Линейный дискриминантный анализ в python (шаг за шагом)
Линейный дискриминантный анализ — это метод, который вы можете использовать, когда у вас есть набор переменных-предикторов и вы хотите классифицировать переменную ответа на два или более классов.
В этом руководстве представлен пошаговый пример выполнения линейного дискриминантного анализа в Python.
Шаг 1. Загрузите необходимые библиотеки
Сначала мы загрузим функции и библиотеки, необходимые для этого примера:
from sklearn. model_selection import train_test_split
from sklearn. model_selection import RepeatedStratifiedKFold
from sklearn. model_selection import cross_val_score
from sklearn. discriminant_analysis import LinearDiscriminantAnalysis
from sklearn import datasets
import matplotlib. pyplot as plt
import pandas as pd
import numpy as np
Шаг 2. Загрузите данные
В этом примере мы будем использовать набор данных радужной оболочки глаза из библиотеки sklearn. Следующий код показывает, как загрузить этот набор данных и преобразовать его в DataFrame pandas для простоты использования:
#load iris dataset iris = datasets. load_iris () #convert dataset to pandas DataFrame df = pd.DataFrame(data = np.c_[iris[' data '], iris[' target ']], columns = iris[' feature_names '] + [' target ']) df[' species '] = pd. Categorical . from_codes (iris.target, iris.target_names) df.columns = [' s_length ', ' s_width ', ' p_length ', ' p_width ', ' target ', ' species '] #view first six rows of DataFrame df. head () s_length s_width p_length p_width target species 0 5.1 3.5 1.4 0.2 0.0 setosa 1 4.9 3.0 1.4 0.2 0.0 setosa 2 4.7 3.2 1.3 0.2 0.0 setosa 3 4.6 3.1 1.5 0.2 0.0 setosa 4 5.0 3.6 1.4 0.2 0.0 setosa #find how many total observations are in dataset len( df.index ) 150
Мы видим, что набор данных содержит всего 150 наблюдений.
В этом примере мы построим модель линейного дискриминантного анализа, чтобы классифицировать, к какому виду принадлежит данный цветок.
В модели мы будем использовать следующие переменные-предикторы:
- Длина чашелистика
- Ширина чашелистика
- Длина лепестка
- Ширина лепестка
И мы будем использовать их для прогнозирования переменной ответа вида , которая поддерживает следующие три потенциальных класса:
- сетоза
- лишай
- Вирджиния
Шаг 3. Настройте модель LDA
Далее мы подгоним модель LDA к нашим данным с помощью функции LinearDiscrimiantAnalsys sklearn:
#define predictor and response variables X = df[[' s_length ',' s_width ',' p_length ',' p_width ']] y = df[' species '] #Fit the LDA model model = LinearDiscriminantAnalysis() model. fit (x,y)
Шаг 4. Используйте модель для прогнозирования
После того, как мы подогнали модель, используя наши данные, мы можем оценить производительность модели, используя повторную стратифицированную k-кратную перекрестную проверку.
В этом примере мы будем использовать 10 складок и 3 повторения:
#Define method to evaluate model
cv = RepeatedStratifiedKFold(n_splits= 10 , n_repeats= 3 , random_state= 1 )
#evaluate model
scores = cross_val_score(model, X, y, scoring=' accuracy ', cv=cv, n_jobs=-1)
print( np.mean (scores))
0.9777777777777779
Мы видим, что модель достигла средней точности 97,78% .
Мы также можем использовать модель, чтобы предсказать, к какому классу принадлежит новый цветок, на основе входных значений:
#define new observation new = [5, 3, 1, .4] #predict which class the new observation belongs to model. predict ([new]) array(['setosa'], dtype='<U10')
Мы видим, что модель предсказывает, что это новое наблюдение принадлежит виду, называемому setosa .
Шаг 5: Визуализируйте результаты
Наконец, мы можем создать график LDA, чтобы визуализировать линейные дискриминанты модели и понять, насколько хорошо она разделяет три разных вида в нашем наборе данных:
#define data to plot X = iris.data y = iris.target model = LinearDiscriminantAnalysis() data_plot = model. fit (x,y). transform (X) target_names = iris. target_names #create LDA plot plt. figure () colors = [' red ', ' green ', ' blue '] lw = 2 for color, i, target_name in zip(colors, [0, 1, 2], target_names): plt. scatter (data_plot[y == i, 0], data_plot[y == i, 1], alpha=.8, color=color, label=target_name) #add legend to plot plt. legend (loc=' best ', shadow= False , scatterpoints=1) #display LDA plot plt. show ()
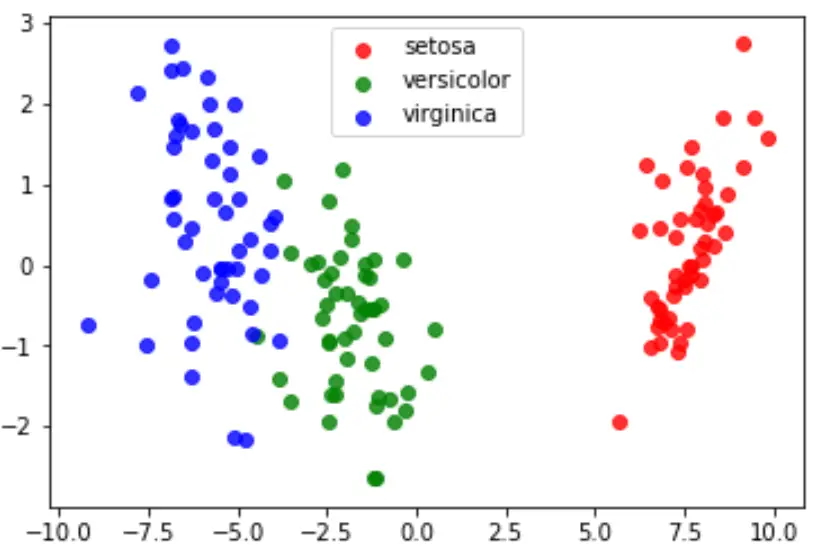
Полный код Python, используемый в этом уроке, вы можете найти здесь .
Об авторе
бенджамин андерсон
Здравствуйте, я Бенджамин, профессор статистики на пенсии, ставший преданным преподавателем Statorials. Имея обширный опыт и знания в области статистики, я хочу поделиться своими знаниями, чтобы расширить возможности студентов с помощью Statorials. Узнать больше