Краткое введение в контролируемое и неконтролируемое обучение
Область машинного обучения содержит огромный набор алгоритмов, которые можно использовать для понимания данных. Эти алгоритмы можно отнести к одной из следующих двух категорий:
1. Алгоритмы контролируемого обучения: предполагают построение модели для оценки или прогнозирования результата на основе одного или нескольких входных данных.
2. Алгоритмы обучения без учителя: предполагают поиск структуры и взаимосвязей на входных данных. Выхода «надзора» нет.
В этом руководстве объясняется разница между этими двумя типами алгоритмов, а также приводится несколько примеров каждого из них.
Алгоритмы контролируемого обучения
Алгоритм обучения с учителем можно использовать , когда у нас есть одна или несколько объясняющих переменных ( X1, переменная ответа:
Y = f (X) + ε
где f представляет собой систематическую информацию, которую X предоставляет об Y, и где ε — это случайная ошибка, независимая от X, со средним значением, равным нулю.
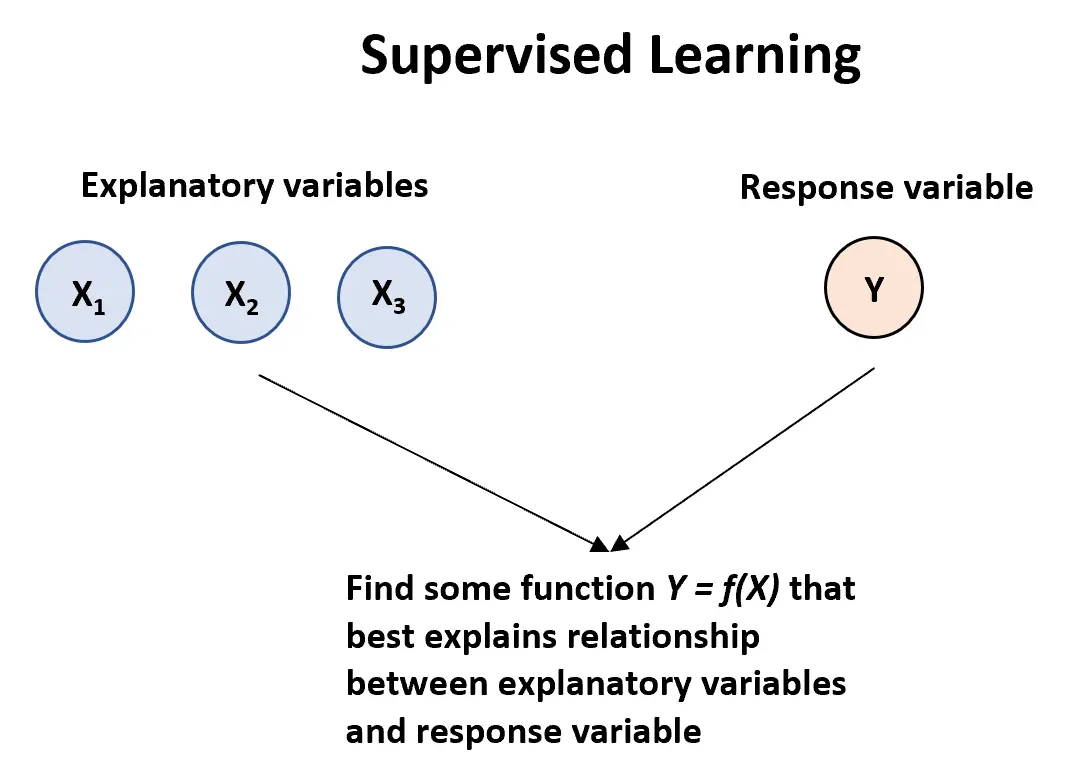
Существует два основных типа алгоритмов контролируемого обучения:
1. Регрессия: выходная переменная является непрерывной (например, вес, рост, время и т. д.).
2. Классификация: выходная переменная является категориальной (например, мужчина или женщина, успех или неудача, доброкачественный или злокачественный характер и т. д.).
Есть две основные причины, по которым мы используем алгоритмы обучения с учителем:
1. Прогнозирование. Мы часто используем набор объясняющих переменных, чтобы предсказать значение переменной ответа (например, используя площадь в квадратных футах и количество спален для прогнозирования цены дома ).
2. Вывод: нам может быть интересно понять, как на переменную ответа влияет изменение значения объясняющих переменных (например, насколько в среднем увеличивается цена недвижимости, когда количество комнат увеличивается на одну?)
В зависимости от того, является ли наша цель выводом или предсказанием (или сочетанием того и другого), мы можем использовать разные методы для оценки функции f . Например, линейные модели предлагают более легкую интерпретацию, но нелинейные модели, которые сложно интерпретировать, могут давать более точные прогнозы.
Вот список наиболее часто используемых алгоритмов контролируемого обучения:
- Линейная регрессия
- Логистическая регрессия
- Линейный дискриминантный анализ
- Квадратичный дискриминантный анализ
- Деревья решений
- Наивный Байес
- Машины опорных векторов
- Нейронные сети
Алгоритмы обучения без учителя
Алгоритм обучения без учителя можно использовать, когда у нас есть список переменных ( X 1 , data.
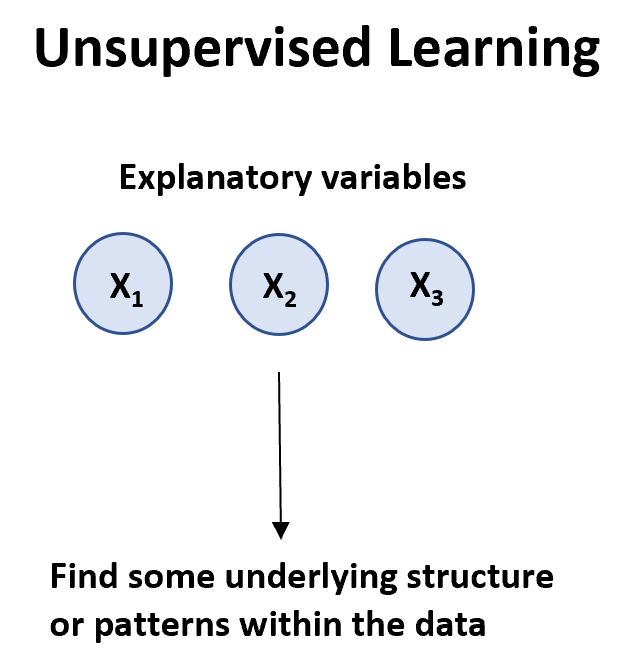
Существует два основных типа алгоритмов обучения без учителя:
1. Кластеризация. Используя эти типы алгоритмов, мы пытаемся найти в наборе данных «кластеры» наблюдений , похожих друг на друга. Это часто используется в розничной торговле, когда компания хочет выявить группы клиентов со схожими покупательскими привычками, чтобы они могли разработать конкретные маркетинговые стратегии, ориентированные на определенные группы клиентов.
2. Ассоциация. Используя эти типы алгоритмов, мы пытаемся найти «правила», которые можно использовать для установления ассоциаций. Например, розничные продавцы могут разработать алгоритм ассоциации, который указывает, что «если покупатель покупает продукт X, он, скорее всего, также купит продукт Y».
Вот список наиболее часто используемых алгоритмов обучения без учителя:
- Анализ главных компонентов
- K-средства кластеризации
- Группировка К-медоидов
- Иерархическая классификация
- Априорный алгоритм
Резюме: контролируемое или неконтролируемое обучение
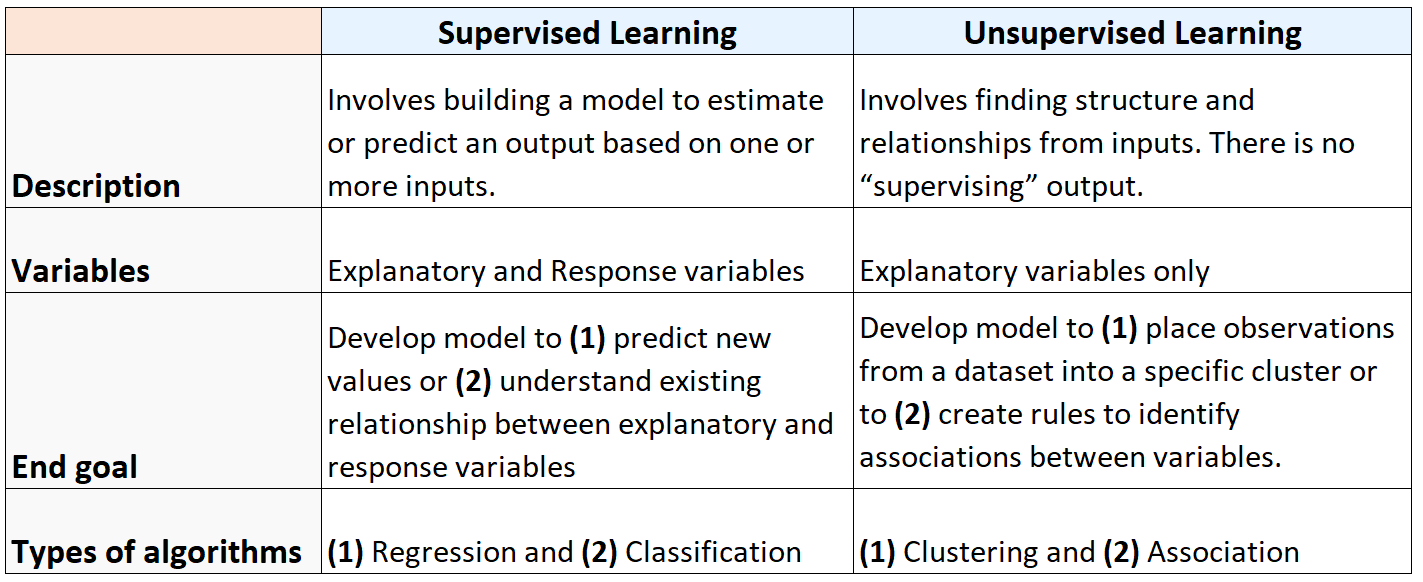
В следующей таблице суммированы различия между контролируемыми и неконтролируемыми алгоритмами обучения:
На следующей диаграмме обобщены типы алгоритмов машинного обучения:

Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше