Как создать и интерпретировать кривую roc в spss
Логистическая регрессия — это статистический метод, который мы используем для подбора модели регрессии, когда переменная ответа является двоичной. Чтобы оценить, насколько хорошо модель логистической регрессии соответствует набору данных, мы можем взглянуть на следующие два показателя:
- Чувствительность: вероятность того, что модель предсказывает положительный результат наблюдения, когда результат на самом деле положительный.
- Специфичность: вероятность того, что модель предсказывает отрицательный результат наблюдения, хотя на самом деле результат отрицательный.
Простой способ визуализировать эти два показателя — создать кривую ROC , которая представляет собой график, отображающий чувствительность и специфичность модели логистической регрессии.
В этом руководстве объясняется, как создать и интерпретировать кривую ROC в SPSS.
Пример: кривая ROC в SPSS
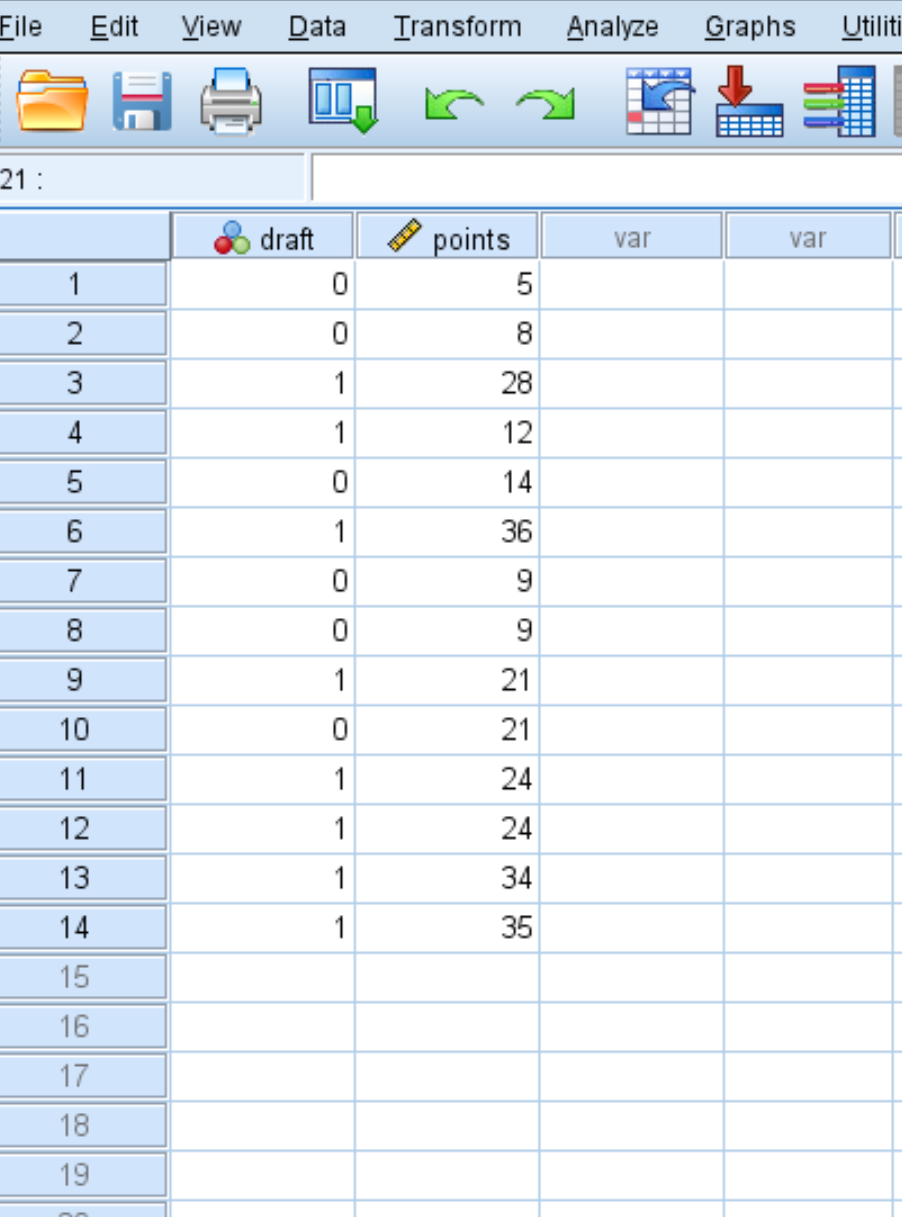
Допустим, у нас есть следующий набор данных, который показывает, был ли баскетболист призван в НБА (0 = нет, 1 = да), а также его среднее количество очков за игру в колледже:
Чтобы создать кривую ROC для этого набора данных, перейдите на вкладку «Анализ» , затем «Классифицировать» , затем «Кривая ROC» :
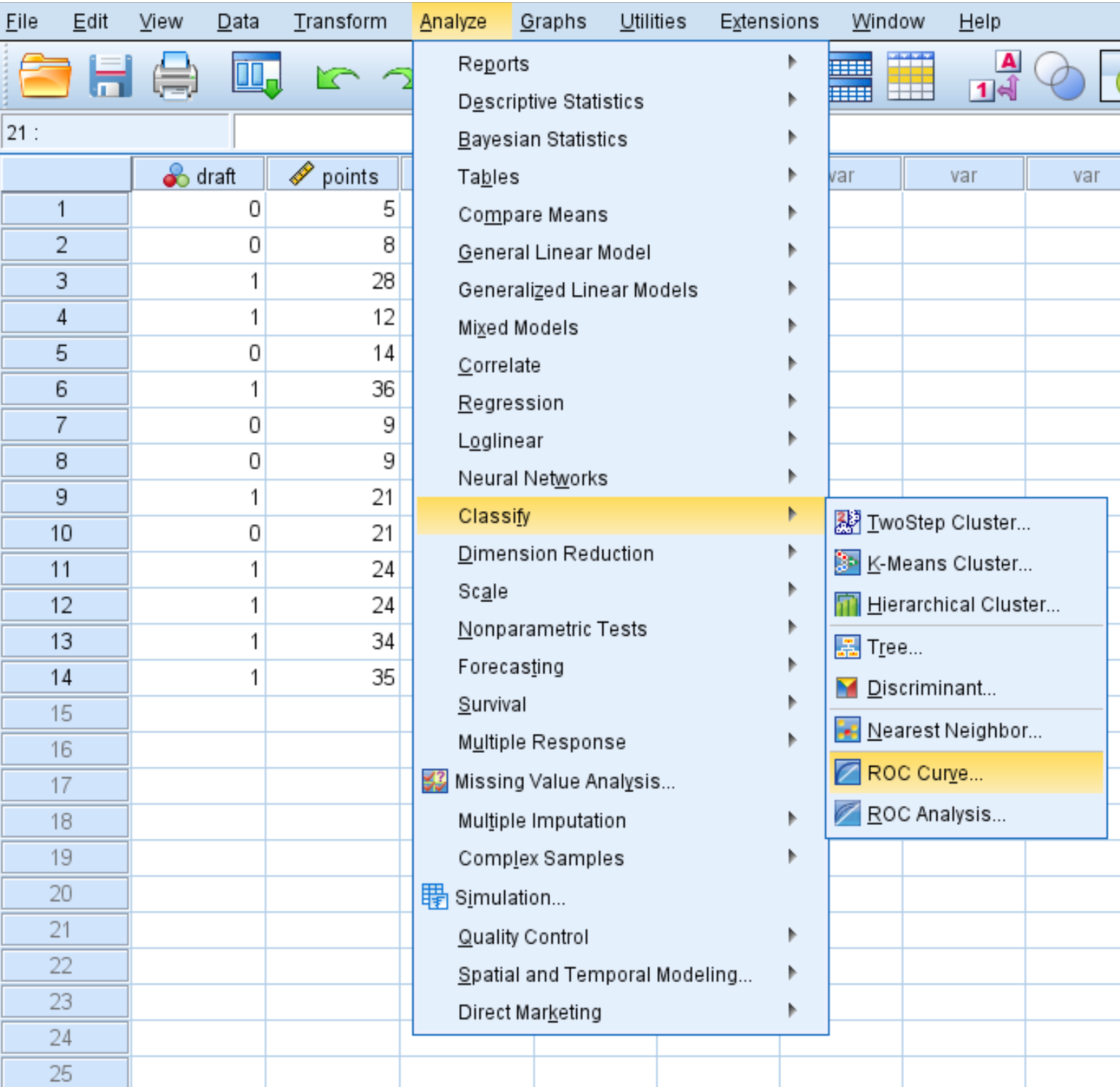
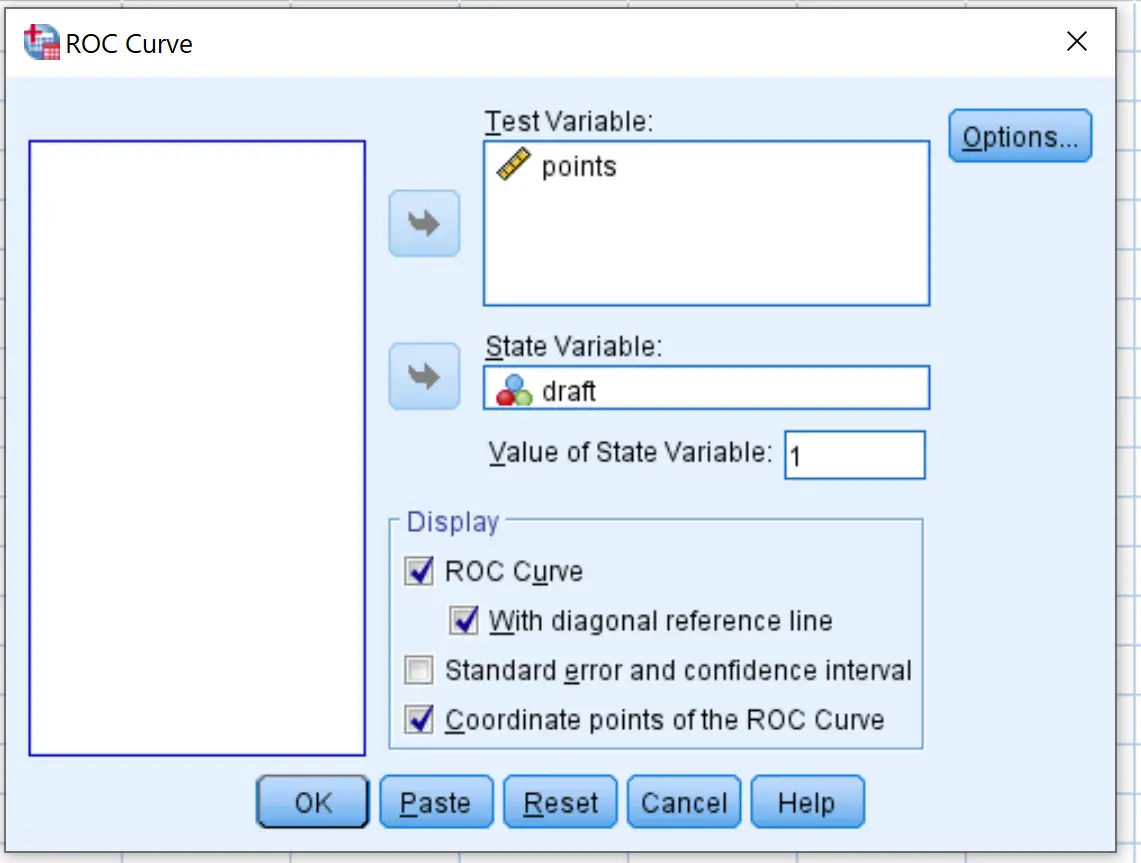
В появившемся новом окне перетащите переменную черновика в область с надписью «Переменная состояния». Установите значение переменной состояния равным 1 . (Это значение указывает на то, что игрок был выбран). Перетащите точки переменных в область с надписью «Тестовая переменная».
Установите флажки рядом с пунктами «С диагональной опорной линией» и «Координаты точки кривой ROC ». Затем нажмите ОК .
Вот как интерпретировать результат:
Краткое описание обработки файлов:
В этой таблице показано общее количество положительных и отрицательных случаев в наборе данных. В этом примере 8 игроков были выбраны (положительный результат) и 6 игроков не были выбраны (отрицательный результат):

ROC-кривая:
Кривая рабочей характеристики приемника (ROC) представляет собой график зависимости значений чувствительности от специфичности 1 при изменении порогового значения от 0 до 1:
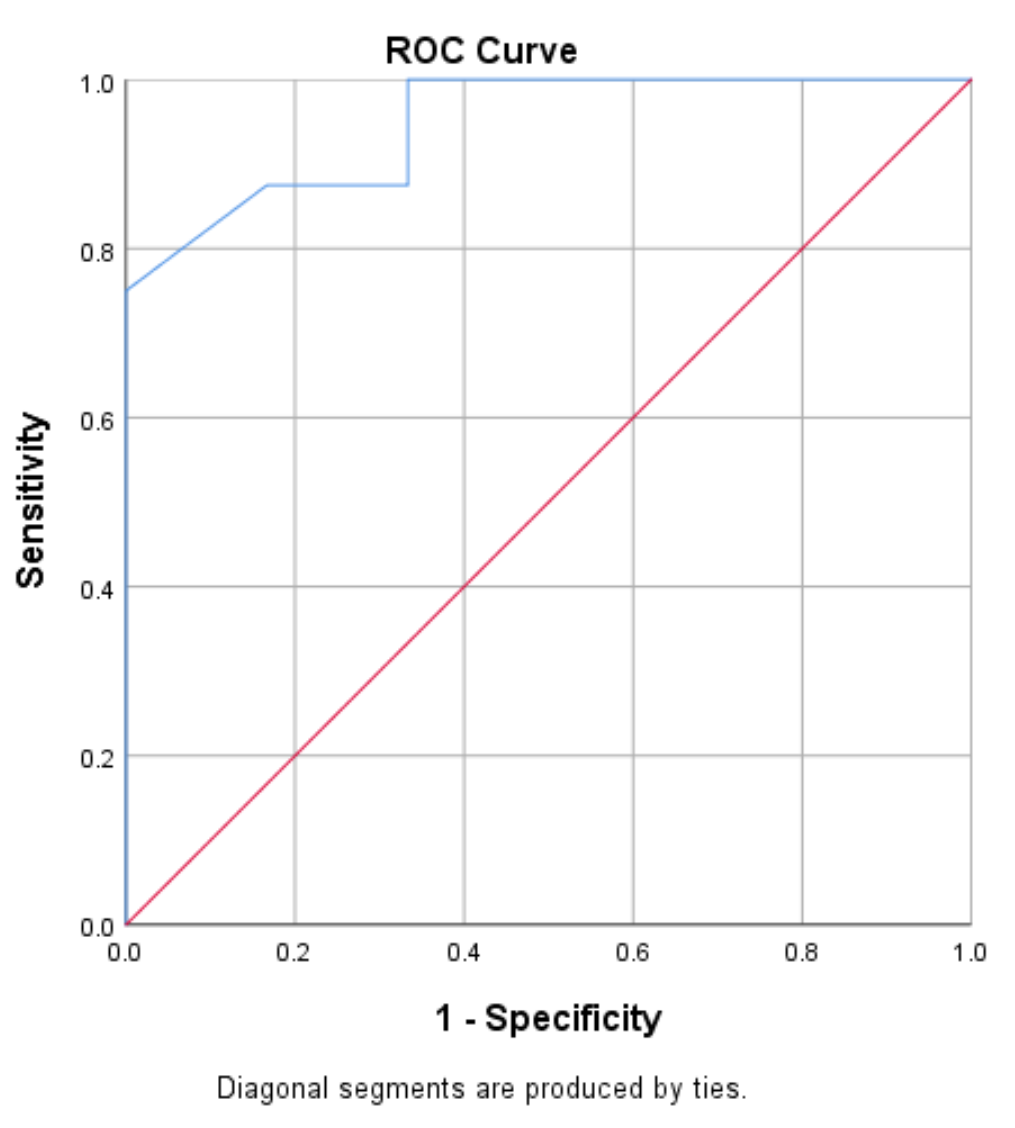
Модель с высокой чувствительностью и специфичностью будет иметь кривую ROC, соответствующую левому верхнему углу графика. Модель с низкой чувствительностью и низкой специфичностью будет иметь кривую, близкую к диагонали 45 градусов.
Мы видим, что кривая ROC (синяя линия) в этом примере охватывает верхний левый угол графика, что указывает на то, что модель хорошо справляется с прогнозированием того, будут ли игроки выбраны на драфте или нет, на основе их среднего количества очков за игру. . .
Площадь под кривой:
Площадь под кривой дает нам представление о способности модели различать положительные и отрицательные результаты. AUC может варьироваться от 0 до 1. Чем выше AUC, тем лучше модель правильно классифицирует результаты.
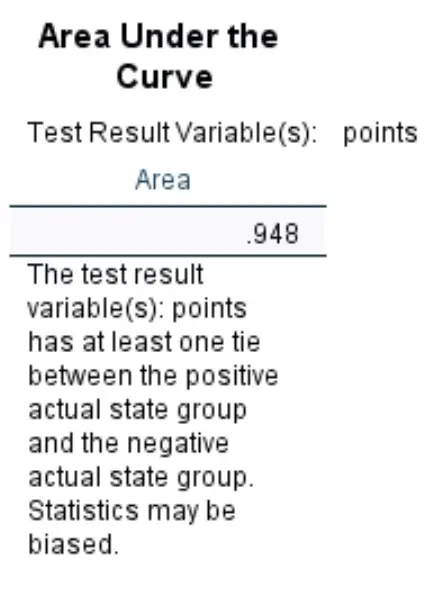
Мы видим, что AUC для этой конкретной модели логистической регрессии составляет 0,948 , что чрезвычайно высоко. Это указывает на то, что модель хорошо прогнозирует, будет ли игрок выбран на драфте или нет.
Координаты кривой:
В последней таблице показаны чувствительность и специфичность 1 кривой ROC для различных порогов.
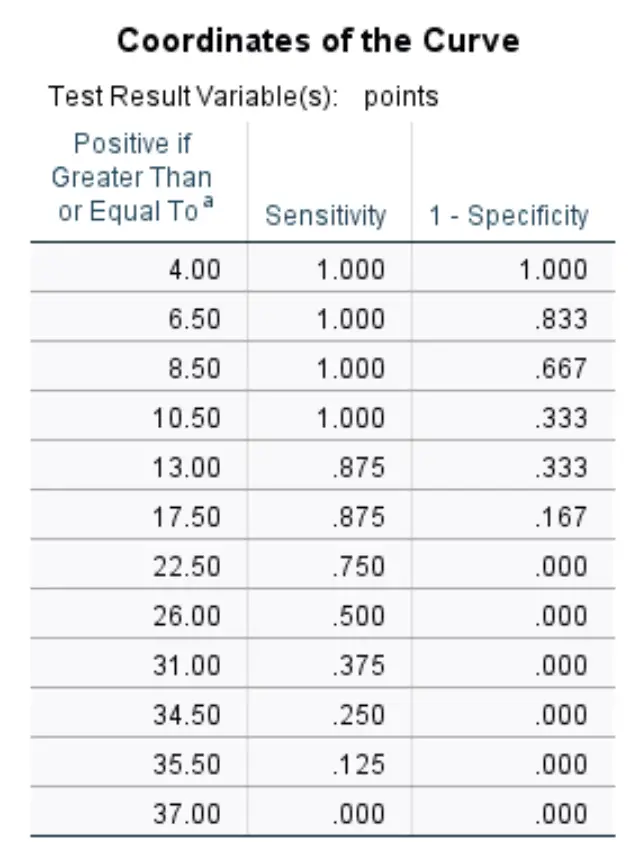
Например:
Если мы позволим порогу быть равным 8,50 , это означает, что мы ожидаем, что любой игрок, набравший менее 8,50 очков за игру, не будет выбран на драфте, и что любой игрок, набравший более 8,50 очков за игру, будет выбран.
Если использовать это в качестве порогового значения, наша чувствительность составит 100 % (поскольку каждый игрок, набравший менее 8,50 очков за игру, действительно не был выбран на драфте), а наша специфичность 1 составит 66,7 % (поскольку 8 игроков из 12, набравших более 8,50 очков за игру, не были выбраны на драфте). за игру были выбраны).
Таблица выше позволяет нам увидеть чувствительность и специфичность 1 для каждого потенциального порога.
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше