Как рассчитать скользящее среднее в pandas
Скользящее среднее — это просто среднее значение нескольких предыдущих периодов во временном ряду.
Чтобы вычислить скользящее среднее одного или нескольких столбцов в DataFrame pandas, мы можем использовать следующий синтаксис:
df[' column_name ']. rolling ( rolling_window ). mean ()
В этом руководстве представлено несколько примеров практического использования этой функции.
Пример: расчет скользящего среднего в пандах
Предположим, у нас есть следующий DataFrame pandas:
import numpy as np import pandas as pd #make this example reproducible n.p. random . seeds (0) #create dataset period = np. arange (1, 101, 1) leads = np. random . uniform (1, 20, 100) sales = 60 + 2*period + np. random . normal (loc=0, scale=.5*period, size=100) df = pd. DataFrame ({' period ': period, ' leads ': leads, ' sales ': sales}) #view first 10 rows df. head (10) period leads sales 0 1 11.427457 61.417425 1 2 14.588598 64.900826 2 3 12.452504 66.698494 3 4 11.352780 64.927513 4 5 9.049441 73.720630 5 6 13.271988 77.687668 6 7 9.314157 78.125728 7 8 17.943687 75.280301 8 9 19.309592 73.181613 9 10 8.285389 85.272259
Мы можем использовать следующий синтаксис, чтобы создать новый столбец, содержащий скользящее среднее «продаж» за предыдущие 5 периодов:
#find rolling mean of previous 5 sales periods df[' rolling_sales_5 '] = df[' sales ']. rolling (5). mean () #view first 10 rows df. head (10) period leads sales rolling_sales_5 0 1 11.427457 61.417425 NaN 1 2 14.588598 64.900826 NaN 2 3 12.452504 66.698494 NaN 3 4 11.352780 64.927513 NaN 4 5 9.049441 73.720630 66.332978 5 6 13.271988 77.687668 69.587026 6 7 9.314157 78.125728 72.232007 7 8 17.943687 75.280301 73.948368 8 9 19.309592 73.181613 75.599188 9 10 8.285389 85.272259 77.909514
Мы можем вручную проверить, что скользящее среднее значение продаж, отображаемое для периода 5, является средним значением предыдущих 5 периодов:
Скользящее среднее в периоде 5: (61,417+64,900+66,698+64,927+73,720)/5 = 66,33
Мы можем использовать аналогичный синтаксис для вычисления скользящего среднего по нескольким столбцам:
#find rolling mean of previous 5 leads periods df[' rolling_leads_5 '] = df[' leads ']. rolling (5). mean () #find rolling mean of previous 5 leads periods df[' rolling_sales_5 '] = df[' sales ']. rolling (5). mean () #view first 10 rows df. head (10) period leads sales rolling_sales_5 rolling_leads_5 0 1 11.427457 61.417425 NaN NaN 1 2 14.588598 64.900826 NaN NaN 2 3 12.452504 66.698494 NaN NaN 3 4 11.352780 64.927513 NaN NaN 4 5 9.049441 73.720630 66.332978 11.774156 5 6 13.271988 77.687668 69.587026 12.143062 6 7 9.314157 78.125728 72.232007 11.088174 7 8 17.943687 75.280301 73.948368 12.186411 8 9 19.309592 73.181613 75.599188 13.777773 9 10 8.285389 85.272259 77.909514 13.624963
Мы также можем создать быстрый линейный график, используя Matplotlib, для визуализации валовых продаж в сравнении со скользящим средним значением продаж:
import matplotlib. pyplot as plt
plt. plot (df[' rolling_sales_5 '], label=' Rolling Mean ')
plt. plot (df[' sales '], label=' Raw Data ')
plt. legend ()
plt. ylabel (' Sales ')
plt. xlabel (' Period ')
plt. show ()
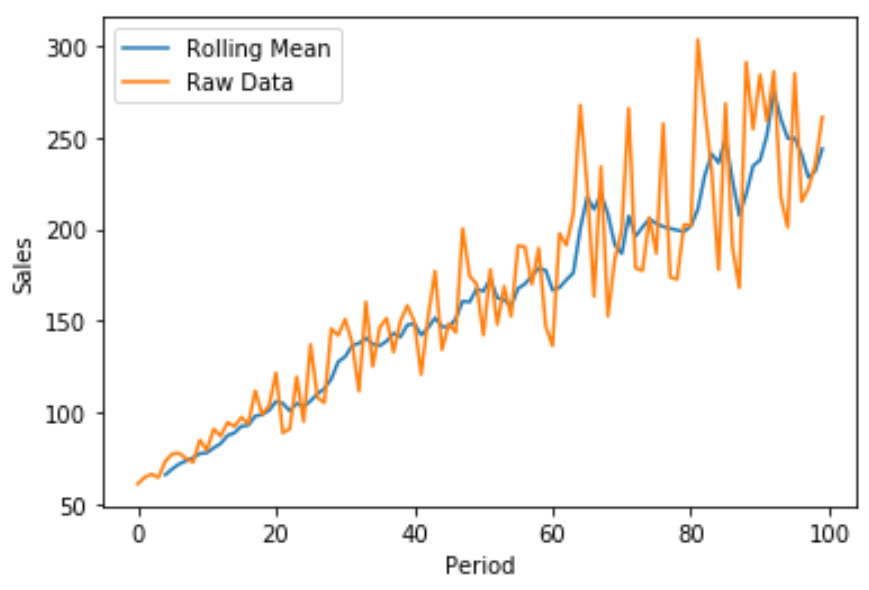
Синяя линия показывает скользящее среднее продаж за 5 периодов, а оранжевая линия показывает необработанные данные о продажах.
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные задачи в pandas:
Как рассчитать скользящую корреляцию в пандах
Как рассчитать среднее значение столбцов в Pandas
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше