Как исключить тренд данных: с примерами
«Удаление тренда» данных временных рядов означает удаление основной тенденции в данных. Основная причина, по которой мы хотим это сделать, — упростить визуализацию основных тенденций в данных, которые являются сезонными или циклическими.
Например, рассмотрим следующие данные временного ряда, которые представляют общий объем продаж компании за 20 последовательных периодов:
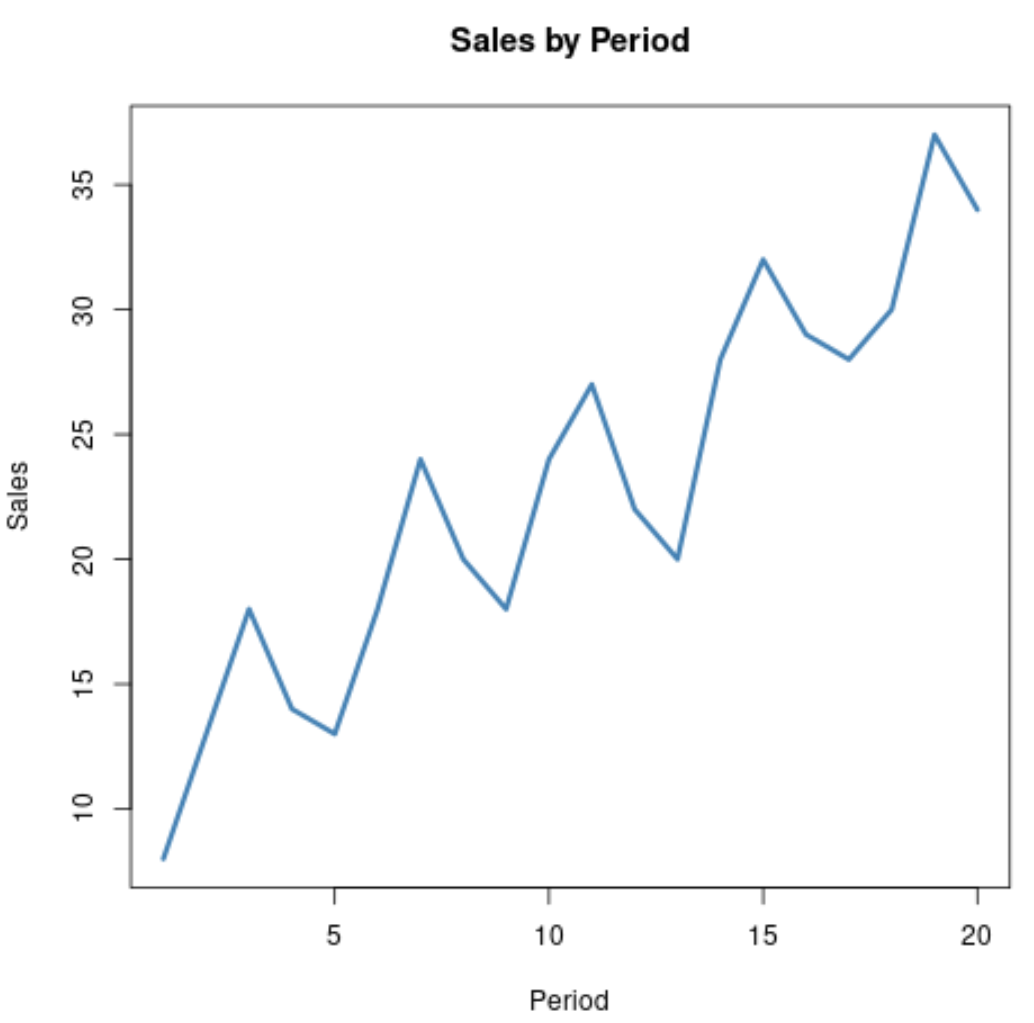
Очевидно, что продажи имеют тенденцию увеличиваться с течением времени, но в данных также наблюдается циклическая или сезонная тенденция, о чем свидетельствуют крошечные «холмы», возникающие с течением времени.
Чтобы лучше понять эту циклическую тенденцию, мы можем дефлировать данные. В этом случае это потребует устранения общей восходящей тенденции с течением времени, чтобы полученные данные представляли только циклическую тенденцию.
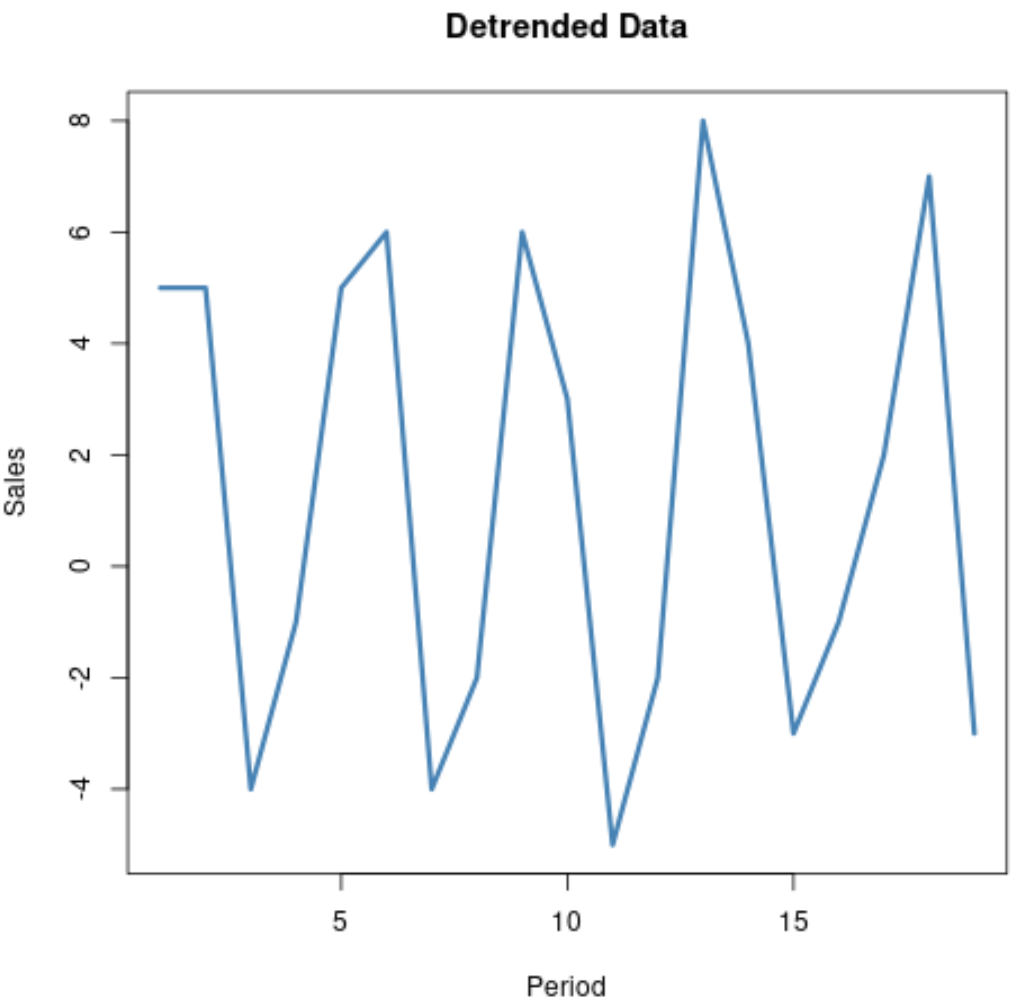
Существует два распространенных метода, используемых для дефлятирования данных временных рядов:
1. Тенденция путем дифференциации
2. Деградация из-за подгонки модели.
В этом руководстве представлено краткое объяснение каждого метода.
Метод 1: Релаксация путем дифференцирования
Один из способов устранения тренда в данных временных рядов — просто создать новый набор данных, в котором каждое наблюдение представляет собой разницу между собой и предыдущим наблюдением.
Например, на следующем изображении показано, как использовать дифференцирование для устранения тренда в ряде данных.
Чтобы получить первое значение данных временного ряда без тренда, мы вычисляем 13 – 8 = 5. Затем, чтобы получить следующее значение, мы вычисляем 18–13 = 5 и так далее.
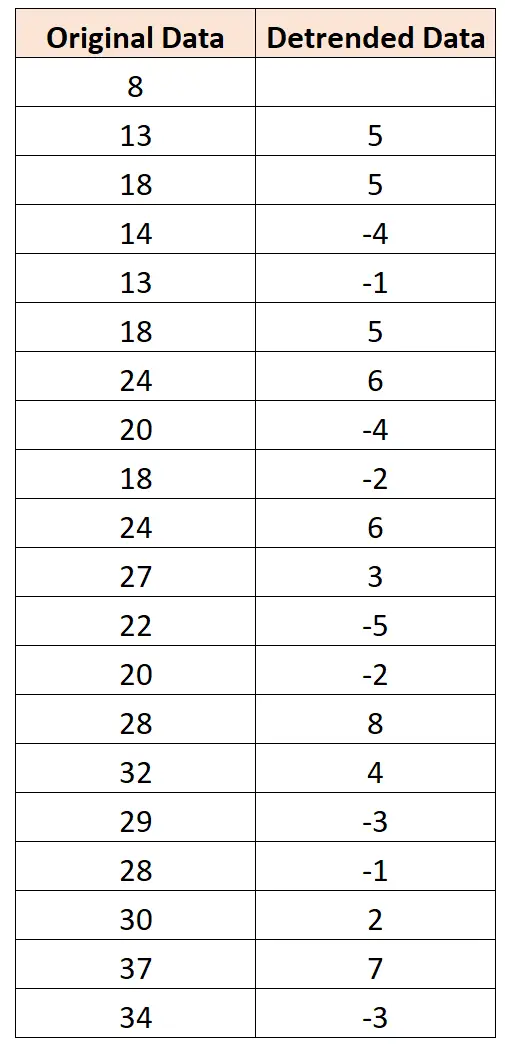
На следующей диаграмме показаны исходные данные временного ряда:
На этом графике показаны данные без тенденции:
Обратите внимание, насколько легче увидеть сезонную тенденцию в данных временных рядов на этой диаграмме, поскольку общая восходящая тенденция удалена.
Метод 2: Ухудшение путем подбора модели
Другой способ исключить тренд из данных временных рядов — подогнать к данным регрессионную модель, а затем вычислить разницу между наблюдаемыми значениями и прогнозируемыми значениями модели.
Например, предположим, что у нас есть один и тот же набор данных:

Если мы подгоним к данным простую модель линейной регрессии , мы сможем получить прогнозируемое значение для каждого наблюдения в наборе данных.
Затем мы можем найти разницу между фактическим значением и прогнозируемым значением для каждого наблюдения. Эти различия представляют собой данные без тренда.
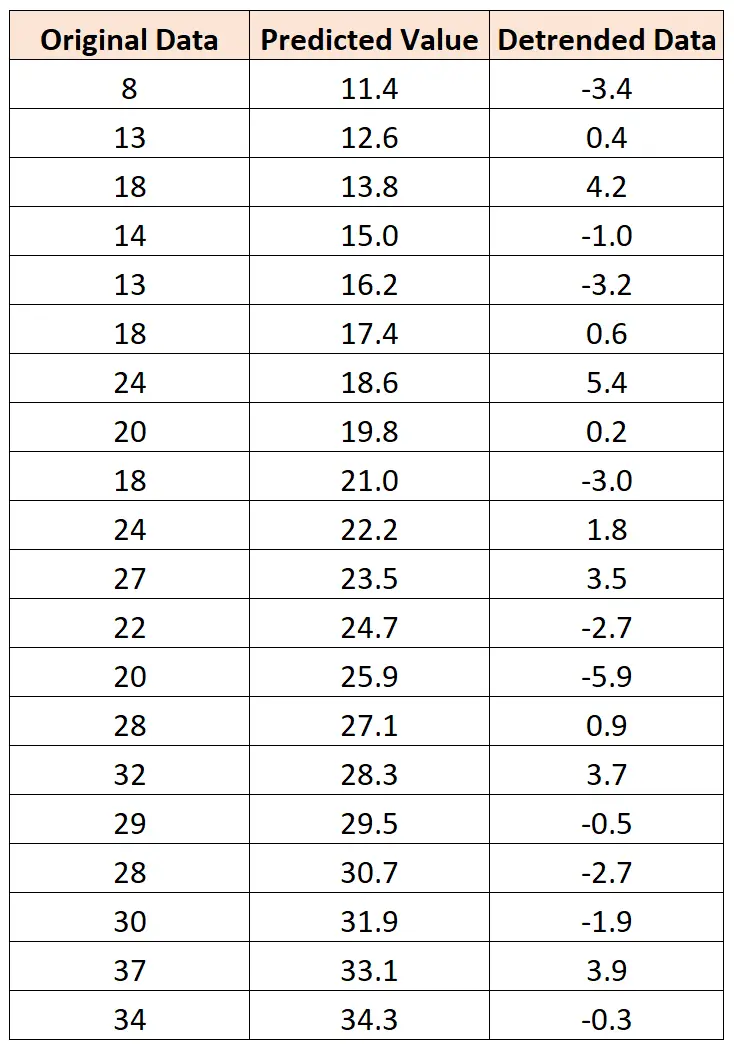
Если мы создадим график данных без тренда, нам будет гораздо проще визуализировать сезонный или циклический тренд данных:
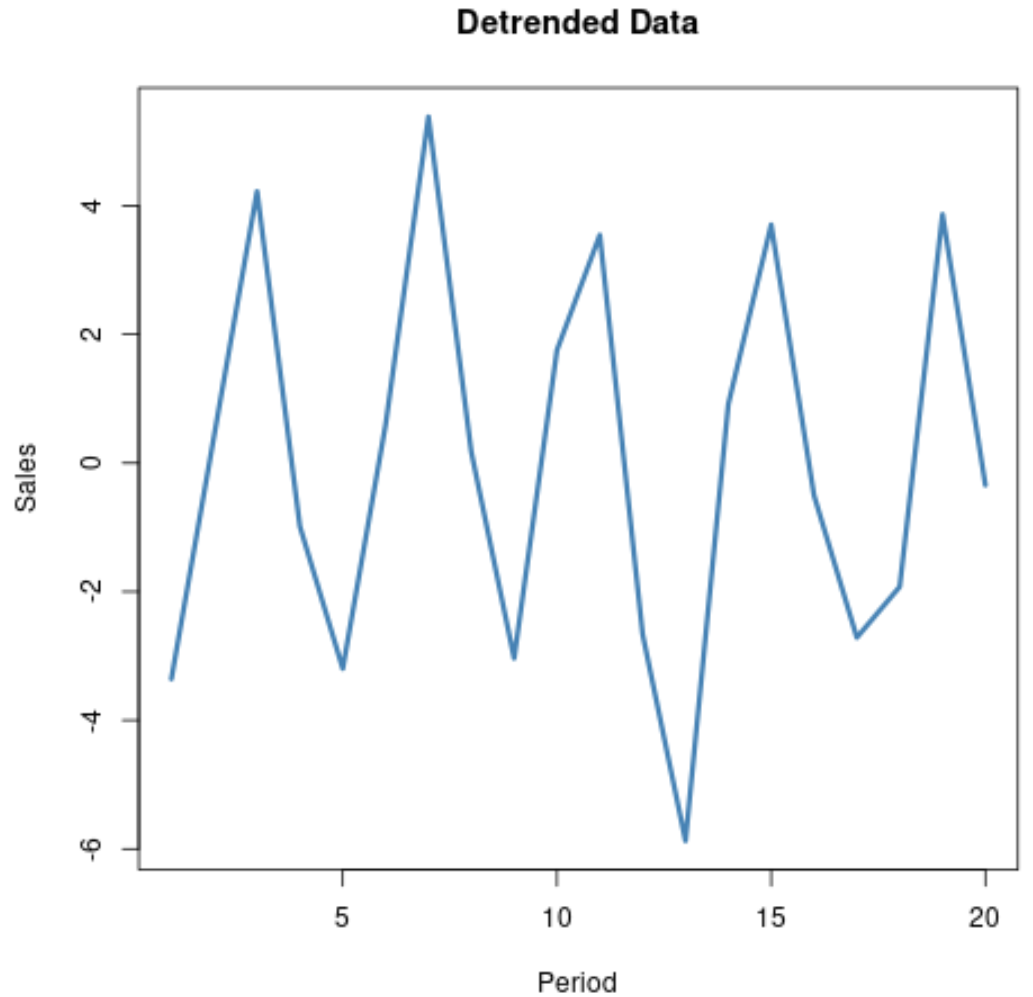
Обратите внимание, что в этом примере мы использовали линейную регрессию, но можно использовать более сложный метод, такой как экспоненциальная регрессия , если в данных наблюдается более экспоненциальный восходящий или нисходящий тренд.
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше