Когда использовать регрессию гребня и лассо
В обычной множественной линейной регрессии мы используем набор переменных-предикторов p и переменную отклика, чтобы соответствовать модели вида:
Y = β 0 + β 1 X 1 + β 2 X 2 + … + β p
Значения β 0 , β 1 , B 2 , …, β p выбираются методом наименьших квадратов, минимизирующим сумму квадратов остатков (RSS):
RSS = Σ(y i – ŷ i ) 2
Золото:
- Σ : Символ, означающий «сумма».
- y i : фактическое значение ответа для i-го наблюдения
- ŷ i : Прогнозируемое значение ответа для i- го наблюдения.
Проблема мультиколлинеарности в регрессии
Проблема, которая часто возникает на практике при использовании множественной линейной регрессии, — это мультиколлинеарность — когда две или более переменных-предикторов сильно коррелируют друг с другом, так что они не предоставляют уникальную или независимую информацию в модели регрессии.
Это может сделать оценки коэффициентов модели ненадежными и привести к высокой дисперсии. То есть, когда модель применяется к новому набору данных, которого она никогда раньше не видела, она, скорее всего, будет работать плохо.
Как избежать мультиколлинеарности: регрессия Риджа и Лассо
Два метода, которые мы можем использовать, чтобы обойти эту проблему мультиколлинеарности, — это гребневая регрессия и лассо-регрессия .
Ридж-регрессия стремится минимизировать следующее:
- RSS + λΣβ j 2
Лассо-регрессия стремится минимизировать следующее:
- RSS + λΣ|β j |
В обоих уравнениях второй член называется штрафом за снятие средств .
Когда λ = 0, этот штрафной член не имеет никакого эффекта, и регрессия гребня и регрессия лассо дают те же оценки коэффициентов, что и метод наименьших квадратов.
Однако по мере того, как λ приближается к бесконечности, штраф за усадку становится более влиятельным, и прогностические переменные, которые не могут быть импортированы в модель, уменьшаются до нуля.
При использовании регрессии Лассо некоторые коэффициенты могут стать полностью нулевыми , когда λ станет достаточно большим.
Преимущества и недостатки регрессии гребня и лассо
Преимущество регрессии Риджа и Лассо перед регрессией наименьших квадратов заключается в компромиссе между смещением и дисперсией .
Напомним, что среднеквадратическая ошибка (MSE) — это показатель, который мы можем использовать для измерения точности данной модели, и он рассчитывается следующим образом:
MSE = Var( f̂( x 0 )) + [Смещение ( f̂( x 0 ))] 2 + Var(ε)
MSE = дисперсия + смещение 2 + неустранимая ошибка
Основная идея Ридж-регрессии и Лассо-регрессии состоит в том, чтобы ввести небольшое смещение, чтобы можно было значительно уменьшить дисперсию, что приведет к более низкому общему MSE.
Чтобы проиллюстрировать это, рассмотрим следующий график:

Обратите внимание, что по мере увеличения λ дисперсия значительно уменьшается при очень небольшом увеличении смещения. Однако за определенной точкой дисперсия убывает медленнее и уменьшение коэффициентов приводит к их существенному занижению, что приводит к резкому увеличению систематической ошибки.
Из графика видно, что MSE теста является самым низким, когда мы выбираем значение λ, которое обеспечивает оптимальный компромисс между смещением и дисперсией.
Когда λ = 0, штрафной член в лассо-регрессии не имеет никакого эффекта и, следовательно, дает те же оценки коэффициентов, что и метод наименьших квадратов. Однако, увеличив λ до определенной точки, мы можем уменьшить общую MSE теста.
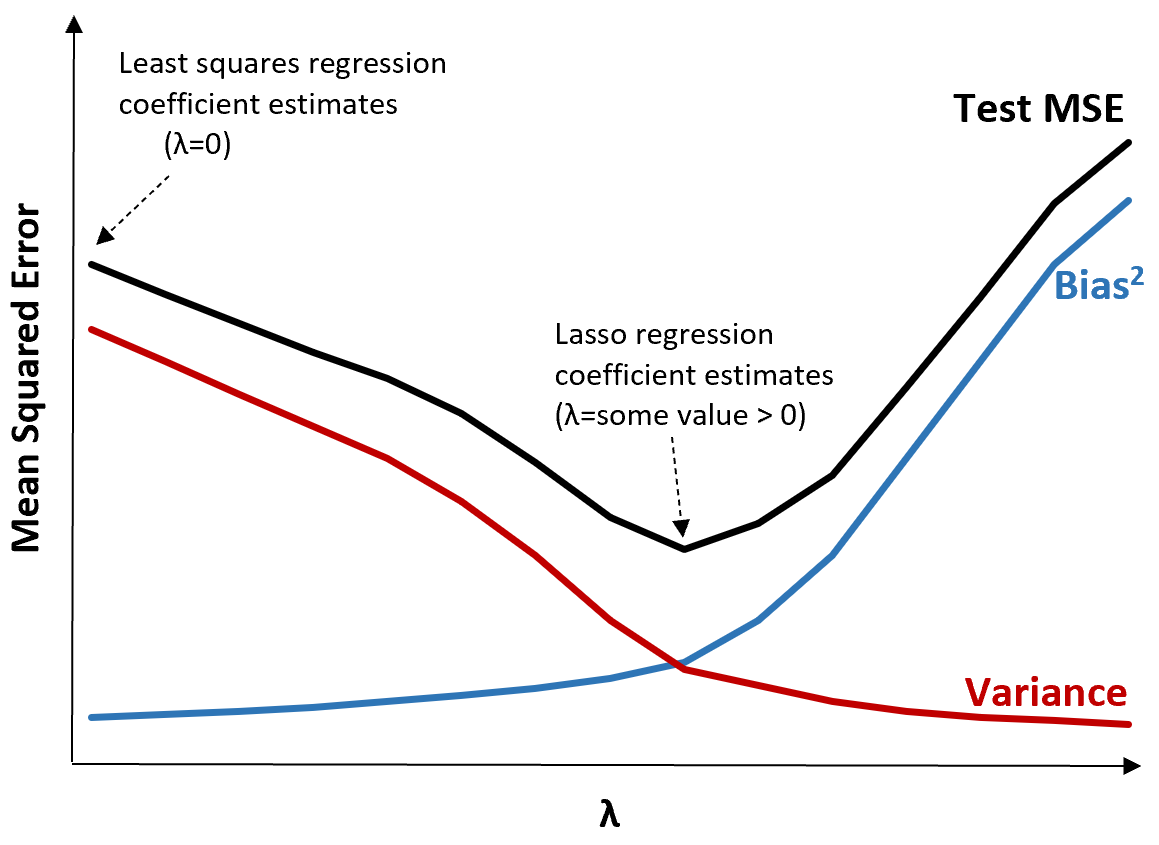
Это означает, что аппроксимация модели с помощью регрессии гребня и лассо потенциально может привести к меньшим ошибкам теста, чем аппроксимация модели с помощью регрессии наименьших квадратов.
Недостатком регрессии Риджа и Лассо является то, что становится трудно интерпретировать коэффициенты в окончательной модели, поскольку они сжимаются к нулю.
Таким образом, регрессию Риджа и Лассо следует использовать, когда вы хотите оптимизировать способность прогнозирования, а не делать выводы.
Ридж против. Лассо-регрессия: когда использовать каждый
L-ассо-регрессия и гребневая регрессия известны как методы регуляризации , поскольку оба они пытаются минимизировать остаточную сумму квадратов (RSS), а также определенный штрафной член.
Другими словами, они ограничивают или регуляризируют оценки коэффициентов модели.
Естественно, возникает вопрос: что лучше — гребневая или лассо-регрессия?
В тех случаях, когда значимыми являются лишь небольшое количество переменных-предикторов, лассо-регрессия имеет тенденцию работать лучше, поскольку она способна полностью свести незначимые переменные к нулю и удалить их из модели.
Однако, когда многие переменные-предикторы являются значимыми в модели и их коэффициенты примерно равны, гребневая регрессия имеет тенденцию работать лучше, поскольку она сохраняет все предикторы в модели.
Чтобы определить, какая модель лучше всего подходит для прогнозирования, мы обычно выполняем k-кратную перекрестную проверку и выбираем модель, которая дает наименьшую среднеквадратическую ошибку теста.
Дополнительные ресурсы
В следующих руководствах представлено введение в ридж-регрессию и лассо-регрессию:
В следующих руководствах объясняется, как выполнить оба типа регрессии в R и Python:
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше