Равночастотное биннинг в python
В статистике группировка — это процесс объединения числовых значений в группы .
Наиболее распространенная форма кластеризации известна как кластеризация равной ширины , при которой мы делим набор данных на k групп одинаковой ширины.
Менее часто используемая форма кластеризации известна как кластеризация с равной частотой , при которой мы делим набор данных на k групп, каждая из которых имеет одинаковое количество частот.
В этом руководстве объясняется, как выполнить кластеризацию с равной частотой в Python.
Равночастотное биннинг в Python
Предположим, у нас есть набор данных, содержащий 100 значений:
import numpy as np import matplotlib.pyplot as plt #create data np.random.seed(1) data = np.random.randn(100) #view first 5 values data[:5] array([ 1.62434536, -0.61175641, -0.52817175, -1.07296862, 0.86540763])
Группировка одинаковой ширины:
Если мы создадим гистограмму для отображения этих значений, Python по умолчанию будет использовать группировку одинаковой ширины:
#create histogram with equal-width bins n, bins, patches = plt.hist(data, edgecolor='black') plt.show() #display bin boundaries and frequency per bin bins, n (array([-2.3015387 , -1.85282729, -1.40411588, -0.95540447, -0.50669306, -0.05798165, 0.39072977, 0.83944118, 1.28815259, 1.736864, 2.18557541]), array([ 3., 1., 6., 17., 19., 20., 14., 12., 5., 3.]))
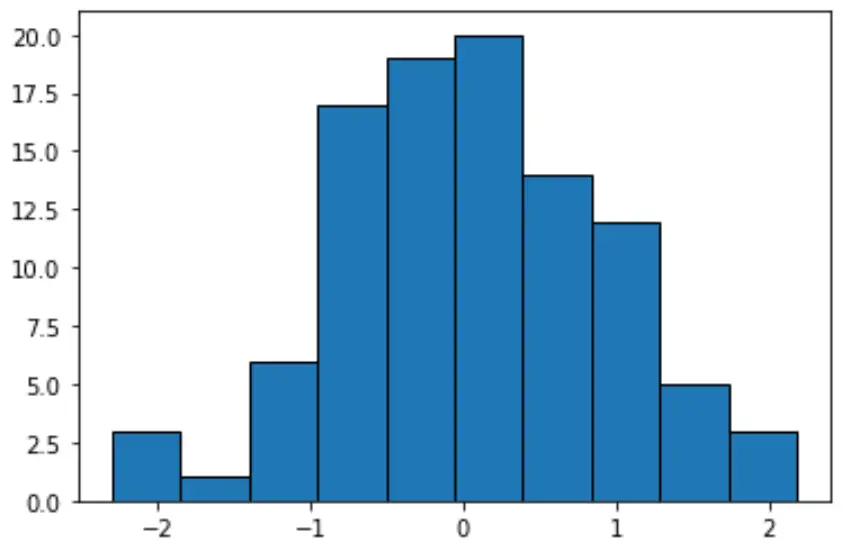
Каждая группа имеет одинаковую ширину примерно 0,4487, но каждая группа не содержит одинаковое количество наблюдений. Например:
- Первый интервал простирается от -2,3015387 до -1,8528279 и содержит 3 наблюдения.
- Второй интервал простирается от -1,8528279 до -1,40411588 и содержит 1 наблюдение.
- Третий интервал простирается от -1,40411588 до -0,95540447 и содержит 6 наблюдений.
И так далее.
Равночастотная группировка:
Чтобы создать сегменты, содержащие равное количество наблюдений, мы можем использовать следующую функцию:
#define function to calculate equal-frequency bins def equalObs(x, nbin): nlen = len(x) return np.interp(np.linspace(0, nlen, nbin + 1), np.arange(nlen), np.sort(x)) #create histogram with equal-frequency bins n, bins, patches = plt.hist(data, equalObs(data, 10), edgecolor='black') plt.show() #display bin boundaries and frequency per bin bins, n (array([-2.3015387 , -0.93576943, -0.67124613, -0.37528495, -0.20889423, 0.07734007, 0.2344157, 0.51292982, 0.86540763, 1.19891788, 2.18557541]), array([10., 10., 10., 10., 10., 10., 10., 10., 10., 10.]))
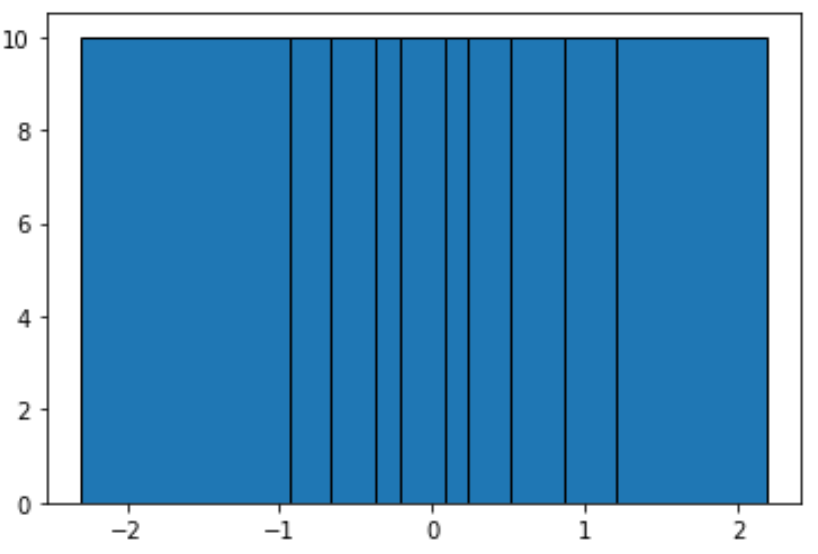
Каждая группа не одинакова по ширине, но каждая группа содержит равное количество наблюдений. Например:
- Первый интервал простирается от -2,3015387 до -0,93576943 и содержит 10 наблюдений.
- Второй интервал простирается от -0,93576943 до -0,67124613 и содержит 10 наблюдений.
- Третий интервал простирается от -0,67124613 до -0,37528495 и содержит 10 наблюдений.
И так далее.
Из гистограммы видно, что каждый бин явно имеет разную ширину, но каждый бин содержит одинаковое количество наблюдений, что подтверждается тем фактом, что высота каждого бина одинакова.
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше