Как рассчитать взвешенное стандартное отклонение в python
Взвешенное стандартное отклонение — это полезный способ измерения дисперсии значений в наборе данных, когда некоторые значения в наборе данных имеют более высокие веса, чем другие.
Формула для расчета взвешенного стандартного отклонения:
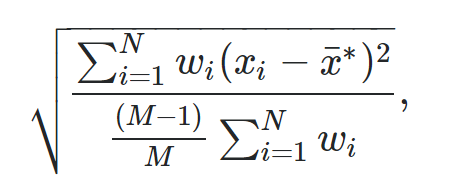
Золото:
- N: Общее количество наблюдений
- M: количество ненулевых весов.
- w i : Весовой вектор
- x i : вектор значений данных
- x : Средневзвешенное значение
Самый простой способ рассчитать взвешенное стандартное отклонение в Python — использовать функцию DescrStatsW() из пакета statsmodels:
DescrStatsW(values, weights=weights, ddof= 1 ). std
В следующем примере показано, как использовать эту функцию на практике.
Пример: взвешенное стандартное отклонение в Python
Предположим, у нас есть следующий массив значений данных и соответствующие веса:
#define data values values = [14, 19, 22, 25, 29, 31, 31, 38, 40, 41] #define weights weights = [1, 1, 1.5, 2, 2, 1.5, 1, 2, 3, 2]
Следующий код показывает, как вычислить взвешенное стандартное отклонение для этого массива значений данных:
from statsmodels. stats . weightstats import DescrStatsW
#calculate weighted standard deviation
DescrStatsW(values, weights=weights, ddof= 1 ). std
8.570050878426773
Взвешенное стандартное отклонение оказывается равным 8,57 .
Обратите внимание, что мы также можем использовать var для быстрого расчета взвешенной дисперсии:
from statsmodels. stats . weightstats import DescrStatsW
#calculate weighted variance
DescrStatsW(values, weights=weights, ddof= 1 ). var
73.44577205882352
Взвешенная дисперсия оказывается равной 73 446 .
Дополнительные ресурсы
В следующих руководствах объясняется, как рассчитать взвешенное стандартное отклонение в другом статистическом программном обеспечении:
Как рассчитать взвешенное стандартное отклонение в Excel
Как рассчитать взвешенное стандартное отклонение в R
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше