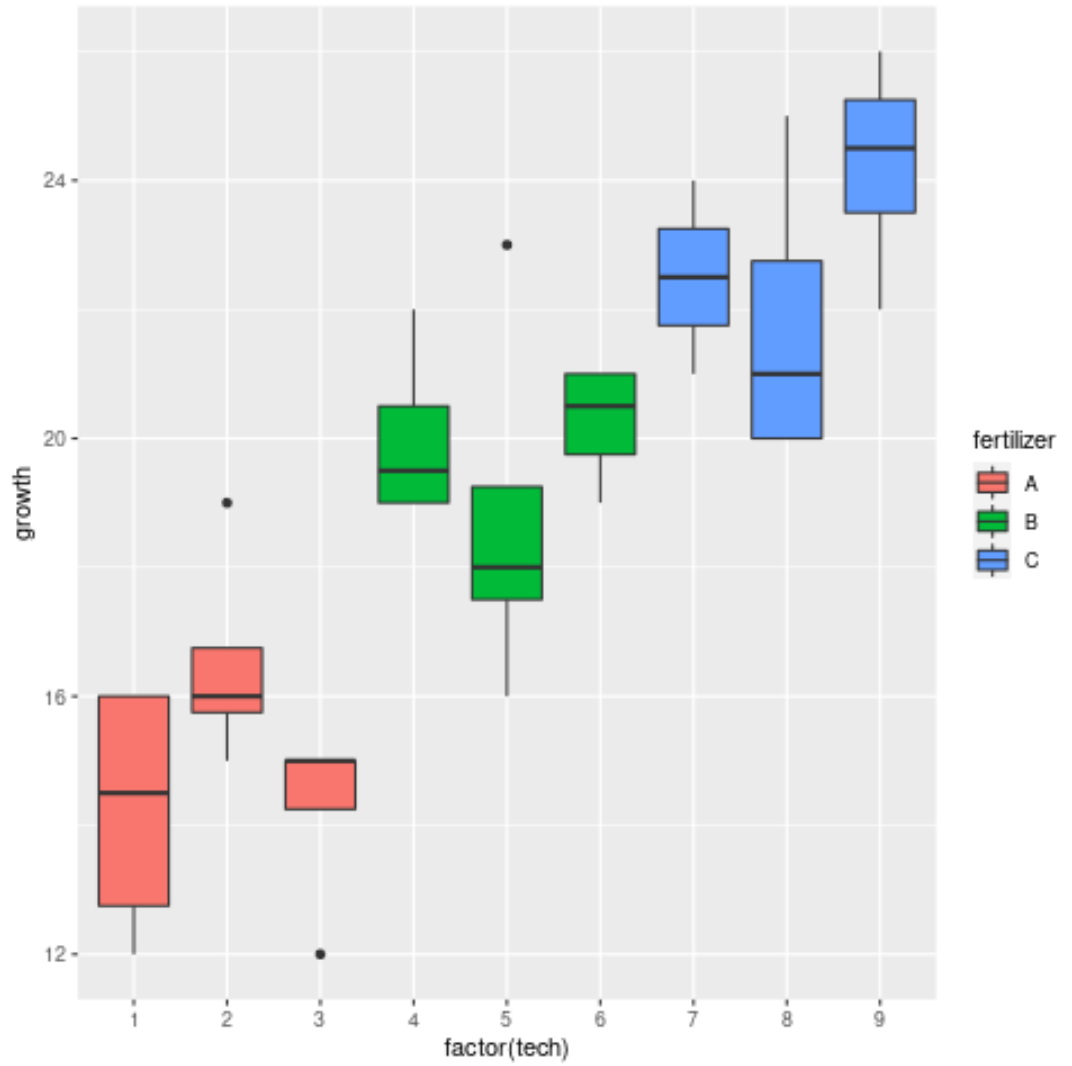
График показывает, что существуют значительные различия в росте между тремя различными удобрениями, но не такие большие различия между техническими специалистами в каждой группе удобрений.
Похоже, это соответствует результатам вложенного дисперсионного анализа и подтверждает, что удобрения оказывают существенное влияние на рост растений, а отдельные специалисты — нет.
Дополнительные ресурсы
Как выполнить односторонний дисперсионный анализ в R
Как выполнить двусторонний дисперсионный анализ в R
Как выполнить повторные измерения ANOVA в R
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше