Ридж-регрессия в r (шаг за шагом)
Ридж-регрессия — это метод, который мы можем использовать для подбора модели регрессии, когда в данных присутствует мультиколлинеарность .
Короче говоря, регрессия наименьших квадратов пытается найти оценки коэффициентов, которые минимизируют остаточную сумму квадратов (RSS):
RSS = Σ(y i – ŷ i )2
Золото:
- Σ : греческий символ, означающий сумму.
- y i : фактическое значение ответа для i-го наблюдения
- ŷ i : прогнозируемое значение ответа на основе модели множественной линейной регрессии.
И наоборот, гребневая регрессия стремится свести к минимуму следующее:
RSS + λΣβ j 2
где j изменяется от 1 до p переменных-предикторов и λ ≥ 0.
Этот второй член в уравнении известен как штраф за снятие средств . В гребневой регрессии мы выбираем значение λ, которое дает минимально возможный тест MSE (среднеквадратическая ошибка).
В этом руководстве представлен пошаговый пример выполнения гребневой регрессии в R.
Шаг 1. Загрузите данные
В этом примере мы будем использовать встроенный набор данных R под названием mtcars . Мы будем использовать hp в качестве переменной ответа и следующие переменные в качестве предикторов:
- миль на галлон
- масса
- дерьмо
- qsec
Для выполнения ридж-регрессии мы будем использовать функции из пакета glmnet . Этот пакет требует, чтобы переменная ответа была вектором, а набор переменных-предикторов принадлежал к классу data.matrix .
Следующий код показывает, как определить наши данные:
#define response variable
y <- mtcars$hp
#define matrix of predictor variables
x <- data.matrix(mtcars[, c('mpg', 'wt', 'drat', 'qsec')])
Шаг 2. Подбор модели регрессии риджа
Далее мы воспользуемся функцией glmnet() , чтобы соответствовать модели регрессии Риджа, и укажем альфа=0 .
Обратите внимание, что установка альфа, равная 1, эквивалентна использованию регрессии Лассо, а установка альфа на значение от 0 до 1 эквивалентна использованию эластичной сети.
Также обратите внимание, что гребневая регрессия требует, чтобы данные были стандартизированы таким образом, чтобы каждая переменная-предиктор имела среднее значение 0 и стандартное отклонение 1.
К счастью, glmnet() автоматически выполняет эту стандартизацию за вас. Если вы уже стандартизировали переменные, вы можете указать стандартизировать=False .
library (glmnet)
#fit ridge regression model
model <- glmnet(x, y, alpha = 0 )
#view summary of model
summary(model)
Length Class Mode
a0 100 -none- numeric
beta 400 dgCMatrix S4
df 100 -none- numeric
dim 2 -none- numeric
lambda 100 -none- numeric
dev.ratio 100 -none- numeric
nulldev 1 -none- numeric
npasses 1 -none- numeric
jerr 1 -none- numeric
offset 1 -none- logical
call 4 -none- call
nobs 1 -none- numeric
Шаг 3. Выберите оптимальное значение лямбды.
Далее мы определим значение лямбда, которое дает наименьшую среднеквадратическую ошибку теста (MSE), используя k-кратную перекрестную проверку .
К счастью, в glmnet есть функция cv.glmnet() , которая автоматически выполняет k-кратную перекрестную проверку, используя k = 10 раз.
#perform k-fold cross-validation to find optimal lambda value
cv_model <- cv. glmnet (x, y, alpha = 0 )
#find optimal lambda value that minimizes test MSE
best_lambda <- cv_model$ lambda . min
best_lambda
[1] 10.04567
#produce plot of test MSE by lambda value
plot(cv_model)
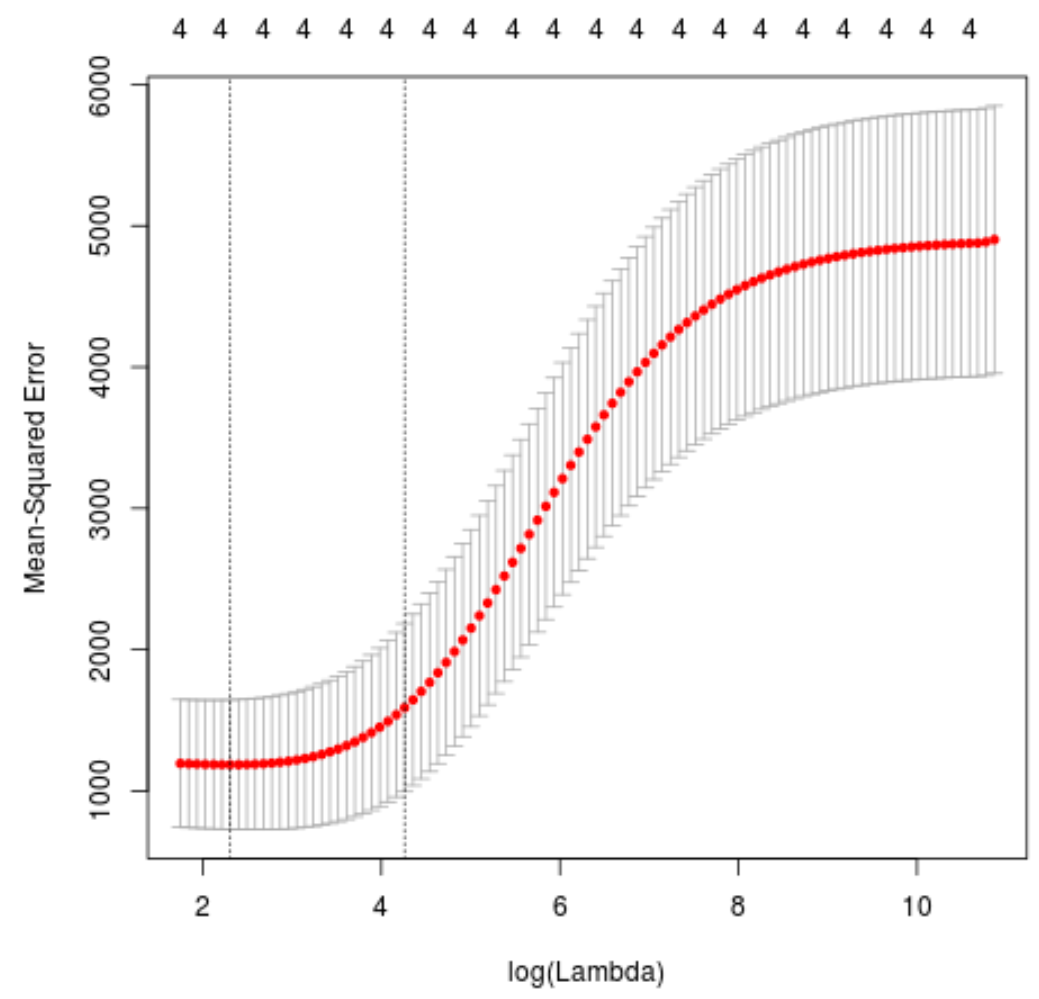
Значение лямбда, которое минимизирует тест MSE, оказывается равным 10,04567 .
Шаг 4. Анализ окончательной модели
Наконец, мы можем проанализировать окончательную модель, созданную по оптимальному значению лямбда.
Мы можем использовать следующий код для получения оценок коэффициентов для этой модели:
#find coefficients of best model
best_model <- glmnet(x, y, alpha = 0 , lambda = best_lambda)
coef(best_model)
5 x 1 sparse Matrix of class "dgCMatrix"
s0
(Intercept) 475.242646
mpg -3.299732
wt 19.431238
drat -1.222429
qsec -17.949721
Мы также можем создать график трассировки, чтобы визуализировать, как изменились оценки коэффициентов из-за увеличения лямбда:
#produce Ridge trace plot
plot(model, xvar = " lambda ")
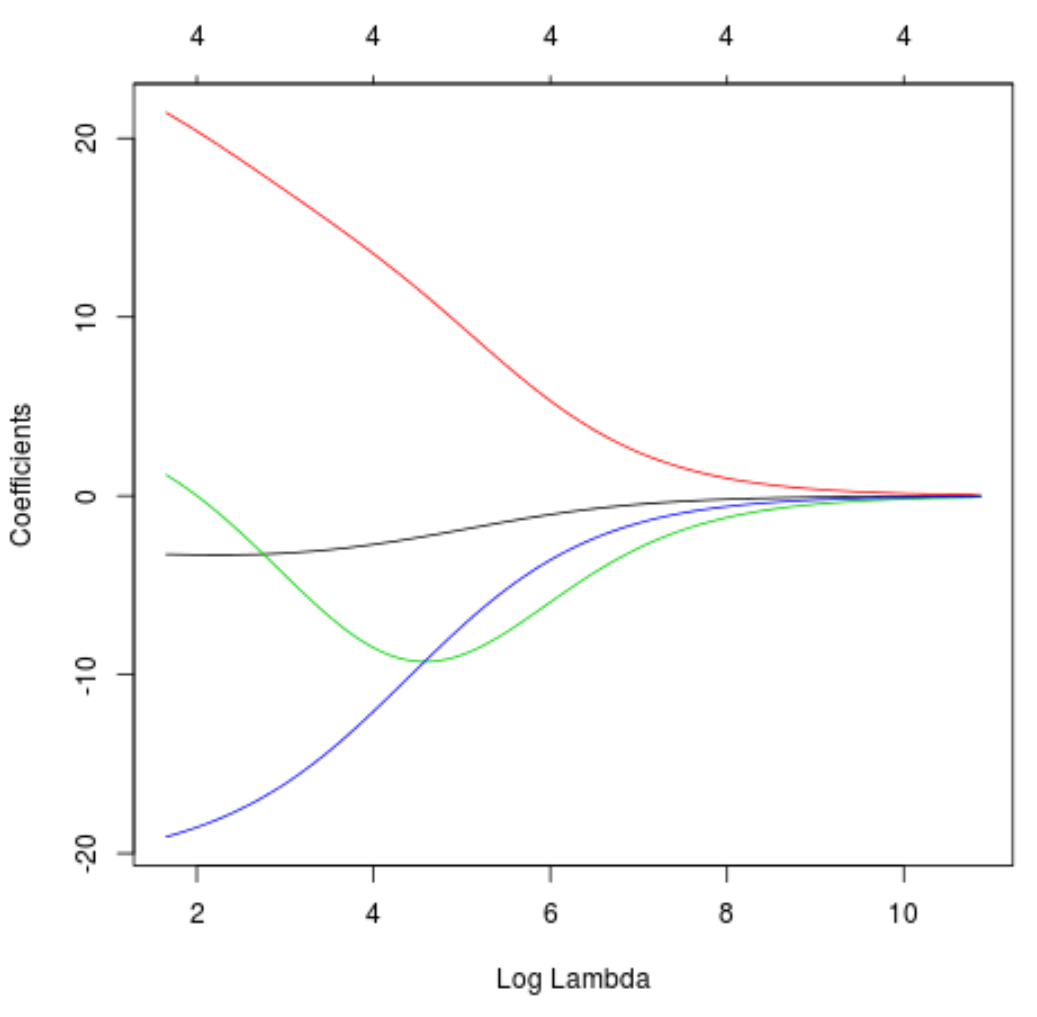
Наконец, мы можем рассчитать R-квадрат модели на обучающих данных:
#use fitted best model to make predictions
y_predicted <- predict (model, s = best_lambda, newx = x)
#find OHS and SSE
sst <- sum ((y - mean (y))^2)
sse <- sum ((y_predicted - y)^2)
#find R-Squared
rsq <- 1 - sse/sst
rsq
[1] 0.7999513
Квадрат R оказывается равным 0,7999513 . То есть лучшая модель смогла объяснить 79,99% вариации значений ответа обучающих данных.
Полный код R, использованный в этом примере, вы можете найти здесь .
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше